
Proseguiamo con gli approfondimenti tecnologici di tutte quelle architetture che consentono di disaccoppiare le risorse di compute da quelle di storage in contesti di analytics.
Non è un caso che molte piattaforme di analytics abbiano recentemente deciso di rilasciare modelli di deployment in tal senso: Vertica è una di queste.
Con questo articolo mi propongo di analizzare i cinque vantaggi dell’utilizzo combinato di Vertica in modalità EON con Pure Storage FlashBlade.
Nei paragrafi successivi capiremo il perché di questa intersezione fra il recente modello architetturale di Vertica (modalità EON, appunto) e il nostro storage all-flash scale out ad alte prestazioni per modern analytics (FlashBlade).
Ripercorreremo assieme le motivazioni di un paradigma architetturale di questo tipo e analizzeremo anche quali sono i vantaggi di una “Modern Data Experience”.
I database “colonnari”
Permettetemi una piccola digressione tecnologica. La maggior parte dei database organizzano i dati in tabelle a due dimensioni, righe e colonne, come in questo esempio di catalogazione di libri:

Questo formato bidimensionale è un’astrazione. Nell’implementazione effettiva, la memorizzazione del dato impone che venga serializzato in qualche modo. Un metodo molto comune per archiviare una tabella è scrivere ciascuna riga in questo modo:

Quando i dati vengono inseriti in tabella, viene assegnato loro un identificativo univoco interno (il “rowid”). In questo esempio i record della tabella iniziale hanno rowid sequenziali. In un sistema indicizzato orientato alle righe, la chiave primaria è proprio il rowid dei dati indicizzati.
Per trovare tutti i libri con prezzo compreso tra 15 e 20 euro, il database deve eseguire una scansione completa dell’intera tabella alla ricerca dei record corrispondenti.
Per migliorare le prestazioni di questo tipo di operazioni – che sono molto comuni – la maggior parte dei database offrono l’uso di indici che associano tutti i valori di un insieme di colonne a puntatori rowid riferiti alla tabella originale. Un indice della colonna “prezzo” avrebbe questo formato:

I sistemi tradizionali orientati alle righe sono utilizzati soprattutto quando si devono effettuare velocemente molte transazioni, come scrivere, modificare o eliminare voci.
I sistemi di gestione di basi di dati orientati alle colonne (Column-oriented DBMS) sfruttano invece una ripartizione per colonne. Contrariamente alla variante orientata alle righe, questi database memorizzano i dati come sezioni di colonne invece che righe.
Per la nostra tabella di esempio i dati verrebbero archiviati in questo modo:

Come potete vedere, l’organizzazione è strutturalmente diversa ed è molto più simile ad un indice in un sistema basato su righe. Nel sistema orientato alla colonna, infatti, la chiave primaria sono i dati, che sono mappati sul rowid.
Inoltre, un’unica colonna (prendiamo il campo “formato” del libro) può essere rappresentata aggregando il valore alle chiavi:

Il vantaggio di questo tipo di organizzazione risiede nella possibilità di comprimere il dato. I dati di una colonna sono sempre dello stesso tipo, ad esempio una stringa (sequenza di caratteri) o un integer (numero intero). Poiché tutte le voci di un tipo sono identiche o organizzate in un insieme omogeneo, possono essere compresse (deduplicate) in modo più efficiente.
Un altro vantaggio è che le query massive, specie quelle con funzioni di aggregazione, recuperano i valori da determinate colonne e non da tutta la riga.
Proprio per questo motivo i database colonnari sono sensibilmente più efficienti nella loro applicazione nei Data Warehouse e Business Intelligence e nelle piattaforme di analytics
In sintesi, i benefici dei database orientati alle colonne sono:
- Altissime prestazioni su query con funzioni di aggregazione (come COUNT, SUM, AVG, MIN, MAX)
- Algoritmi di compressione e/o partizionamento dei dati altamente efficienti
La tecnologia di database orientata alle colonne esiste da molti anni e risale al 1969 con una prima implementazione per una applicazione scientifica. Sybase per molti anni è stato l’unico database orientato alle colonne disponibile in
commercio. Il panorama è cambiato rapidamente negli ultimi anni: i principali attori di oggi sono Amazon Redshift, Cassandra, Google BigQuery, greenPlum, SAP HANA, Teradata e Vertica.
Vertica
Vertica ha una origine nobile. Fondata nel 2005 da Michael Stonebraker, è ora parte del portafoglio di soluzioni di Micro Focus.

Per chi non lo conoscesse, Stonebraker, classe 1943, è un ingegnere informatico e ricercatore noto per il suo lavoro nella creazione, sviluppo e perfezionamento di sistemi di gestione di database relazionali (RDBMS) e Data Warehouse, da Ingres a Postgres.
Oggi è codirettore dell’Intel Science and Technology Center for Big Data presso il laboratorio di Computer Science e Artificial Intelligence del MIT. Stonebraker, in virtù della sua ricerca sui database, ha ricevuto il Turing Award nel 2014.
E’ stato Chief Technology Officer di diverse aziende, fra cui: Ingres, Illustra, Informix, Cohera, Required Technology, Streambase e più recentemente Vertica, che ha fondato.
Vertica è un motore di Analytics che fa uso di un database colonnare concepito per gestire grandissimi volumi di dati provenienti da sorgenti diverse. Dispone di algoritmi di machine learing on-board per lo scoring in tempo reale dei modelli in una modalità – chiamata advanced in-database analytics – che consente l’uso degli algoritmi direttamente sul database, senza che ci sia la necessità di esportare più volte i dati in ambienti esterni.
Alcuni clienti di Vertica , come la Divisione Healthcare di Philips, usano la piattaforma per fare estrazioni e analisi per i servizi di maintenance predittiva su apparati medicali complessi, Taboola e CRITEO per velocizzare l’analisi dei dati memorizzati in Hadoop nelle applicazioni di advertising analytics.
Guess lo impiega per capire i gusti dei clienti dai comportamenti e suddividerli in cluster, analogamente a Lastminute per ottimizzare le attività online. Alì Supermercati analizza il mix per la basket analysis; Tesisquare nei servizi di reportistica avanzata e analisi predittiva della catena logistica.
Uber ha fondato la sua strategia di gestione e valorizzazione del dato su Vertica
Altre applicazioni riguardano i campi finanziario e assicurativo (per le valutazioni di rischio e frodi) e l’editoria.
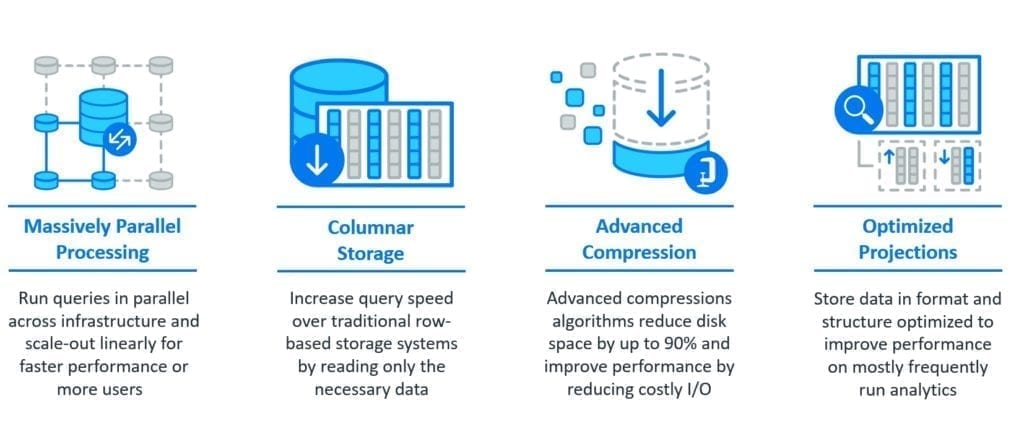
La filosofia di Vertica è di fornire alte prestazioni a basso TCO attraverso quattro principi di design:
- Architettura di massive parallel processing su nodi standard per garantire prestazioni elevatissime e per scalare fino agli Exabyte
- Storage orientato a colonna che garantisce prestazioni di accesso su grandi volumi di dati e performance
- Alta compressione per ridurre i costi di storage e minimizzare le richieste di banda di I/O
- Ottimizzazione nella gestione del dato per favorire le prestazioni di accesso alle analisi più frequenti
Uno sguardo all’architettura di Vertica in modalità EON
A settembre 2019, durante Pure // Accelerate 2019, la conferenza annuale di clienti e partner di Pure Storage, Micro Focus ha annunciato la disponibilità di Vertica in modalità EON per Pure Storage. Si tratta di una architettura che separa il compute dallo storage adatta ad ambienti on-premise.
Vertica in modalità EON per Pure Storage risponde alle esigenze delle aziende di ogni settore di gestire enormi volume di dati eseguendo analisi in tempi molto rapidi, fornendo gestione di elevati volumi di dati, prestazioni elevatissime e facilità operativa.
Questa nuova architettura estende i vantaggi che Vertica offre in termini di prestazioni e gestione dei workload per mezzo di gestione gerarchica delle partizioni, incremento delle performance di query, database resiliency, estendendo al tempo stesso la concorrenza per la crescente community di analisti che si rivolgono a Vertica per ottenere insight dai dati.

Le aziende possono analizzare i propri dati non solo senza doverli più movimentare altrove, ma anche con la capacità di leggere e scrivere in modo rapido e affidabile svariati formati di dati come ORC e Parquet su HDFS, oltre che leggere Parquet su AWS S3.
La modalità EON riguarda una importante modifica dell’architettura fisica di Vertica che permette di cambiare il numero dei nodi su cui gira il motore di analytics in modo indipendente dallo storage.
Per comprendere più in dettaglio cosa cambia a livello architetturale, è utile soffermarsi su come Vertica gestisce i dati, familiarizzando con la terminologia utilizzata per connotare i vari componenti. Diamo dunque un’occhiata più in dettaglio all’architettura logica della modalità EON.
A partire dal più importante, il “communal storage”, ossia il repository comune per tutti i dati che, in modalità EON, può essere implementato su storage S3 e nel nostro caso su FlashBlade.

Seguono gli “shards” ossia i segmenti di dati previsti nel momento della creazione del database e memorizzati nel repository. Il numero di shard è di solito uguale al numero dei nodi presenti nel cluster quando si richiede al database analitico il minimo livello di prestazione. Ogni nodo si prende in carico più shard per essere certi che, in caso di guasto a un nodo, i dati restino disponibili ai nodi rimanenti.

Un altro componente è “depot” (deposito), una cache dati locale a disposizione di ciascun nodo e associata al segmento (shard) su cui il nodo sta lavorando. Il depot è di norma più piccolo del segmento dati, c’è quindi un sistema di caching che si occupa di selezionare e di mantenere localmente i dati più frequentemente utilizzati.
Con la modalità EON tutti i dati vengono direttamente caricati nei Read Optimized Store (ROS) e vengono utilizzati sia a livello del depot sia del repository comune.
E’ possibile aggiungere o togliere dinamicamente nodi al cluster in base alle necessità di lavoro, senza interruzioni per i job in corso ed è anche possibile raggruppare logicamente i diversi carichi di lavoro in sub-cluster.
Isolare i carichi di lavoro consente di dedicare i sub-cluster a diverse attività e di effettuare il provisioning / deprovisioning secondo necessità. È quindi possibile eseguire il provisioning di diversi tipi di nodi in diversi sub-cluster.
I benefici della modalità EON con FlashBlade
A mio modo di vedere esistono almeno cinque benefici che l’accoppiata Vertica in modalità EON e FlashBlade possono garantire. Vediamo ciascuna di queste possibilità:
- scalare in maniera indipendente compute da storage consente di poter ridimensionare dinamicamente ciascuna delle due a seconda delle necessità
- grazie allo storage ad alte prestazioni, incremento di performance a supporto di operazioni massive di analytics in tempo reale
- aggiungere velocemente capacità storage o nodi nel cluster (e rimuoverli) senza interruzione del servizio consente di crescere o decrescere in maniera flessibile
- isolare i carichi di lavoro in base alle esigenze specifiche dello “use case”
- medesimo “stack tecnologico” on-premise e nel cloud
Il beneficio sostanziale della modalità EON rispetto a quella Enterprise è il supporto per l’Elastic Throughput Scaling che permette di aggiungere e di rimuovere velocemente nodi nel cluster.
In questo modo diventa possibile rispondere a esigenze di prestazione nell’esecuzione delle query variando il numero dei nodi presenti nel cluster, con una dinamicità che prima era impossibile.
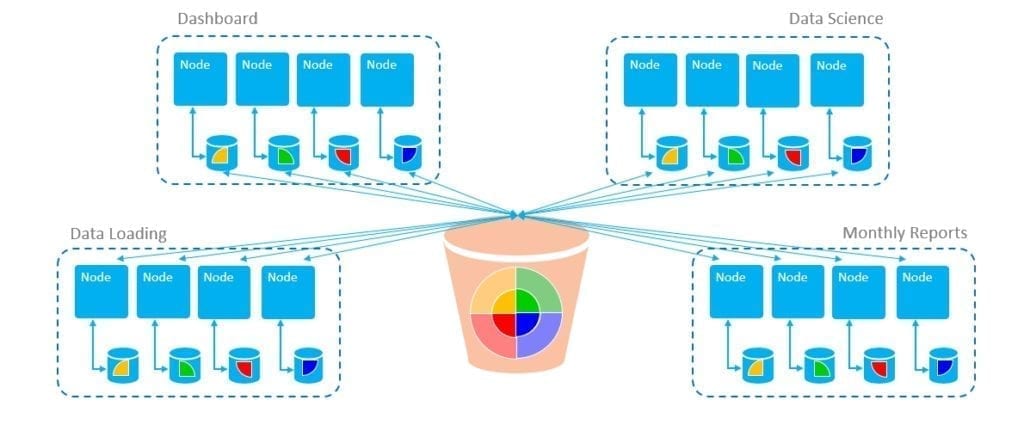
Inoltre, la separazione fra i nodi di compute e lo storage centralizzato permette di poter scalare in maniera indipendente l’uno dall’altro.
La separazione delle attività computazionali dallo storage aiuta a gestire carichi di lavoro più dinamici e consente l’isolamento dei carichi di lavoro per singoli team e progetti; fino ad ora queste funzionalità sono state in gran parte limitate al cloud, EON per Pure Storage risponde a queste necessità portando tutti i vantaggi del cloud on premise.
Grazie al nuovo meccanismo di caching intelligente, la separazione tra elaborazione e storage avviene in maniera più efficiente, senza compromessi per attività complesse come analisi su serie temporali, geospaziali, pattern matching e machine learning.
La modalità EON comprende le funzioni per ottimizzare i costi d’utilizzo dei servizi cloud, riducendo al minimo le chiamate API a S3 e migliorando i caricamenti dei dati. Come per i depot, anche il catalogo (i metadati che descrivono gli oggetti nel database) risiede, sia sui nodi, sia su FlashBlade S3, grazie alle specifiche funzioni di sincronizzazione.
La capacità di allocare in modo dinamico le risorse aiuta in particolar modo le aziende che hanno carichi analitici variabili, semplificando gli oneri d’amministrazione.
Conclusioni
Le architetture di cloud pubblico offrono valore a molte organizzazioni, ma molte aziende hanno bisogno degli stessi vantaggi nelle implementazioni on-premise o ibride. Con Vertica in modalità EON per Pure Storage, le aziende possono sfruttare l’architettura cloud se scelgono ambienti ibridi oppure restare in modalità on-premise.
L’utilizzo di Vertica con FlashBlade rende possibile gestire grandi volumi di dati abbassando i costi infrastrutturali, grazie alla capacità di attivare le risorse quando è necessario e spegnerle quando non servono più.
Vi invito ad approfondire ulteriormente, con questo video o questo white paper, il funzionamento di Vertica in modalità EON con FlashBlade.
Contattatemi per ulteriori informazioni, sarò felice di aiutarvi.
Luca Rossetti Systems Engineer
T @lucaR055



