
Oggi le architetture di analytics poggiano su infrastrutture eterogenee e tecnologie differenti, rispondono a esigenze diverse e trattano dati con modalità talvolta discordanti.
Ne ho parlato nel mio post precedente in cui ho ripercorso le tappe fondamentali del cambiamento a cui abbiamo assistito nel mondo della gestione e della valorizzazione del dato, trasformazione che ha portato alla sedimentazione e convivenza di silo di dati completamente separati fra di loro.
Con questo post, invece, mi propongo di esplorare la visione di Pure sul “Data Hub”, piattaforma storage progettata da zero da Pure per accelerare la condivisione dei dati, abbattendo i tradizionali silo che si sono stratificati nel tempo.
Quando parliamo di Data Warehousing e di Big Data Analytics, il modo con cui i dati vengono raccolti e trasformati, conservati e valorizzati presuppongono capacità infrastrutturali che sono fra loro molto diverse se non addirittura antitetiche.
Con riferimento alla figura sotto, proviamo ad analizzare queste caratteristiche una ad una.
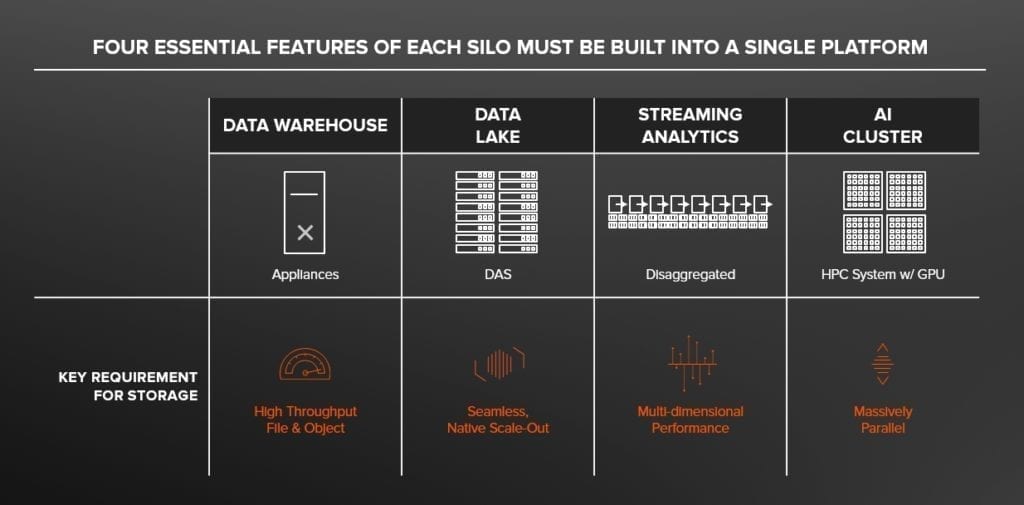
- Un Data Warehouse molto spesso è costruito su appliance o sistemi ingegnerizzati e richiede un throughput massivo, in particolare per le letture. In generale c’è un forte accoppiamento fra le risorse di compute e quelle di storage.
- Un Data Lake è costruito su cluster di server economici e consente di scalare in maniera dinamica attraverso un bilanciamento software. Scalare significa aggiungere fisicamente delle risorse al cluster senza downtime. Il Data Lake archivia dati non strutturati nella loro forma grezza. È ottimizzato per carichi di lavoro sequenziali di grandi dimensioni in flussi di lavoro batch, ma non per altre tipologie di carichi di lavoro come il real time. L’infrastruttura è in genere costruita su un’architettura DAS (Direct-Attached Storage), il che significa che il sistema non è creato per far girare macchine virtuali e container. In questo mondo, i dati sono fisicamente legati alle risorse di compute e ciò rende estremamente difficile l’utilizzo di container.
- I cluster di Streaming analytics richiedono che tutte le risorse, in particolare lo storage, siano in grado di fornire prestazioni “adattive” per consentire di processare il dato indipendentemente dalle dimensioni (molto piccoli o di molto grandi) o dalla tipologia di I/O (random o sequenziale).
- I cluster di AI, costruiti su decine o centinaia di GPU, richiedono che lo storage abbia performance massivamente parallele per gestire migliaia di client e potenzialmente decine di milioni di oggetti o file
Il Data Hub
La promessa del “Data Hub”, sostanziato dal punto di vista tecnologico attraverso la tecnologia FlashBlade, è di consolidare tutti questi silo in un’unica infrastruttura storage in grado di gestire tutte le applicazioni che fanno un uso intensivo dei dati.

Il concetto e l’implementazione del Data Hub prevede uno storage centrale che è in grado di:
- Condividere il dato: i dati devono essere accessibili da qualsiasi risorsa, sia che si tratti di macchine virtuali o container
- Gestire qualsiasi tipo di dato, perché i dati non strutturati non sono prevedibili a priori: possiamo avere file di piccole dimensioni o di grossi volumi con pattern di accesso random o sequenziali, real time o batch.
- Scalare in maniera orizzontale: il dato, per sua natura, non è statico ma cresce. Il Data Hub è in grado di scalare dinamicamente per rispondere a qualsiasi esigenza di calcolo.
Poiché fisicamente FlashBlade è organizzato per blade ed ogni singola “lama” può essere aggiunta a caldo, è possibile scalare fino a diversi petabyte in maniera molto semplice.
Molte organizzazioni usano FlashBlade come infrastruttura per i propri progetti di analytics e AI. Vi invito a leggere le loro storie a questo link.
Proviamo ora ad analizzare in maniera più approfondita il funzionamento di FlashBlade, in particolare ci soffermiamo sulle capacità che sono state introdotte nel software di gestione dello storage: Purity //FB
La gestione in un’unica piattaforma di file e oggetti (S3)
Innanzitutto il Data Hub fornisce un throughput elevato nella gestione di file e oggetti, su un’unica piattaforma.
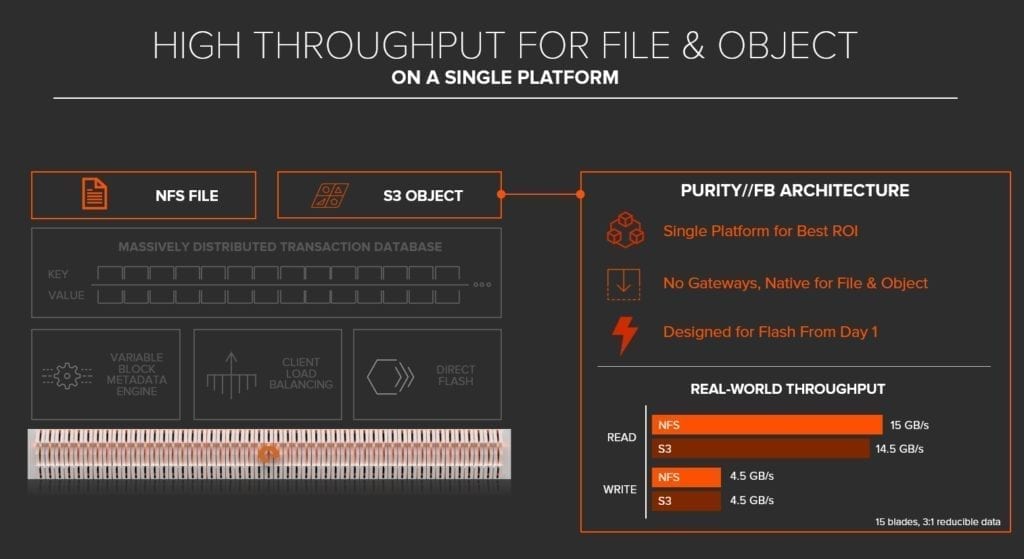
Purity // FB dispone di un supporto nativo per file e oggetti. Da un punto di vista tecnologico:
- è una piattaforma unica per il supporto del protocollo di file e oggetti, contrariamente ad altre tecnologie, elimina la necessità di sistemi separati che spesso porta all’ over-provisioning di capacity da parte clienti.
- nessun gateway. L’approccio legacy di altri vendor generalmente prevede dei gateway che stratificano protocolli aggiuntivi. I sistemi potrebbero essere stati costruiti originariamente per gestire le strutture file, e in seguito modificati per aggiungere il protocollo ad oggetti. In Purity //FB, i protocolli per file e oggetti sono costruiti da zero, in modo nativo per supportare il livello di prestazioni che è in grado di erogare.
- è progettato per supporti Flash fin dal giorno 1. La maggior parte dei software per scale-out usano un’implementazione vecchia di decenni costruita originariamente per i dischi rotativi. Purity //FB è un software moderno di archiviazione, realizzato da zero per storage all-flash.
Ad oggi non esiste un sistema di storage che tratti file e oggetti sullo stesso piano e in un’unica piattaforma. Tuttavia, come si può vedere nei risultati del benchmark, sia per le prestazioni in lettura che in scrittura, c’è poca differenza se il protocollo è file o oggetti. In altre parole, si ottengono le migliori prestazioni indipendentemente dal protocollo che si desidera usare.
Vera scalabilità orizzontale
La seconda caratteristica del data-hub è di avere una architettura nativa di scale-out.

Scale-out o scalabilità orizzontale significa la possibilità di aggiungere un nuovo nodo ad un sistema: aumentare non solo lo spazio complessivo, ma anche le prestazioni usufruendo della potenza di calcolo che ogni nodo aggiunge al sistema. Inoltre, un eventuale problema a un singolo nodo non porta ad un blocco dell’intero sistema, dato che i nodi sopravvissuti possiedono copie dei dati e possono erogarli ai server al posto del nodo bloccato.
Purity // FB è costruito in modo univoco su un database di coppie chiave-valore ampiamente distribuito. Questa architettura moderna è al centro di FlashBlade ed è ciò che consente di scalare senza limiti. Tre caratteristiche architetturali chiave abbiamo infatti:
- Distribuisce tutto. I sistemi legacy utilizzano federazione di nodi, pool, coppie, cache e metadata server. Purity // FB è scale-out nel suo core, offrendo semplicità senza compromessi
- Ha funzionalità di self-healing e self-tuning dinamiche, al fine di fornire prestazioni e resilienza mentre i sistemi legacy richiedono un costante retuning per le prestazioni. Con la resilienza N + 2, FlashBlade continuerà a funzionare mentre il sistema si cura in caso di guasto in qualsiasi risorsa.
- Ha un database core unificato. Purity // FB è costruito su una tecnologia moderna di database di metadati distribuiti, eliminando gli hotspot di prestazioni che si trovano nei sistemi legacy. Non ha limiti nel numero di oggetti.
Le architetture di calcolo distribuita sono una delle aree di ricerca più impegnative nel campo dell’informatica. La capacità di fornire scala lineare è estremamente difficile. Ma Purity // FB è in grado di crescere linearmente man mano che si aggiungono più risorse, da 15 blade fino a 75 blade, da 15 GB/s prestazioni di lettura a 75 GB/s
La garanzia di prestazioni adattive
La terza funzione essenziale in un data hub è di fornire prestazioni adattive.

I dati non strutturati sono dati imprevedibili. I dati arrivano in tutte le forme e dimensioni e sono accessibili in modi non prevedibili a priori. E questo, oggi, rappresenta una sfida significativa per le piattaforme di storage. Tuttavia, con il motore di metadata a blocchi variabili e il bilanciamento del carico, Purity // FB è progettato per fornire questa funzionalità estremamente importante.
Ecco le tre qualità che consentono a Purity // FB di offrire prestazioni multidimensionali.
- Dimensione variabile del blocco. I software meno recenti utilizzano dimensioni di blocco fisse, lasciando molta efficienza sul tavolo. Purity // FB adatta le dimensioni del blocco a ciascun oggetto per massimizzare l’efficienza e la capacità.
- Architettura messa a punto per tutti i tipi di carico. Le soluzioni esistenti spesso ottimizzano per un sottoinsieme di I / O, come i file sequenziali di grandi dimensioni. Purity // FB è progettato in modo nativo per fornire prestazioni per tutti i dati.
- Architettura che distribuisce client e dati su TUTTE le risorse. Nessuna risorsa, nessun percorso dati, nessun server metadati è mai il collo di bottiglia.
Per guardare un singolo punto di vista, la tecnologia a blocchi variabili offre un’enorme efficienza.
Confrontiamo con un sistema legacy di scale-out che ha una dimensione di blocco fissa. Se abbiamo tantissimi file da 1KB e la dimensione fissa del blocco è 4KB abbiamo un’inefficienza di 3KB per ciascun file. Con FlashBlade la sua tecnologia a blocchi variabili memorizzerà esattamente 1 KB.
Nel grafico un esempio di come aumenta la capacità in termini di multipli al diminuire della dimensione del singolo file o oggetto.
Massivamente parallelo
Infine, la quarta caratteristica essenziale in un hub di dati è di essere massivamente parallelo.
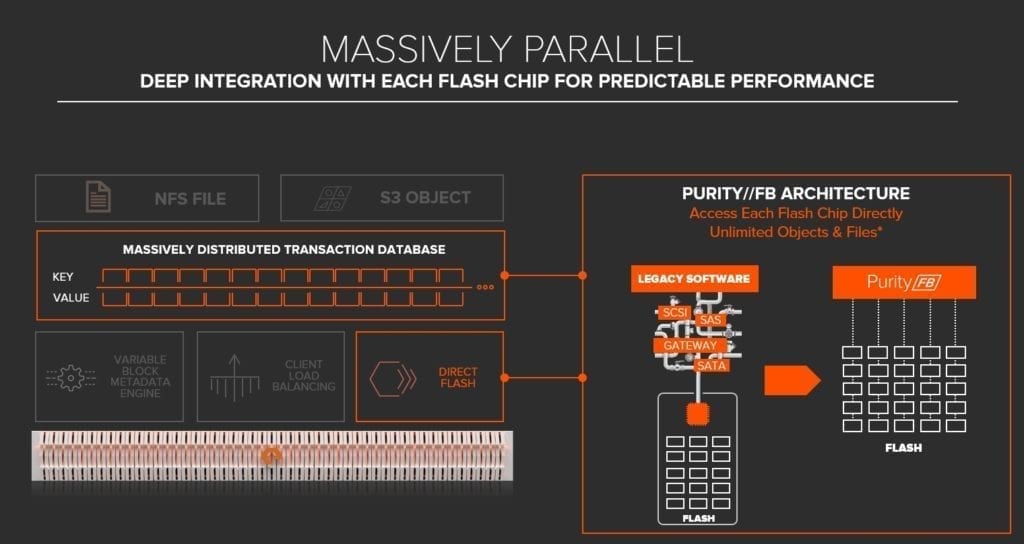
Non viviamo più in un mondo seriale. Viviamo in un mondo parallelo, e l’intelligenza artificiale si fonda su meccanismi di elaborazione parallela.
Il software di archiviazione legacy è stato tradizionalmente costruito nel corso di molti anni, su protocolli seriali e dischi meccanici. Strati di gateway e inefficienze sono stati aggiunti per supportare gli SSD. I dati vengono inviati attraverso un canale molto sottile.
Purity // FB è progettato da zero per il flash, con un’architettura di metadati scalabile in grado di gestire miliardi di file e oggetti offrendo prestazioni senza precedenti. Il software parla con ogni chip flash, utilizzando un percorso di dati estremamente parallelo per accelerare l’accesso ai dati per le applicazioni odierne a uso intensivo di dati. Niente più protocolli seriali.
I benefici di FlashBlade
Ci sono diversi benefici dall’utilizzo di una architettura di Data Hub come quella di FlashBlade.

Li analizzerò in un post successivo ma ci terrei a sottolineare uno dei più importanti: la possibilità di far crescere in maniera indipendente le risorse di compute da quelle di storage, elemento che dà una estrema flessibilità, specie nelle infrastrutture moderne di analytics.
Vi invito a scaricare il datasheet su FlashBlade e ad approfondirne la conoscenza sulla pagina principale.
Contattatemi per ulteriori informazioni, sarò felice di aiutarvi.
Luca Rossetti, Systems Engineer
T @lucaR055



