
Il mondo della gestione e della valorizzazione del dato è decisamente evoluto nel tempo. In particolare, nell’ultimo decennio abbiamo vissuto un drastico cambiamento sia nella tipologia di strumenti e piattaforme per gestire e analizzare i dati sia nella natura stessa dei dati.
Con questo primo post mi propongo di ripercorrere le tappe fondamentali di questo cambiamento e di descrivere le architetture e le complessità affrontate in ciascun periodo storico con un approfondimento specifico sulle sfide dell’analisi dei dati nel mondo odierno. Nel secondo post di questa serie vorrei presentare la visione di Pure sul “Data Hub” progettato da zero per risolvere le sfide che le architetture moderne di analytics pongono.
Agli albori della gestione dei dati

A partire dagli anni 60 e 70, le aziende hanno iniziato a digitalizzare i loro processi di pari passo con l’adozione di nuovi strumenti tecnologici attraverso sistemi transazionali e database strutturati.
I sistemi transazionali sono sistemi informatici che eseguono operazioni online su basi di dati, sono utilizzati contemporaneamente da più utenti che vi accedono attraverso delle procedure predefinite. Il loro compito è prevalentemente quello di visualizzare, inserire, aggiornare, eliminare e memorizzare record all’interno di un database, gestendo la concorrenza dell’accesso al dato da parte di più utenti e garantendo la persistenza dell’informazione.
Uno dei primi sistemi transazionali è stato il sistema di prenotazione di biglietti aerei.
Sembrerà strano agli occhi di chi oggi è abituato a gestire tutto autonomamente dal proprio smartphone, ma all’epoca l’esigenza era quella di consentire ad un numero elevato di agenzie sparse in tutto il territorio americano di effettuare la prenotazione e la vendita di biglietti aerei, gestendo la coerenza di tutte le informazioni.
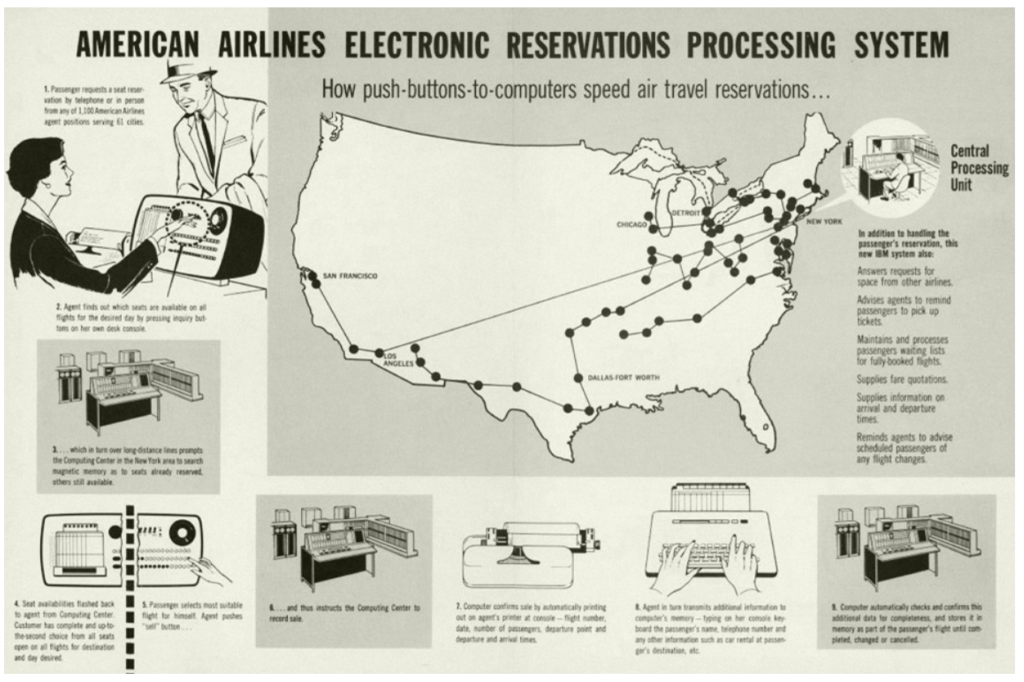
In altre parole – e semplificando – un biglietto già venduto doveva essere associato ad un solo passeggero e il posto già prenotato non poteva essere più disponibile per la vendita.
Questo avveniva su calcolatori centrali Mainframe in grandi centri di elaborazione dati
Negli anni 80
A partire dagli anni ’80 con l’affermazione dei sistemi distribuiti e dei database relazionali Oracle e SQL Server (Microsoft) e di altri vendor, assistiamo al consolidamento dei sistemi transazionali come l’infrastruttura fondante della gestione dei dati mission-critical per i processi di business.
Report di dettaglio o di analisi e sintesi vengono creati interrogando direttamente lo stesso database transazionale, insistendo sulle stesse risorse computazionali.
Da notare che parliamo di dati generati all’interno del perimetro aziendale per uso e consumo del business dell’organizzazione che li tratta. I dati sono “strutturati” ovvero sono organizzati in uno schema tabellare come righe in una tabella, con un insieme di regole sintattiche e una struttura comune.
Con la maggiore specializzazione dei sistemi transazionali per divisioni di business e la crescita del volume dei dati generati, aumenta anche il fabbisogno informativo e la necessità di integrare fra loro i dati per migliorare la capacità di analisi e conseguente decisione.
Per fare un semplice esempio: nel settore manufatturiero diventa sempre più importante mettere in relazione i dati generati dai sistemi di vendita con quelli di gestione della logistica o di pianificazione della produzione: conoscendo cosa e quanto i miei clienti hanno ordinato, posso progettare opportunamente le fasi di produzione industriale, conoscere il fabbisogno di materia prima e definire una corretta distribuzione sul territorio del prodotto finito.
Diventa sempre più difficile eseguire report sui singoli silos e interpretare questi dati in maniera integrata per tutta l’azienda, poiché i dati sono via via ospitati in database diversi senza essere integrati fra di loro.
I primi Data Warehouse
Per rispondere a questa esigenza nascono i primi Sistemi di Supporto alle Decisioni (DSS – Decision Support System) precursori dei successivi “Enterprise Data Warehouse”, che dagli anni ’90 rappresentano il cuore della analisi dei dati di Business di una organizzazione.
I Data Warehouse sono contenitori di dati opportunamente progettati per raccogliere, interrogare e interpretare i dati in maniera strutturata, coerente e integrata. Estraggono, caricano e storicizzano dati dai sistemi transazionali: integrano, omogeneizzandoli, dati provenienti da fonti alimentanti differenti e storicizzano i dati.
Questo consente di adottare metodologie di analisi sempre più complesse e interessanti, come ad esempio mettere in relazione lo stesso indicatore di business al passare del tempo o nella geografia o altra dimensione d’analisi. Ad esempio, con un Data Warehouse opportunamente progettato è possibile visualizzare e navigare una dashboard di sintesi che metta a confronto il valore delle vendite del primo quarter dello scorso anno con quelle del primo quarter di quest’anno fiscale, ulteriormente analizzate per la geografia EMEA e APAC.
Normalmente la modalità di alimentazione di un Data Warehouse è di tipo batch: nelle finestre temporali di basso utilizzo dei sistemi alimentanti, tipicamente in orario notturno i dati vengono “fotografati” ad un istante ben preciso, estratti e caricati in modalità batch e massiva sul Data Warehouse.
L’implementazione dei sistemi di Data Warehousing varia a seconda del business e dell’azienda, ma questa è di fatto l’architettura di riferimento dei moderni sistemi d’analisi dei dati aziendali.

La centralizzazione del dato porta con sé anche l’esigenza esattamente contraria, cioè la necessità di specializzare le analisi e dare maggiore flessibilità di indagine al singolo dipartimento aziendale.
I Data Mart hanno risolto in parte questo problema, utilizzando la stessa tecnologia di base di un Data Warehouse, ma fornendo visualizzazioni e trasformazioni dei dati specifici per particolari analisi dipartimentali.
Normalmente il Data Mart si colloca a valle di un Data Warehouse ed è alimentato a partire da esso, di cui costituisce, in pratica, un estratto tematico: detto in termini più tecnici, un Data Mart è un sottoinsieme logico o fisico di un Data Warehouse di maggiori dimensioni.
La necessità di creare un sistema separato per il Data Mart rispetto al Data Warehouse generalmente migliora le performance separando l’hardware dedicato e garantisce una maggiore sicurezza dovendo autorizzare l’accesso ad un insieme minore di dati.
Data Warehouse e Data Mart sono generalmente creati per venire incontro ad un’esigenza specifica e già determinata. In altre parole: la selezione e la proiezione del dato, così come la sua organizzazione logica sono definite a priori per rispondere a un insieme finito di domande che, sulla base di andamenti passati, consentono di formulare strategie d’azione per il futuro.
La nascita del Data Lake
La sfida odierna è la crescita di tutte le sorgenti di informazione e il volume di dati provenienti da sistemi esterni al perimetro dei sistemi aziendali. Generalmente si tratta di dati “non strutturati”, non appartengono né a un database specifico né a un particolare modello predefinito di classificazione formale.
Per citare qualche esempio: abbiamo macchine industriali connesse che inviano dati di diagnostica in streaming (IoT), raccogliamo di continuo log sulla sicurezza di web server o firewall, raccogliamo tweet e like per valutare l’apprezzamento di un prodotto o fare sentiment analysis, raccogliamo tantissime informazioni sulla interazione che abbiamo con i nostri clienti tramite tutti i punti di contatto (contact center, web, app, negozi fisici).
In generale vorremmo gestire contemporaneamente sia dati non strutturati – come quelli citati prima – ma anche dati semi strutturati – ad esempio un atto notarile con frasi fisse e frasi variabili – oltre a quelli strutturati e tradizionali dei sistemi transazionali.
Anche il modo in cui vogliamo analizzare i dati si è trasformato. Vogliamo accesso immediato alle informazioni, con analisi complete e approfondite che utilizzano sia regole elaborate sia strumenti basati su Machine Learning.
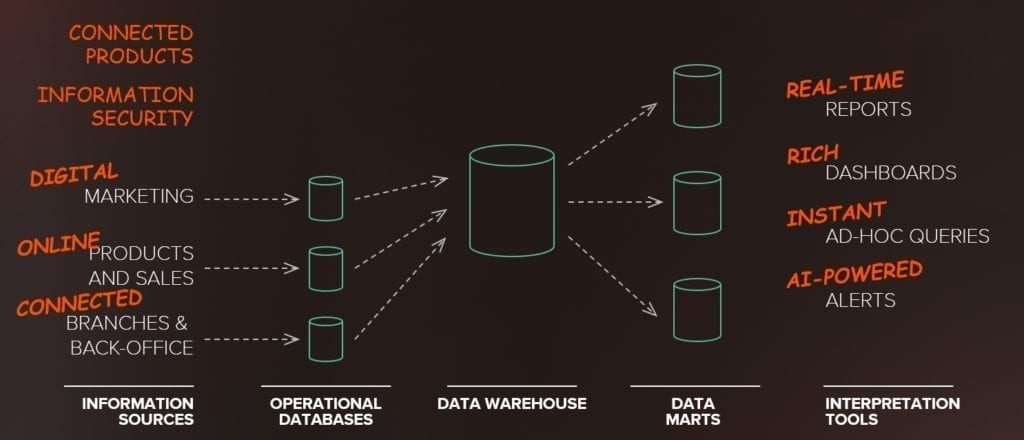
Ma cosa succede se proviamo a inserire tutti questi dati nel Data Warehouse o nei nostri Data Store Operativi?
Carichi di lavoro fatti di grandi volumi di dati eterogenei che arrivano ad alta frequenza e velocità impediscono a questi sistemi di scalare e di essere gestiti in maniera efficiente.
Raccogliere e archiviare dati non strutturati in modo sicuro e soprattutto esplorarli e visualizzarli in modo comprensibile per trarne informazioni utili, sono attività che richiedono tecnologie differenti da quelle dei Data Warehouse e strumenti software adeguati. Si tratta di tecnologie che siano in grado di gestire il volume, la velocità e la varietà di questi dati così differenti fra di loro.
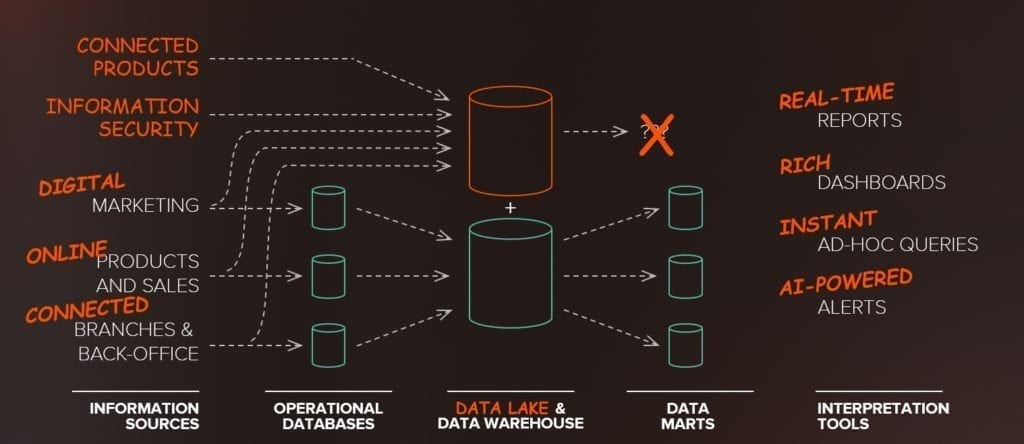
Circa 15 anni fa, sono nate le prime tecnologie deputate alla gestione di dati semi-strutturati e non strutturati. Sono nati i primi “Data Lake”, insiemi di dati grezzi, strutturati e non strutturati, trasferiti a sistemi di archiviazione locale o remota attraverso mezzi di trasmissione ad alta velocità.
Il Data Lake è quindi stato affiancato al Data Warehouse tradizionale, aggiungendo un silo di informazioni tematiche differenti, raccolte con modalità e architetture diverse.
Contrariamente ai Data Warehouse, le interrogazioni possibili su un Data Lake non sono necessariamente definite a priori e l’organizzazione dei dati non è progettata ex-ante per rispondere a un insieme finito di domande.
Le sfide odierne delle architetture ibride a silos
Interrogare Terabyte, se non Petabyte, di dati su un Data Lake è una operazione particolarmente onerosa. In un Data Lake vengono normalmente eseguite operazioni di precompilazione e “pulizia” per filtrare i dati da informazioni ridondanti, inaccurate o incomplete. Questo serve sia a migliorare l’accuratezza delle analisi sia a ridurre lo spazio necessario alla memorizzazione dei dati.
Inoltre, per supportare query più veloci, vengono costruite visualizzazioni pre-renderizzate o “memorizzate in cache” dei dati che affiancano il Data Lake. Queste sono essenzialmente il logico successore logico dei Data Mart.
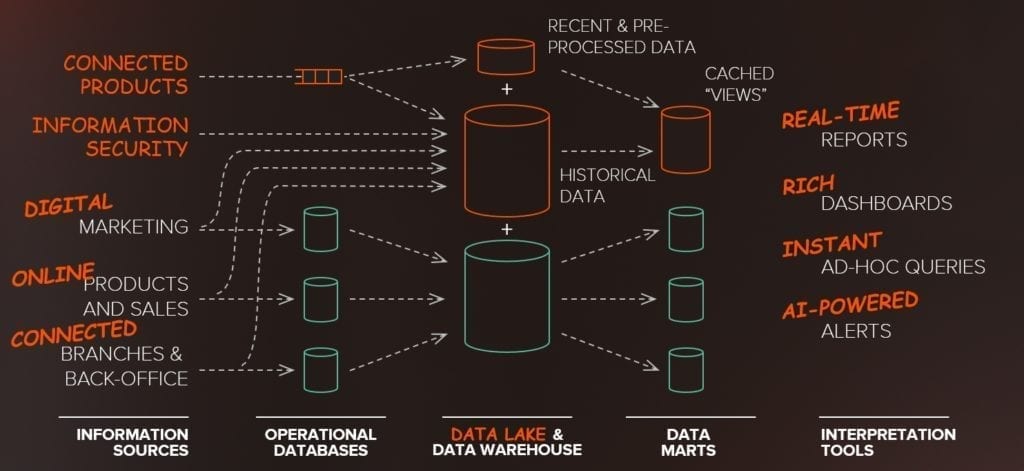
Queste viste sono necessarie per memorizzare solo una porzione dei dati effettivamente presenti nel Data Lake come ad esempio l’ultimo giorno di dati e per fare in modo che le query e la visualizzazione vengano eseguite istantaneamente.
Combinando questi dati con le visualizzazioni memorizzate nella cache dei nostri dati storici, possiamo ottenere analisi interattive dei dati raccolti.
L’architettura ibrida che si viene a creare è fatta di tecnologie differenti che raccolgono dati con modalità di trattamento (raccolta, conservazione, interrogazione) completamente diversi fra di loro. Anche l’infrastruttura su cui poggiano è eterogenea.
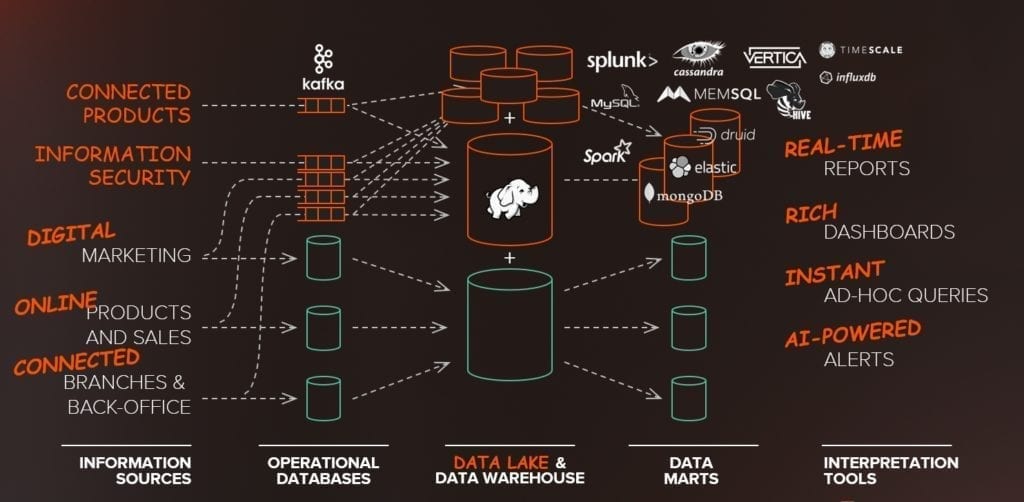
Sul versante di chi analizza i dati abbiamo consumatori con caratteristiche totalmente differenti.
Le casistiche potrebbero essere molte di più ma solo in via esemplificativa vorrei citare: utenti con la necessità di fare ricerche in modalità “full-text” per cui avremo bisogno di costruire indicizzazioni sul testo, in altri casi avremo utenti che hanno necessità di fare analisi di Business Intelligence su cubi “OLAP”, altri avranno la necessità di costruire logiche applicative su un backend NoQSL, in altri casi ancora i dati saranno analizzati da procedure automatiche alla ricerca di deviazioni da comportamenti standard.
Anche le infrastrutture su cui poggiano i dati e relative analisi sono frammentate su silos architetturali e fisici differenti.
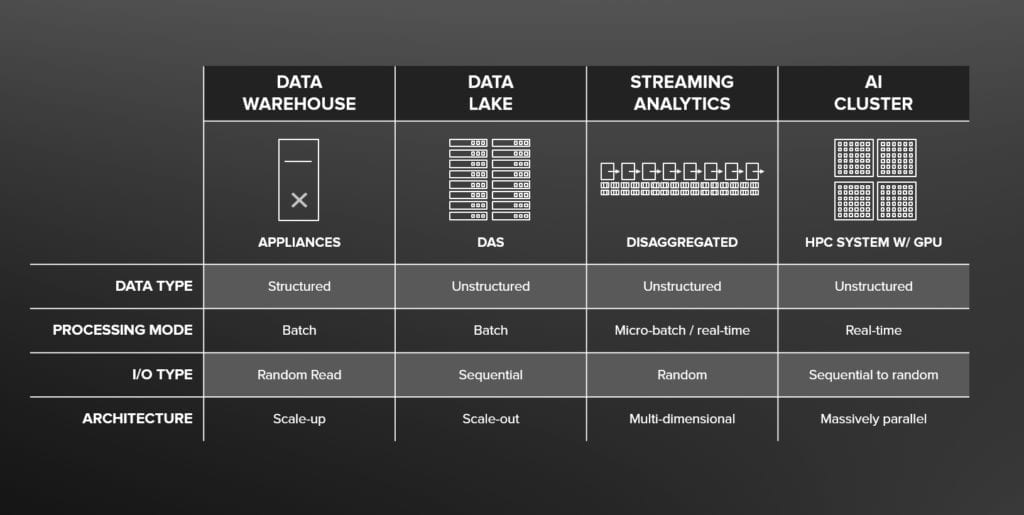
Ogni silo risponde ad esigenze del suo ambito particolare.
I Data Warehouse vengono spesso implementati su appliance o sistemi ingegnerizzati. Si tratta di un’infrastruttura costruita per dati strutturati e raggruppati ed è di tipo “scale-up”.
I Data Lake poggiano su architetture distribuite con computing aggregato allo storage in modalità “Direct Attached” (DAS), non si può parlare di scale-up ma è completamente l’opposto. Si tratta di architetture scale-out costruite per garantire performance nel trattamento di dati non strutturati in cui lo storage è collegato direttamente a un server (o cluster) senza una rete a fare da tramite.
Streaming Analytics riguarda l’elasticità e la capacità di far girare le applicazioni e utilizzare le risorse secondo necessità spesso crescenti. Si tratta di disaggregare computing da storage. È l’esatto opposto del DAS, dove applicazione + compute + storage sono fisicamente legati l’uno all’altro. Nell’analisi in streaming, l’applicazione, il calcolo e i dati sono separati attraverso Containers o Virtual Machine.
Poi abbiamo i cluster di AI. Originariamente provenienti dall’industria dell’ High Performance Computing (HPC) dove i sistemi di elaborazione sono in grado di fornire delle prestazioni molto elevate, ricorrendo tipicamente al calcolo parallelo con processori GPU e migliaia di core.
Alla fine, ciascuno di questi silos è completamente diverso l’uno dall’altro, con architetture molto differenti. Eppure nel mondo di oggi il dato deve essere messo al centro e condiviso, deve essere reso disponibile affinché possa essere usato da più divisioni aziendali e da più processi. Il valore del dato sta soprattutto nella capacità di essere condiviso e interpretato da più attori allo stesso modo. E questi silos non sono funzionali alla condivisione.
Quindi la domanda è: perché è così difficile avere una piattaforma unificata che condivida queste tipologie differenti di dati? Esiste una infrastruttura dati che sia in grado di condividere allo stesso modo dati strutturati e dati non strutturati? Che possa gestire movimentazione di dati sia in real-time sia batch?
A questa e ad altre domande risponderemo nel secondo post della serie in cui parleremo del “Data Hub” e della visione di Pure sulla condivisione del dato e di come i principi di design dello storage all-flash ad alte prestazioni e scale-out FlashBlade, rispondano alle esigenze di gestione moderna del dato.
Contattatemi per ulteriori informazioni, sarò felice di aiutarvi.
Luca Rossetti Systems Engineer
T @lucaR055



