
前回の第 4 回では、ホストが ActiveCluster にアクセスした時の挙動についてご紹介しました。今回は、ActiveCluster 環境で障害が発生した時の挙動と、そこから復旧した時の挙動をご紹介します。
ActiveCluster の障害時の挙動
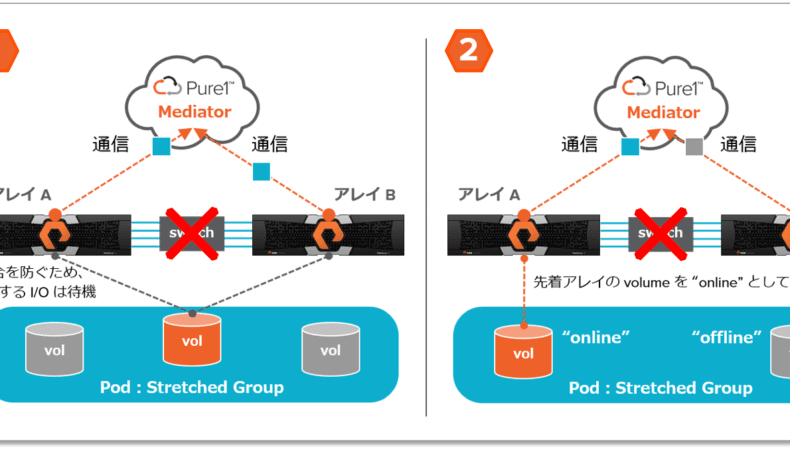
まずは、ActiveCluster の障害時の挙動です。どちらか一方のアレイまたはインターコネクト(レプリケーションネットワーク)で障害が発生した場合は、一定時間の経過後に、各アレイは Mediator との通信を開始し、どちらのアレイを正(オンライン)としてサービスを継続するか判断します。ActiveCluster では、この仕組みを「Mediator レース」と言います。Mediator レースの結果、先に通信が成立したアレイをオンライン、後から通信が成立した、または通信が成立しなかったアレイをオフラインとします。また、Mediator レースはアレイ単位ではなく、Pod 単位で行われます。そのため、Mediator レースの結果は別 Pod や Pod 外のローカルなボリュームに全く影響しません。

Mediator は、障害時のアレイからの通信を待つだけです。Mediator 自身は、アレイを監視したり、スプリットブレイン時にオンラインとするアレイを判断したりしません。Mediator との通信や、スプリットブレイン時にオンラインとするアレイの判断は、あくまでもアレイ自身に委ねられます。Mediator は「パッシブ(passive)」という種類の仕組みであるため、ActiveCluster 構成であっても、通常のシングル構成と比較した運用監視の追加工数が最小化されます。特に、Pure1 Cloud Mediator(CloudAssist 上のMediator)選択時は、Mediator 自身の構築、運用、可用性の担保の全てがピュア・ストレージの CloudAssist で行われます。On-Premises Mediator(vSphere 上の Mediator VM)選択時は、その VM は vSphere HA 等で Mediator の可用性を担保することが強く推奨されています。
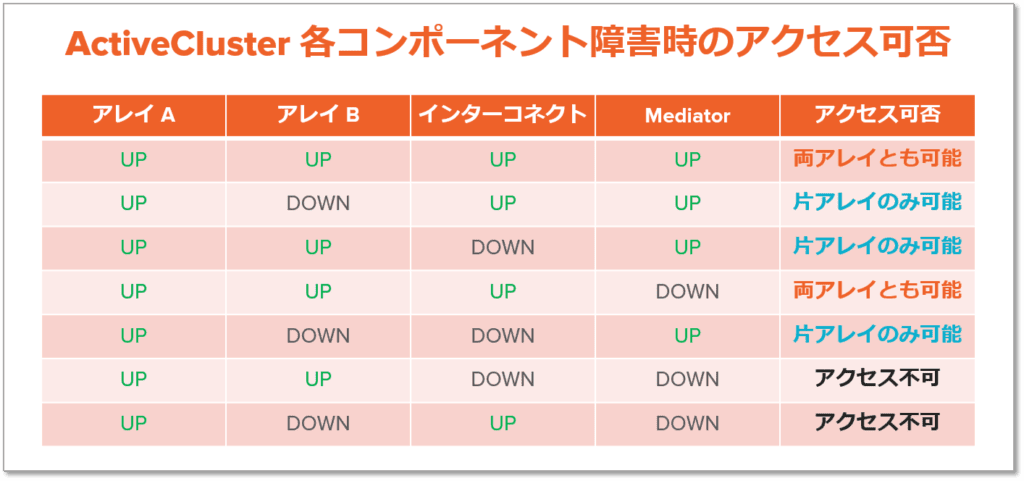
ActiveCluster の各コンポーネントの障害時における、ホストからのアクセス可否を以下に示します。
ActiveCluster の復旧時の挙動
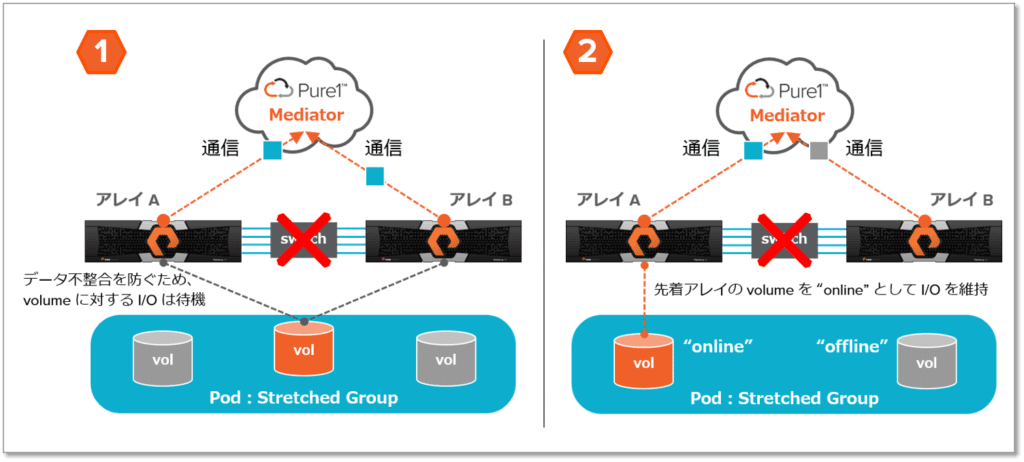
次に、ActiveCluster の復旧時の挙動です。ActiveCluster のシンプルさは復旧時も同様で、アレイが復旧を検知すると全自動でアクティブ/アクティブの構成までリカバリします。ストレージ管理者による GUI/CLI によるオペレーションは一切不要です。復旧を検知した時点では、両アレイ間でデータの差分が発生している状態です。差分を解消してデータを完全に同期させるために、オンラインのアレイからオフラインのアレイに非同期レプリケーションを実行し、差分の解消を開始します。この非同期レプリケーションの実行中に、いくつかのチェックポイントを作ります(下図の snap)。そして、最後のチェックポイントにおける差分データをオフラインのアレイに適用開始すると同時に、リアルタイムでホストから要求されている書き込みも開始します。そして、全ての差分データを適用し終えたタイミングで、オフラインのアレイはオンラインとなり、ActiveCluster 構成にリカバリされます。驚くべきは、全て全自動でリカバリが行われる点です。その間、非同期レプリケーションから ActiveCluster に移行するタイミングであっても、I/O 待機すらありません。

検証結果
ActiveCluster に負荷生成ツール「vdbench」を使用して 10 万 IOPs の I/O ワークロードを生成し、障害から復旧までを検証した結果を以下に示します。
 |
|
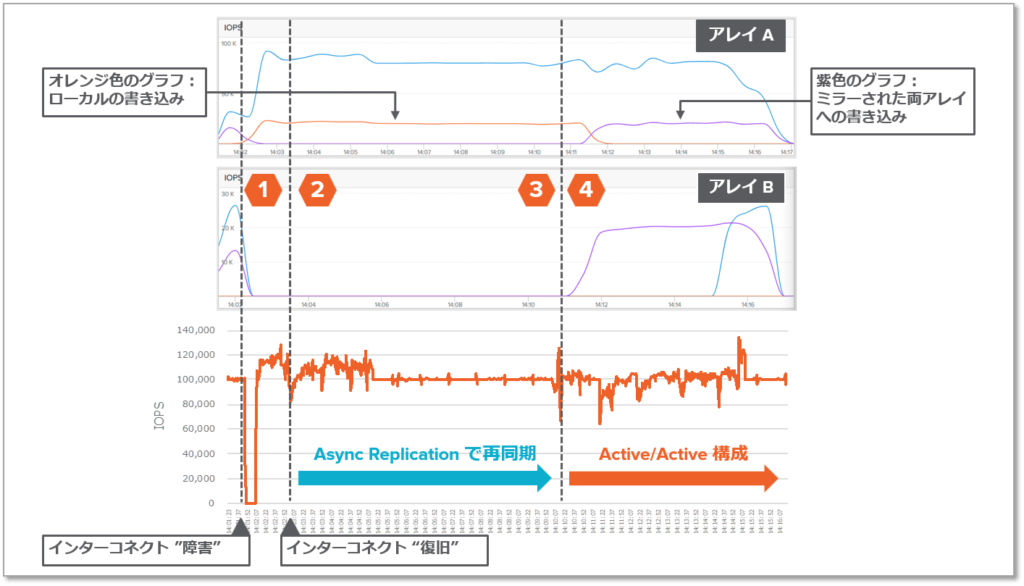
- 図中の1つ目の破線でインターコネクト障害を発生させました(レプリケーション用ポートを全て抜線)。アレイが障害を検知すると一定時間の経過後、Mediator レースを開始します。その結果、今回はアレイAの通信が先に成立したため、アレイAをオンライン、アレイBをオフラインとし、片アレイでサービスを継続しました。
- 2つ目の破線でインターコネクトを復旧しました。復旧を検知すると、自動的にアレイ間のデータの再同期を開始します。その間は引き続きアレイAのみがオンラインです。その間(1~3)の性能情報グラフはアレイAのみ表示されていることから、それがわかります。
- 3つ目の破線の時点で、最後のチェックポイントによる差分データをオフラインのアレイ(アレイB)に適用を開始すると同時に、リアルタイムでホストから要求されている書き込みも適用し始めました。
- 4つ目の破線で、全ての差分データを適用し終え、オフラインのアレイBもオンラインとし、再びアクティブ/アクティブで稼働を始めました。4 以降の性能情報グラフで「ミラーされた書き込み(Mirrored Write)」(紫色の線)が発生していることからそれが分かります。その後、ホストのマルチパスドライバがアレイBの復旧を検知し、読み込み処理(水色の線)もアレイBに分散されるようになりました。なお、私が本検証で実施したのはレプリケーション用ポートの抜線と復旧のみです。復旧を検知してから全自動で ActiveCluster 構成にリカバリされたことがわかります。



