


はじめに
私は、性能検証を行う際のベンチマークツールとして、vdbench を長年愛用しています。vdbench は、ブロックとファイル(NFS / SMB)に対応し、I/O ワークロードの調整や繰り返しテストの設定が容易なすばらしいベンチマークツールです。
しかし近年、CPU 性能の向上や Flash アーキテクチャの進化によりストレージの最大性能も増加を続け、vdbench でストレージの最大性能を引き出せていないケースがいくつかありました。特に、チューニング項目が多いファイル(NFS / SMB)のベンチマークや、高い並列度が求められるスケールアウト製品のベンチマーク時に経験しています。ブロック I/O と比較してファイル I/O は多くのレイヤーが絡むため、I/O 効率の観点でストレージ以外の他のレイヤーがボトルネックになるのは理解できます。それを改善するために、ベンチマークを実行する大量のノード(VM)を用意することも考えられます。しかし、社内の共有リソースのため一人で占有できない、そもそも物理的にサーバー台数が限られている、ストレージの最大性能を引き出せていないからサーバー/VM を追加してくれと後から言われても…、といったいろいろな事情により、現実的でないことも多いでしょう。
そこで今回は、2018 年以降のアップデートがない vdbench(ver 5.04.07)に対して、現在もアップデートを続けていて GitHub で最新コードが公開されている Linux の FIO(Flexible I/O Tester)ツールを使用して、ストレージの最大性能を引き出す検証をしました。そこで得たノウハウを、本ブログでシェアします。
FIO の設定と ioengine=nfs
FIO が使用できる I/O エンジン(–ioengine 引数)は複数あり、ioengine=libaio を指定した非同期 I/O でベンチマークを実施するのが一般的だと思われます。しかし、今回は ioengine=nfs を使用します。
参考
- fio/examples/nfs.fio at master · axboe/fio | GitHub
– https://github.com/axboe/fio/blob/master/examples/nfs.fio - Reading NFS at >=25GB/s using FIO + libnfs | Taras’ Blog on AI, Perf, Hacks
– https://taras.glek.net/post/nfs-for-fio/
抜粋
libnfs is a lovely userspace implementation of NFS client protocol. I opted to integrate that into fio as an NFS plugin. Now one can use fio ioengine=nfs to drive NFS workloads from userspace without worrying about kernel NFS-client bottlenecks/workarounds.
ioengine=nfs は、ユーザー空間の FIO プロセスがカーネル NFS をバイパスして、直接 NFS ストレージにアクセスできる I/O エンジン(Oracle Database の Direct NFS 機能を思い出しました)です。ベンチマークを実施する側としては、より少ないリソース、例えば VM にアサインする CPU/メモリの量で NFS ストレージの最大性能を引き出せると考えられます。
私が使用している RedHat Enterprise Linux 9.3 の yum からインストールした FIO には ioengine=nfs が入っていなかったため、次の手順で GitHub からダウンロードして設定しました。
- 既存の FIO に ioengine=nfs が入っているかを確認
123fio —version<br>fio —enghelp | grep –i nfs<br>fio —enghelp=nfs - ioengine=nfs が入っていない場合は、既存の FIO を削除してから GitHub からダウンロード
123yum remove fio
123wget https://github.com/axboe/fio/archive/refs/heads/master.zip<br>unzip master.zip<br>cd fio-master<br>./configure<br>sudo make clean<br>sudo make<br>sudo make install<br>
123fio —version<br>fio —enghelp | grep –i nfs<br>fio —enghelp=nfs<br>
本測定前の事前確認:1 ノードおよび複数ノードでのシンプルなテスト
FIO は複数ノードからの実行が可能ですが、まずは FIO をインストールした 1 ノードでの実行が正常に動作するかを確認しましょう。私の例では、ファイル名 job.fio で job ファイル(設定ファイル)を作成し、次のように記述しました。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
[global] bs=512k buffered=0 direct=1 group_reporting iodepth=1 ioengine=nfs nfs_url=nfs://xx.xx.xx.xx/iwt-fs-fio norandommap randrepeat=0 create_serialize=0 size=1G runtime=60 |
[job]
percentage_random=0 rw=write numjobs=1
この job ファイル設定では、512 KB の I/O サイズでシーケンシャル書き込み 100% の I/O ワークロードで size x numjobs 数のファイルが作成されます。まずは、シンプルに 1 GB x 1 ファイルで動作確認をしましょう。記述の中にある nfs_url の xx.xx.xx.xx には、NFS ストレージの IP アドレスを指定してください。その後の iwt-fs-fio は、NFS export しているパスです。ioengine=nfs の場合、ユーザー空間の FIO プロセスがカーネル NFS をバイパスして直接 NFS ストレージにアクセスできるため、/etc/fstab や mount -t nfs での事前 NFS マウントは不要です。
それでは、作成した job ファイルを指定して FIO を実行しましょう。
|
1 |
[root@vdb1 fio–master]# fio job.fio |
1 ノードでの実行が正常に動作したら、次は複数ノードでの実行を試してみましょう。以下のように、hostname(または IP アドレス)を記述したファイルを作成します。私の例では、ファイル名 host.list に 8 ノード分の hostname を記述しました。もちろん、これらのノードにも FIO および ioengine=nfs のインストールが必要です。
|
1 2 3 4 5 6 7 8 9 |
[root@vdb1 fio–master]# cat host.list vdb1 vdb2 vdb3 vdb4 vdb5 vdb6 vdb7 vdb8 |
そして、FIO 実行時に –client 引数でファイル名を指定して実行します。複数ノードでの実行前に、各ノードを –server 引数を使用して listen 状態にする必要があります。私はここでハマりました。
Linux の CLI を使用して簡単にスクリプト化する場合は、次のように記述します。
|
1 2 |
[root@vdb1 fio–master]# cat host.list | xargs -i ssh root@{} pkill fio [root@vdb1 fio–master]# cat host.list | xargs -i ssh root@{} fio –server –daemonize=/tmp/fio.pid |
|
1 |
[root@vdb1 fio–master]# fio –client=host.list job.fio |
本測定前の事前確認:FIO パラメータの最適な値を調整
さまざまな I/O ワークロードを実行して、そのストレージの特性を理解することは重要です。今回の本測定では、8 x 5 = 40 パターンの I/O ワークロードをベンチマークすることをゴールとします。
- I/O サイズ:4 KB、8 KB、16 KB、32 KB、64 KB、128 KB、256 KB、512 KB(8 パターン)
- 読み書き比率:read 100%、read 75% & write 25%、read 50% & write 50%、read 25% & write 75%、write 100%(5 パターン)
小さい I/O サイズでは、最大性能を引き出すのが難しい傾向があります。そのため、「4 KB ランダム読み込み 100%」と「4 KB ランダム書き込み 100%」の 2 パターンの I/O ワークロードを使用して、FIO パラメータの最適値を探してみます。
FIO を実行するノードの情報は、次のとおりです。
- ESXi x 2 サーバー
- Linux VM x 8 ノード(VM x 4 / 1 ESXi サーバーあたり)
- 8 CPU、4 GB メモリ/1 ノードあたり
※ 現時点では、このリソース割り当て値が最適かわからないため、今後のテスト中に CPU & メモリ使用率を見て変更していきましょう。 - OS:RedHat Enterprise Linux 9.3
size と numjobs
前述のとおり、size x numjobs 数のファイルが作成されます。つまり、これらのパラメータ値の掛け算がベンチマーク対象となるデータサイズです。明確な容量要件やアクセス範囲の情報がある場合は、その値を参考に設定すれば OK です。一方、情報がない場合でも、これらのファイルサイズを合計した値がストレージのキャッシュサイズ以上になるように設定してください。読み込みキャッシュ、書き込みキャッシュの両方です。多くのストレージ製品ではキャッシュ機能を持つため、ベンチマークに使用するデータサイズの検討は、非常に重要です。データサイズが小さ過ぎて、ほぼキャッシュで処理が完結してしまい、非現実的なベンチマーク結果が取得されているケースがあります。私の例では 10 GB x 100 numjobs なので、1,000 GB がベンチマーク対象のデータサイズになります。
次に、ioengine=nfs は iodepth 値に依存しないため、numjobs 値を使用して FIO から発行される I/O リクエストの負荷量は、numjobs で調整できます。そのため、大きなファイルを少ない numjobs で作成するより、小さいファイルを多くの numjobs で作成した方が、後で負荷量の調整がしやすいです。本測定を効率化するため、ファイル作成時の numjobs は十分大きい値で実行しておきましょう。
ここまでの検討が終了したら、実際にベンチマーク対象のファイルを作成しましょう。 ファイル作成が目的なので、以下のとおり、先ほどと同じ 512 KB のシーケンシャル書き込み 100% の設定のままで OK です。変更したパラメータ(size、numjobs、runtime)は、赤文字で記します。
[global]
bs=512k
buffered=0
direct=1
group_reporting
iodepth=1
ioengine=nfs
nfs_url=nfs://xx.xx.xx.xx/iwt-fs-fio
norandommap
randrepeat=0
create_serialize=0
size=10G
# runtime=60
[job]
percentage_random=0
rw=write
numjobs=100
runtime は、FIO の実行時間(秒)です。この値が設定されていると、上述のデータサイズを満たすファイル作成が完了する前に FIO 実行が終わってしまうため、必ずコメントアウト(#)してください。中途半端なサイズでファイルを作成してしまうと、本測定時に EOF(End-of-File)エラーにヒットする可能性があります。時間は、指定したデータサイズとストレージの書き込み性能に大きく依存しますが、完了するまで待ちましょう。
ファイル作成の完了後、NFS ストレージを NFS マウントしてディレクトリを確認すると、以下のようになっています。10 GB のファイルが 100 個(合計 1,000 GB)あり、ファイル名の先頭は job ファイル内の [ ] で記述した文字列になります。
|
1 2 3 4 5 6 7 |
[root@vdb1 tmp]# ls job.0.0 job.14.0 job.2.0 job.25.0 job.30.0 job.36.0 job.41.0 job.47.0 job.52.0 job.58.0 job.63.0 job.69.0 job.74.0 job.8.0 job.85.0 job.90.0 job.96.0 job.1.0 job.15.0 job.20.0 job.26.0 job.31.0 job.37.0 job.42.0 job.48.0 job.53.0 job.59.0 job.64.0 job.7.0 job.75.0 job.80.0 job.86.0 job.91.0 job.97.0 job.10.0 job.16.0 job.21.0 job.27.0 job.32.0 job.38.0 job.43.0 job.49.0 job.54.0 job.6.0 job.65.0 job.70.0 job.76.0 job.81.0 job.87.0 job.92.0 job.98.0 job.11.0 job.17.0 job.22.0 job.28.0 job.33.0 job.39.0 job.44.0 job.5.0 job.55.0 job.60.0 job.66.0 job.71.0 job.77.0 job.82.0 job.88.0 job.93.0 job.99.0 job.12.0 job.18.0 job.23.0 job.29.0 job.34.0 job.4.0 job.45.0 job.50.0 job.56.0 job.61.0 job.67.0 job.72.0 job.78.0 job.83.0 job.89.0 job.94.0 job.13.0 job.19.0 job.24.0 job.3.0 job.35.0 job.40.0 job.46.0 job.51.0 job.57.0 job.62.0 job.68.0 job.73.0 job.79.0 job.84.0 job.9.0 job.95.0 |
それでは、4 KB ランダム読み込み 100% と 4 KB ランダム書き込み 100% の 2 パターンの I/O ワークロードを使用して、現在の構成でストレージの最大性能を引き出せるか確認してみましょう。
以下の job ファイルは、4 KB ランダム読み込み 100% の I/O ワークロードです。前述の job ファイルから変更したパラメータは、赤文字で記します。numjobs x ノード数がストレージに対する I/O 並列度(queue depth)となるため、私の例では 100 numjobs x 8 ノード = 800 が最大の並列度になります。
[global]
bs=4k
buffered=0
direct=1
group_reporting
iodepth=1
ioengine=nfs
nfs_url=nfs://xx.xx.xx.xx/iwt-fs-fio
norandommap
randrepeat=0
create_serialize=0
size=10G
runtime=60
[job]
percentage_random=100
rw=read
numjobs=xx
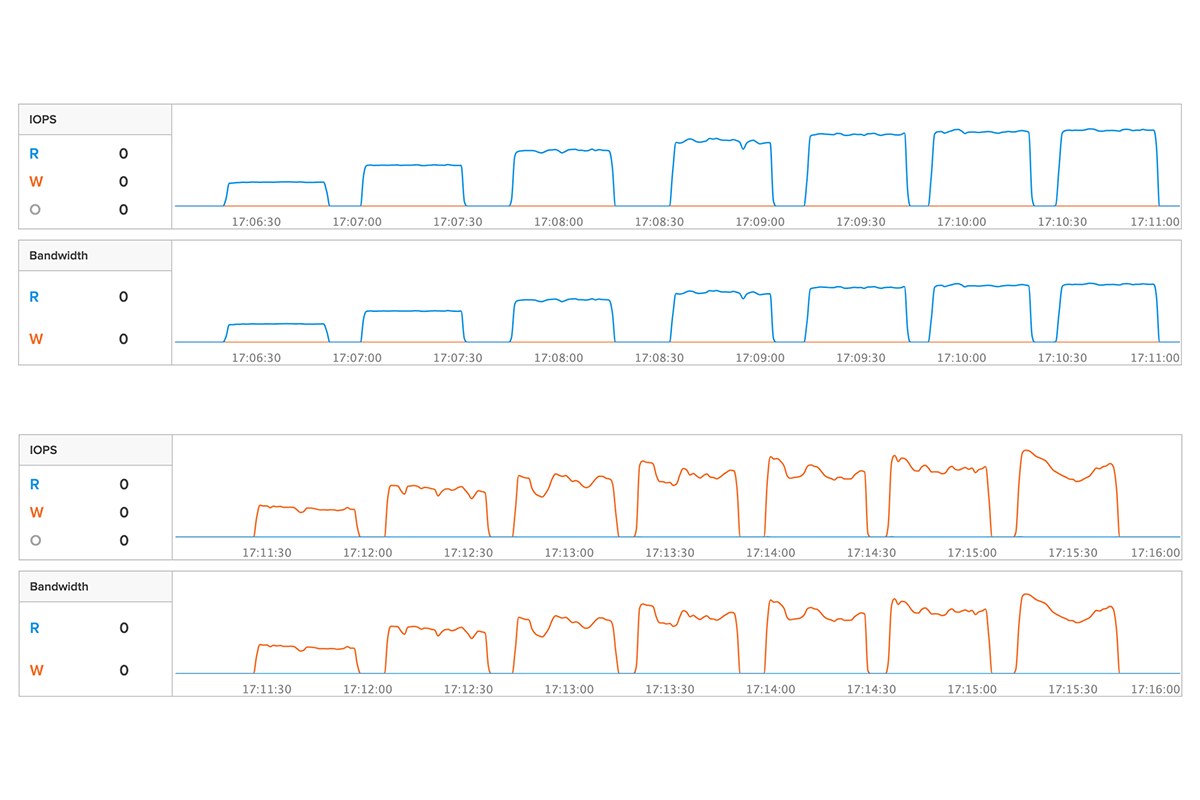
次のグラフは、この job ファイルの numjobs を numjobs=10, 20, 30, 40, 50, 60, 70 に設定して実行した 7 パターンの結果です。ストレージ GUI の IOPS と Bandwidth(帯域幅)を表しています。
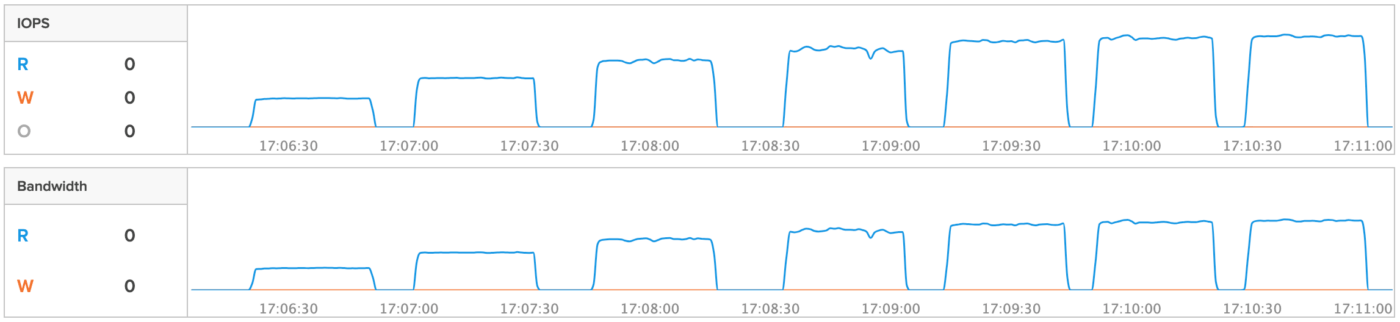
numjobs=50 並列度 400 で性能が頭打ちになっていることがわかります。ストレージ側で性能限界率を確認したところ、numjobs=50 の時点で load=100% を示していました。これにより、4 KB ランダム読み込み 100% において、今回の環境でストレージの最大性能を確実に引き出せていることがわかりました。
※ ピュア・ストレージは、ストレージ管理プラットフォーム Pure1 から確認できる load% という値で性能の限界率がわかります。
参考:Pure1 ブログシリーズ
次の job ファイルは、4 KB ランダム書き込み 100% の I/O ワークロードです。前述の job ファイルから変更したパラメータは、赤文字で記します。
[global]
bs=4k
buffered=0
direct=1
group_reporting
iodepth=1
ioengine=nfs
nfs_url=nfs://xx.xx.xx.xx/iwt-fs-fio
norandommap
randrepeat=0
create_serialize=0
size=10G
runtime=60
[job]
percentage_random=100
rw=write
numjobs=xx
4 KB ランダム読み込み 100% のテストと同様に、job ファイルの numjobs を numjobs=10, 20, 30, 40, 50, 60, 70 に設定して実行した 7 パターンの結果が次のグラフです。ストレージ GUI の IOPS と Bandwidth を表しています。
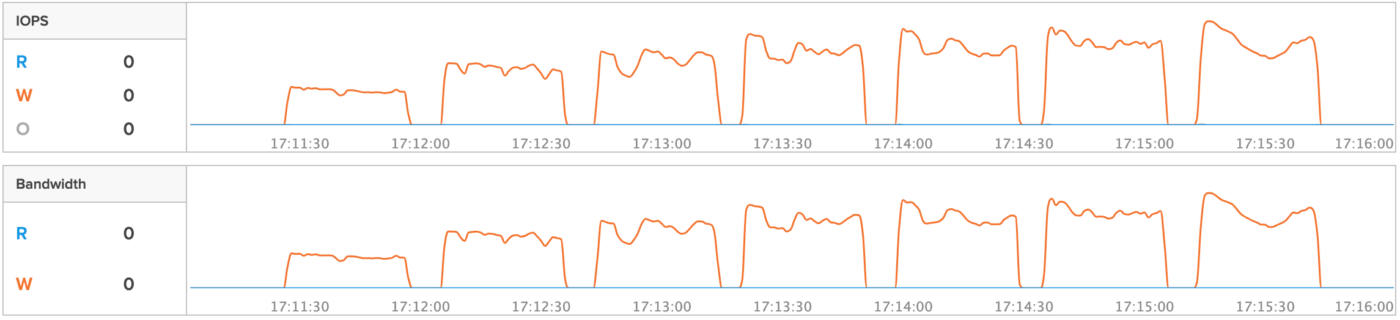
numjobs=50 並列度 400 で性能が頭打ちになっていることがわかります。こちらもストレージ側で性能限界率を確認したところ、numjobs=50 の時点で load=100% を示していました。これにより、4 KB ランダム書き込み 100% においても、今回の環境でストレージの最大性能を確実に引き出せていることがわかりました。
ここまでの 4 KB ランダム読み込み 100% と 4 KB ランダム書き込み 100% の結果から、今回の環境では最低でも numjobs=50 に設定すれば、想定する全ての I/O ワークロードの最大性能を取得できるでしょう。
また、いずれのテスト中も、CPU とメモリの使用率は半分以下でした。個人で使用できるリソースが限られている検証環境では、リソース割り当て値を減らすことも検討できます。私の環境では、1 ノードあたりの CPU 数を半分にしました。
- ESXi x 2 サーバー
- Linux VM x 8 ノード(VM x 4 / 1 ESXi サーバーあたり)
- 4 CPU、4GB メモリ/ 1 ノードあたり
- OS:RedHat Enterprise Linux 9.3
本測定の開始
それではいよいよ、本測定を始めましょう!
今回の本測定のゴールは、下記の 8 x 5 = 40 パターンの I/O ワークロードに対してベンチマークを行うことです。さまざまな I/O ワークロードのベンチマーク結果があれば、そのストレージの特性を理解できます。
- I/O サイズ:4 KB、8 KB、16 KB、32 KB、64 KB、128 KB、256 KB、512 KB(8 パターン)
- 読み書き比率:read 100%、read 75% & write 25%、read 50% & write 50%、read 25% & write 75%、write 100%(5 パターン)
作成した I/O ワークロード x 40 パターンの job ファイルは、次のとおりです。
|
1 2 3 4 5 6 |
[root@vdb1 JOBFILE]# ls job.fio.128k.R100 job.fio.16k.R100 job.fio.256k.R100 job.fio.32k.R100 job.fio.4k.R100 job.fio.512k.R100 job.fio.64k.R100 job.fio.8k.R100 job.fio.libaio job.fio.128k.R25W75 job.fio.16k.R25W75 job.fio.256k.R25W75 job.fio.32k.R25W75 job.fio.4k.R25W75 job.fio.512k.R25W75 job.fio.64k.R25W75 job.fio.8k.R25W75 sed.sh job.fio.128k.R50W50 job.fio.16k.R50W50 job.fio.256k.R50W50 job.fio.32k.R50W50 job.fio.4k.R50W50 job.fio.512k.R50W50 job.fio.64k.R50W50 job.fio.8k.R50W50 job.fio.128k.R75W25 job.fio.16k.R75W25 job.fio.256k.R75W25 job.fio.32k.R75W25 job.fio.4k.R75W25 job.fio.512k.R75W25 job.fio.64k.R75W25 job.fio.8k.R75W25 job.fio.128k.W100 job.fio.16k.W100 job.fio.256k.W100 job.fio.32k.W100 job.fio.4k.W100 job.fio.512k.W100 job.fio.64k.W100 job.fio.8k.W100 |
スクリプトを作成し、これら 40 パターンの job ファイルを指定して、順番に FIO を実行していきましょう。結果ファイルは、デフォルトでは output ディレクトリに出力されます。テストの結果ファイルが上書きされないように、FIO 実行時に –output 引数を使用しましょう。私の環境では、次のようにスクリプト化しました。
[root@vdb1 fio-master]# cat run_all.sh
#!/bin/sh
TESTNAME=”20240327_RandRW_NUMJOBS60x8Nodes_DRR1″
LOGPATH=”/root/fio-master/output/${TESTNAME}”
mkdir ${LOGPATH}
fio –client=host.list –output=${LOGPATH}/4k.R100.log JOBFILE/job.fio.4k.R100
…
…
…
以下は、読み込みと書き込みを混在させる job ファイルの設定です。前述の job ファイルから変更したパラメータは、赤文字で記します。また、numjobs=50 でストレージの最大性能を引き出せることが先ほどのテストでわかっているため、本測定では + 10 で numjobs=60 x 8 ノード = 並列度 480 としました。
[root@vdb1 JOBFILE]# cat job.fio.4k.R75W25
[global]
bs=4k
buffered=0
direct=1
group_reporting
iodepth=1
ioengine=nfs
nfs_url=nfs://xx.xx.xx.xx/iwt-fs-fio
norandommap
randrepeat=0
percentage_random=100
create_serialize=0
size=10G
runtime=600
[job]
rw=randrw
rwmixread=75
numjobs=60
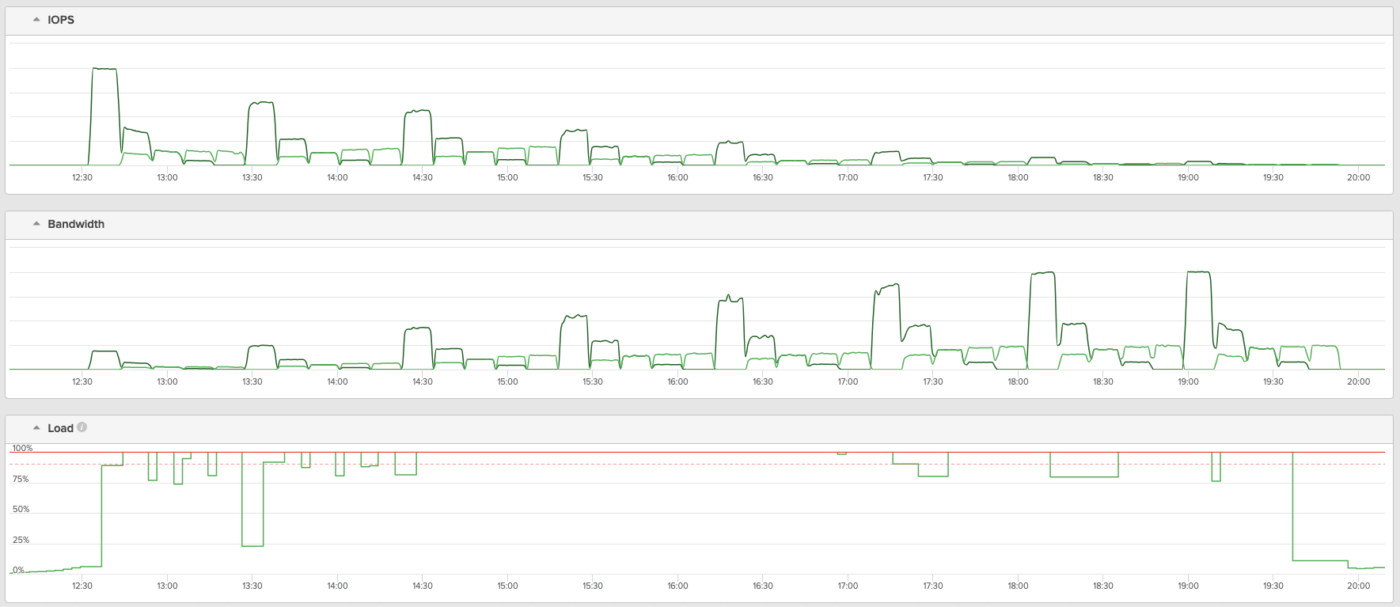
以下のグラフは、ストレージ GUI に表示された結果です。上から IOPS、Bandwidth、Load(ストレージ性能の減価率 %)を表しています。40 パターン全ての I/O ワークロードで、ストレージの限界性能(Load 100%)まで引き出すことに成功しました。
まとめ
今回の検証から、FIO は、高性能ストレージの最大性能を効率的に引き出す優れたツールであることがわかりました。FIO は、ブロックはもちろん、本ブログで紹介した NFS(ioengine=nfs)に加え、S3(ioengine=http)のベンチマークも可能であり、プロトコルに依存しない共通のベンチマークツールとして使用できます。
ツールに関わらず、本測定前の事前準備は非常に重要です。ストレージのベンチマークであれば、ホストやネットワークがボトルネックになっていないか、ツールの設定値が最適な値になっているかといったポイントを考慮してみてください。
本ブログの内容が、皆さまのベンチマークにお役に立てることを願っています。
Pure Storage、Pure Storage のロゴ、およびその他全ての Pure Storage のマーク、製品名、サービス名は、米国およびその他の国における Pure Storage, Inc. の商標または登録商標です。その他記載の会社名、製品名は、各社の商標または登録商標です。
Written By: