昨今、大規模な本番環境で利用されるコンテナ環境が徐々に増えており、2021 年後半以降にはステートフルなデータも含めた利用が一気に加速すると予想されています。そのような状況のなか、今回は、バックアップと共に、ステートレス、ステートフルに関わらず、ミッション・クリティカルな環境の保護手段の1つとして挙げられる、コンテナのディザスタ・リカバリ機能を提供する Portworx の PX-DR をご紹介します。
なお、PX-DR は 30 日間のトライアル・ライセンスには含まれません。もし、PoC をご検討いただける場合は、sales-japan@purestorage.com までお問い合わせください。
「PX-DR」でデータ保護の問題を解決
PX-DR は、Portworx のデータ保護機能として提供している単一のデータセンターやマルチ・アベイラビリティ・ゾーン内での高可用性に加えて、次のレベルで Kubernetes アプリケーションを保護します。
第 1 に、単一の大都市圏内、またはキャンパス・エリアにあるデータセンター間で、データ損失ゼロ(ゼロ RPO)のディザスタ・リカバリを提供します。これは、データが 10 ms 未満のレイテンシでサイト間で同期できることが前提となります。ゼロ RPO フェイルオーバーを有効にし、Kubernetes を使用した RTO(目標復旧時間)の向上を可能にします。
第 2 に、非同期レプリケーションによる、地理的に分散したデータセンターへのディザスタ・リカバリ機能を提供します。ある場所から別の場所へスナップショットとリソースの増分非同期レプリケーションを行うことで、これを実現します。
Kubernetes を始めるにあたり、ステートレス・アプリケーションは最も一般的な出発点です。しかし、データベースのようなステートフル・アプリケーションを Kubernetes プラットフォームで実行しようとする場合には、データ保護の問題が発生します。PX-DR は、主に同期レプリケーションと非同期レプリケーションという 2 つの方法でこれらの問題を解決します。本ブログでは、同期レプリケーションについてご紹介します。
データセンター間のゼロ RPO フェイルオーバーを実現する同期レプリケーション
同期レプリケーションは、1 つのクラスタに書き込まれたデータの全てのビットを 2 番目のクラスタにも複製することをいいます。最初のクラスタで他の書き込みを許可する前に、2 番目の環境にデータを複製する必要があるためです。
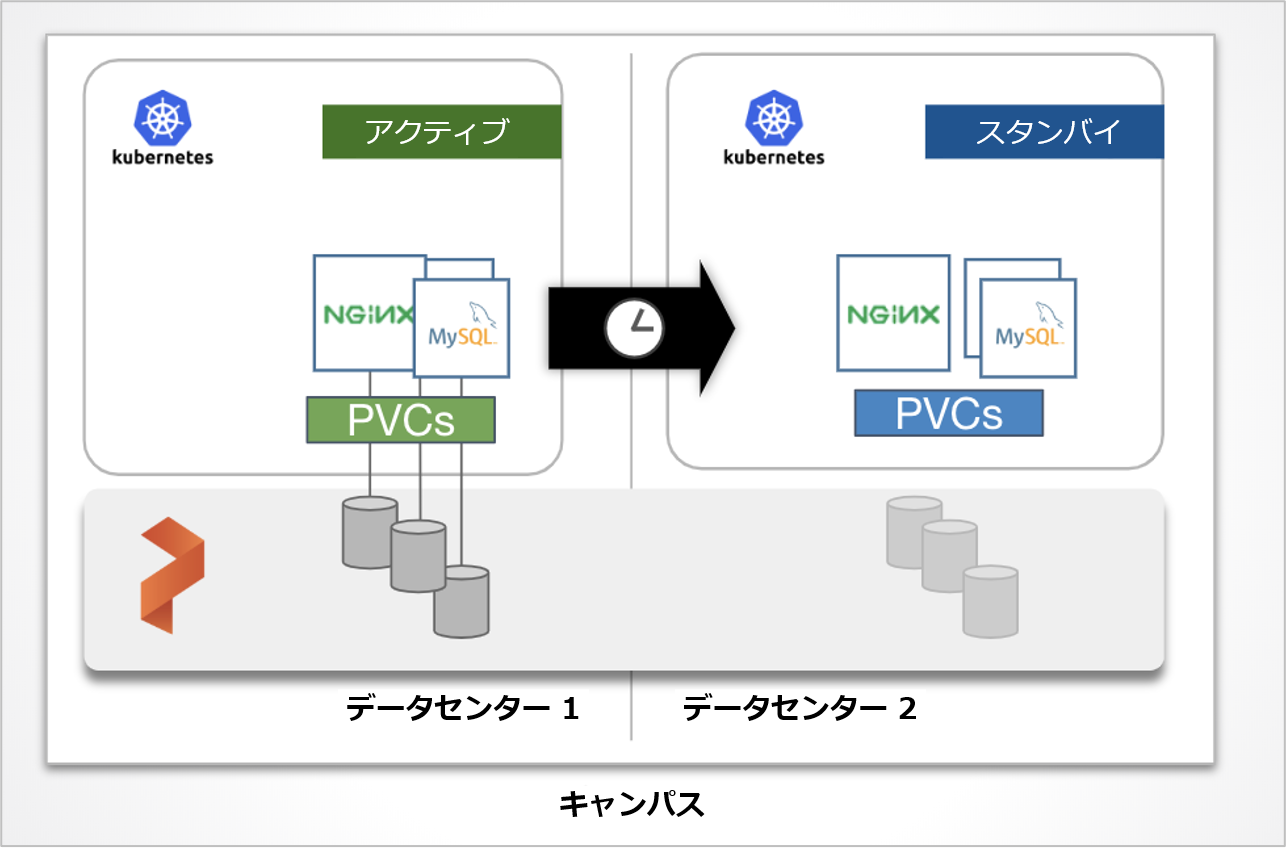
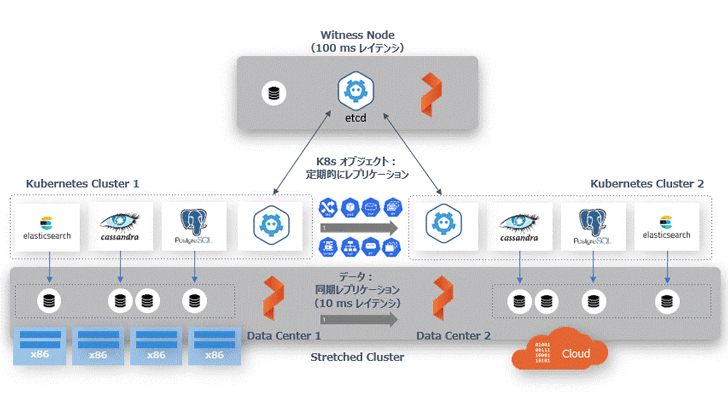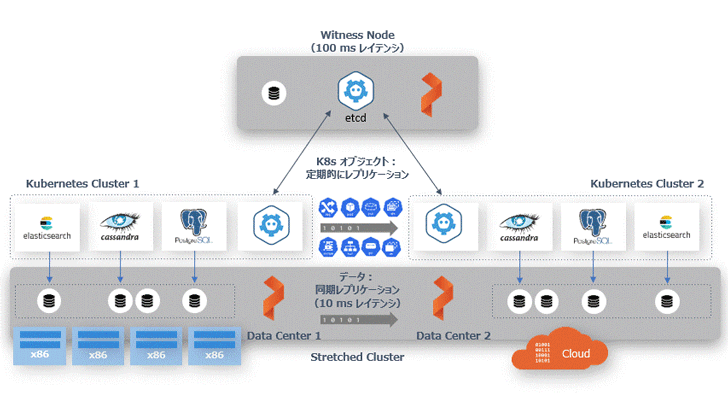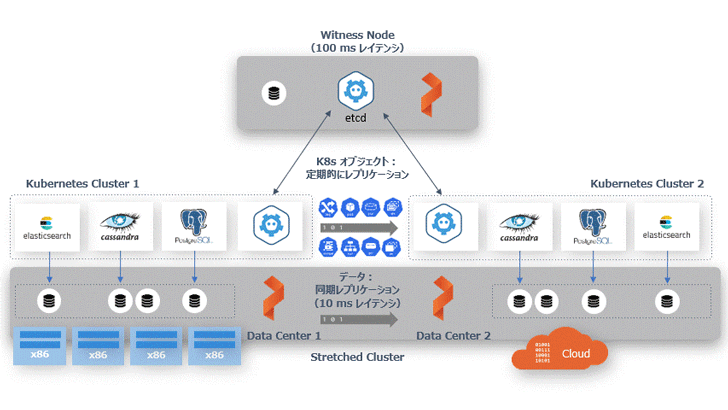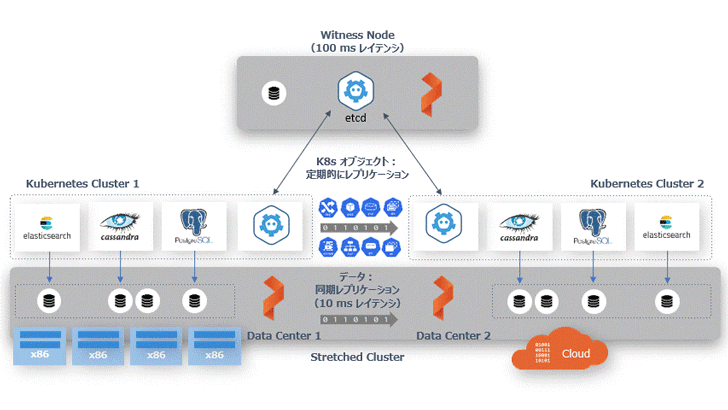
PX-DR でディザスタ・リカバリ環境を構築する際には、2 つの Kubernetes クラスタを単一の Portworx クラスタ上に構成します。Kubernetes クラスタの 1 つはアクティブなクラスタとなり、もう 1 つは別のフォールト・ドメイン、またはデータセンターのスタンバイ・クラスタとなります。同期レプリケーションにおいてレイテンシは重要な考慮事項ですので、データセンター間の往復が 10 ms 未満であることをお勧めします。
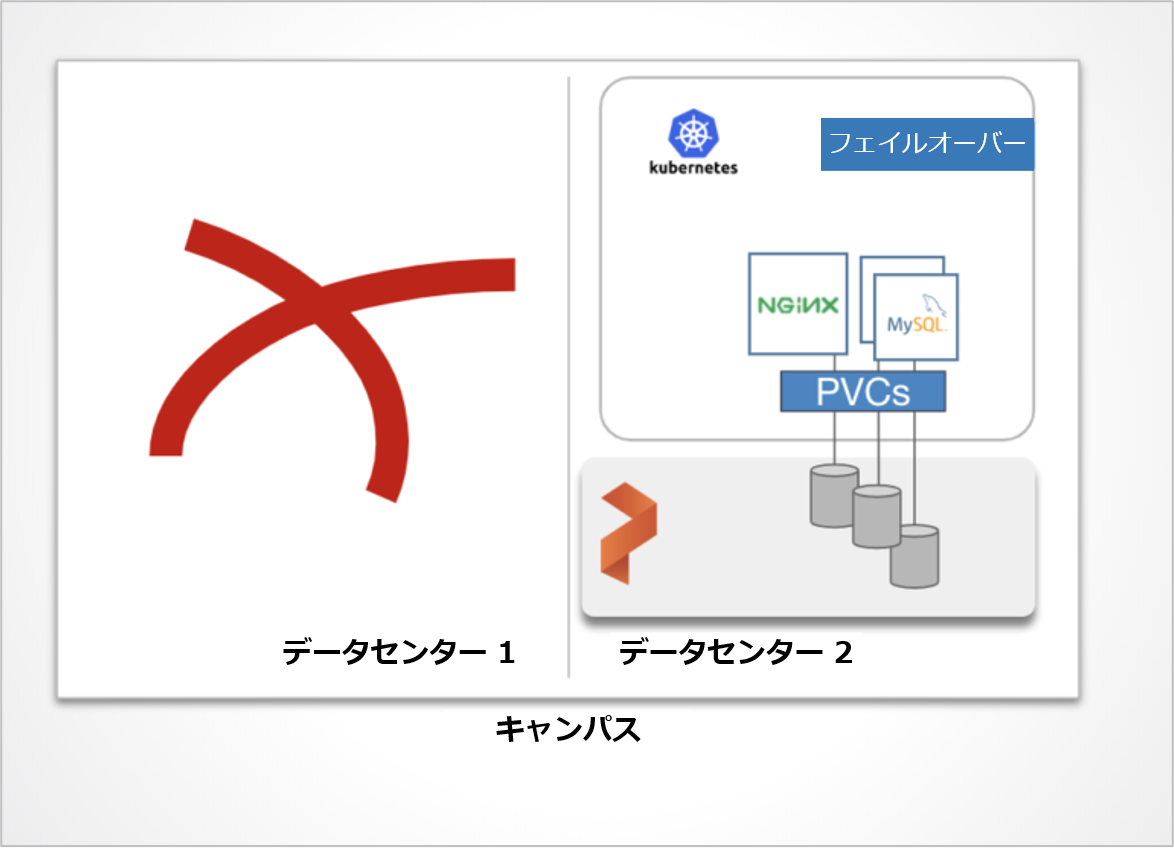
プライマリ・クラスタのアプリケーションにデータが書き込まれると、両サイトにデータが複製されます。 その後、障害が検出されると、スタンバイ・クラスタがゼロ RPO でアクティブ・クラスタとしてアプリケーションを引き継ぎます。
PX-DR 同期レプリケーション機能のアーキテクチャ
2 つの Kubernetes クラスタに対して、Portworx が管理する同一のクラスタ ID を割り当てることで、物理的に離れていても Portworx はストレッチ・クラスタ(Stretched Cluster)として認識します。また、コンテナ向けソフトウェア定義のストレージ(SDS)でご紹介したボリュームの同期レプリケーション機能を使って、データ(Persistent Volume)をクラスタ間で同期することが可能になります。それ以外の Secret、ConfigMaps、Service といった Kubernetes オブジェクトは、アクティブ側のクラスタからスタンバイ側に定期的に同期されます。
データは常に同期しているため、アクティブなクラスタがダウンした場合にはスタンバイ側の Kubernetes の Deployment や Service を起動し、ユーザーからのトラフィックは DNS などを利用してスタンバイ側に切り替えます。
PX-DR 同期レプリケーションのセットアップ
ここからは同期レプリケーションのセットアップ方法をご紹介します。詳細については、こちらのマニュアルもご参照ください。
前提条件
今回用意した環境は次のとおりです。
- Kubernetes クラスタ:2つの Kubernetes クラスタを同一の vSphere 6.5 上に準備しました。両クラスタ間通信のレイテンシは 1 ms 以内であり、同期レプリケーションの前提条件である 10 ms 以内という条件を満たしています。
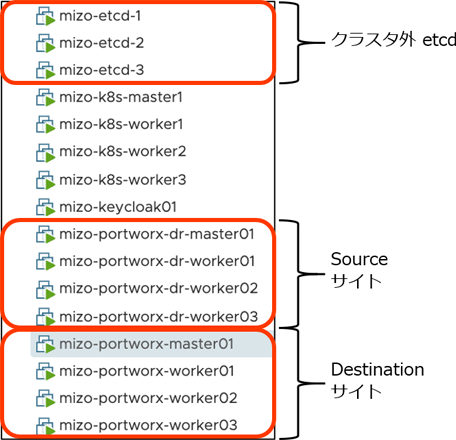
- バージョン:
- Portworx バージョン:2.6.3 ※ PX-DR を含む Porworx Enterprise ライセンスを利用
- Kubernetes バージョン:v1.19.8
- Stork バージョン:2.6.0
- 外部 Kvdb:PX-DR をご利用の際は、両クラスタの外部に Kvdb のセットアップが必要です。
- クラスタ ID:クラスタ間で同じクラスタ ID とします(ストレッチ・クラスタ)。
- ドメイン ID:同一のクラスタ ID を割り当ててストレッチ・クラスタにする代わりに、各クラスタには異なるドメインID(Portworx が内部でクラスタを識別する ID)を設定します。
手順 1. Portworx のインストール
新規に Portworx のインストールを行い、PX-DR をセットアップします。
まず、Spec Generator で、クラスタごとに異なる Spec ファイルを準備します。基本的なインストールの方法は、以前のブログ「Portworx Enterprise のインストール」で解説しておりますので、そちらをご参照ください。
PX-DR を設定する際の留意点
- ETCD は Your etcd details を選択し、用意した etcd のアドレスを登録してください。
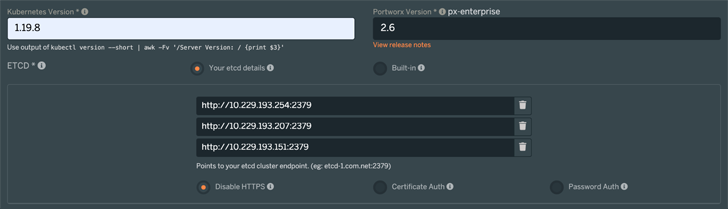
- 以降は、環境に沿って Spec ファイルを作成してダウンロードします。ダウンロードした Spec ファイルをアクティブ / スタンバイのそれぞれのクラスタ用にコピーします。その際、クラスタ ID と Kvdb のエンド・ポイントが同じであり、1 つの Portworx クラスタが 2 つの Kubernetes クラスタにまたがっている状態にします。
cluster_domainパラメータをアクティブ / スタンバイでそれぞれ異なる名前を設定します。
例:アクティブ側:purejp-primary01、スタンバイ側:purejp-secondary01
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
apiVersion: apps/v1 kind: DaemonSet metadata: name: portworx namespace: kube–system labels: name: portworx annotations: portworx.com/install–source: “https://install.portworx.com/?mc=false&kbver=1.19.7&k=etcd%3Ahttp%3A%2F%2F10.229.193.254%3A2379%2Cetcd%3Ahttp%3A%2F%2F10.229.193.207%3A2379%2Cetcd%3Ahttp%3A%2F%2F10.229.193.151%3A2379&c=px-cluster-9341bcaa-3173-4b89-8f8c-fca3a9cbb8d7&cluster_domain=purejp-primary01&stork=true&csi=true&mon=true&st=k8s” spec: selector: matchLabels: name: portworx minReadySeconds: 0 updateStrategy: type: RollingUpdate rollingUpdate: maxUnavailable: 1 template: metadata: labels: name: portworx spec: …… containers: – name: portworx image: portworx/oci–monitor:2.6.3 imagePullPolicy: Always args: [“-k”, “etcd:https://10.229.193.254:2379,etcd:https://10.229.193.207:2379,etcd:https://10.229.193.151:2379”, “-c”, “px-cluster-9341bcaa-3173-4b89-8f8c-fca3a9cbb8d7”, “-cluster_domain”, “purejp-primary01”, “-a”, “-secret_type”, “k8s”, “-x”, “kubernetes”] |
- 上記のマニフェスト・ファイルをアクティブ及びスタンバイ Kubernetes クラスタそれぞれに適用します。
123# kubectl apply -f portworx_enterprise.yaml - 作成した Portworx クラスタがストレッチ・クラスタ(Stretched Cluster)として認識されていることを確認します。
123# kubectl get nodes -o wide

ドメイン ID:
purejp-primary01の Kubernetes クラスタ
ドメイン ID:purejp-secondary01の Kubernetes クラスタ
Portworx 上では 1 つのストレッチ・クラスタとして認識されていることがわかります。
123# kubectl exec portworx-n7j99 (worker node上のportworx DaemonSet) -n kube-system — /opt/pwx/bin/pxctl status<br>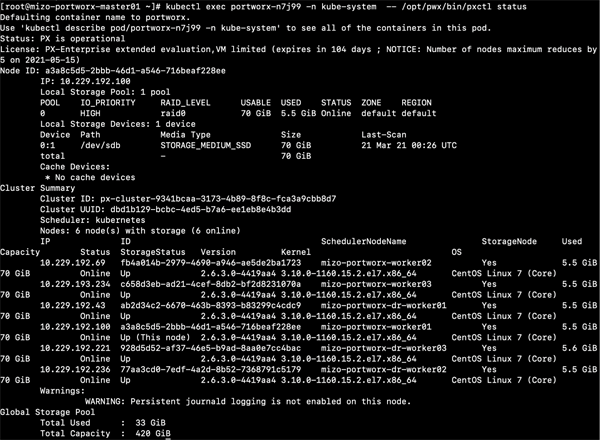
- Master ノード上で
storkctlコマンドを実行し、各ドメインのクラスタ上のステータスがどちらもACTIVEであることを確認します。
123# storkctl get clusterdomainsstatus<br>NAME ACTIVE INACTIVE CREATED<br>px-cluster-xxxx [purejp-secondary01, purejp-primary01] [] 09 Apr 19 17:12<br>
手順 2. ClusterPair
ある Kubernetes クラスタで実行しているアプリケーションを別の Kubernetes クラスタにフェイルオーバーするには、クラスタ間でリソース(Deployment やConfigMap、Secret など)をマイグレーションする必要があります。Portworx では、ClusterPair と呼ばれる、他の Kubernetes クラスタと通信するために必要な Trust Object を定義します。これにより、スケジューラ(Kubernetes)間にペアリングが作成され、全ての Kubernetes リソースをスケジューラ間でマイグレーションできるようになります。
Source クラスタと Destination クラスタの概念は Kubernetes レベルでのみ適用され、ストレージには適用されません。これは、両クラスタで単一の Portworx ストレージ・ファブリック(ストレッチ・クラスタ)が実行されているためです。
- Source クラスタ:アプリケーションを実行している Kubernetes クラスタ
- Destination クラスタ:Source クラスタでの障害発生時の、アプリケーションのフェイルオーバー先の Kubernetes クラスタ
ClusterPair は次の方法で生成します。
- Destination クラスタ上で ClusterPair スペックを生成します。
123storkctl generate clusterpair –n green (同期対象とする namespace) remotecluster (ペアの名前)出力は次のようになります。
123apiVersion: stork.libopenstorage.org/v1alpha1<br>kind: ClusterPair<br>metadata:<br> creationTimestamp: null<br> name: remotecluster<br> namespace: green<br>spec:<br> config:<br> clusters:<br> kubernetes:<br> LocationOfOrigin: /etc/kubernetes/admin.conf<br> certificate–authority–data: <CA_DATA><br> server: https:// 10.229.192.117:6443<br> contexts:<br> kubernetes-admin@kubernetes:<br> LocationOfOrigin: /etc/kubernetes/admin.conf<br> cluster: kubernetes<br> user: kubernetes-admin<br> current-context: kubernetes-admin@kubernetes<br> preferences: {}<br> users:<br> kubernetes-admin:<br> LocationOfOrigin: /etc/kubernetes/admin.conf<br> client-certificate-data: <CLIENT_CERT_DATA><br> client-key-data: <CLIENT_KEY_DATA><br> options:<br> <insert_storage_options_here>: “”<br>status:<br> remoteStorageId: “”<br> schedulerStatus: “”<br> storageStatus: “” - <insert_storage_options_here>: “” の行を削除して
optionsには何も指定せず、上記の内容を Source クラスタ上でclusterpair.yamlというファイル名で保存し、適用します。
123kubectl create –f clusterpair.yaml - Source クラスタの Master ノード上で次のコマンドを実行し、ペアのステータスを確認します。
123storkctl get clusterpair<br>NAME STORAGE–STATUS SCHEDULER–STATUS CREATED<br>remotecluster NotProvided Ready 09 Apr 19 18:16 PDT<br>上記のように出力されれば、正常に ClusterPare が生成できていることになります。
手順 3. クラスタを同期
ペアになっている Source クラスタと Destination クラスタ間で Kubernetes リソースを同期するには、それらを定期的にマイグレーションする必要があります。
ボリューム上のデータ(Persistent Volume)は、同期レプリケーションの機能を使ってクラスタ間で同期します。ここでは、それ以外の Secret、ConfigMaps、Service などの Kubernetes リソースを定期的にアクティブ側のクラスタからスタンバイ側に同期します。
スケジュール・ポリシーの生成
マイグレーションをスケジュールするには、スケジュール・ポリシーを作成します。
blueという名前の名前空間上のリソースを 1 分間隔でマイグレーションするようにスケジューリングします。ここではbluepolicy.yamlというファイルにポリシーを生成します。
123apiVersion: stork.libopenstorage.org/v1alpha1<br>kind: SchedulePolicy<br>metadata:<br> name: bluepolicy<br> namespace: blue<br>policy:<br> interval:<br> intervalMinutes: 1- 次のコマンドでポリシーを適用します。
123kubectl apply –f bluepolicy.yaml - 生成されたスケジュール・ポリシーを表示します。
123storkctl get schedulepolicy<br>NAME INTERVAL–MINUTES DAILY WEEKLY MONTHLY<br>bluepolicy 1 N/A N/A N/A<br>
マイグレーションのスケジューリング
マイグレーション・スケジュールにより、SchedulePolicy とマイグレーションを関連付けることができます。上述の bluepolicy を使用した例を以下に示します。このマイグレーションは blue という名前空間を指し、その名前空間で remotecluster という名前の clusterPair が存在する場合、それを使用します。また、includeResources、includeVolumes、および startApplications を spec の中で指定することで、マイグレーションを制御できます。
includeResources:Secret、ConfigMaps、Service など、ボリュームに関連付けられた Kubernetes オブジェクトを含めるかどうか。includeVolumes:PVC に関連付けられた Portworx ボリュームのマイグレーションを含めるかどうか。startApplications:リソースやボリュームが同期された後、Destination クラスタでアプリケーションを開始するかどうか。falseに設定すると、同期した Deployment や Statefulset は Destination クラスタ上で replicas=0 と設定され、フェイルオーバー後に手動で起動します。trueに設定すると、同期された Deployment や Statefulset は Destination クラスタ上で自動的に起動します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
apiVersion: stork.libopenstorage.org/v1alpha1 kind: MigrationSchedule metadata: name: mysqlmigrationschedule namespace: blue spec: template: spec: clusterPair: remotecluster includeResources: true includeVolumes: true startApplications: false namespaces: – blue schedulePolicyName: bluepolicy |
次のコマンドで、マイグレーションが正常に行われているかを確認できます。
|
1 2 3 |
kubectl get migration –n blue NAME AGE bluemigrationschedule–interval–2021–04–26–024315 24s |
手順 4. アプリケーションのフェイルオーバー
Kubernetes クラスタの 1 つがダウンしてアクセスできないという災害が発生した場合は、アプリケーションは稼働中の別の Kubernetes クラスタにフェイルオーバーする必要があります。
- ダウンした Kubernetes クラスタ
例:cluster_domain:purejp-primary01 - フェイルオーバー先の Kubernetes クラスタ
例:cluster_domain:purejp-secondary01
アプリケーション(名前空間)をフェイルオーバーするには、Kubernetes クラスタの 1 つがダウンしていて非アクティブであることを Portworx に指示します。
Fail したクラスタ・ドメインの非アクティブ化
ここでは、storkctl コマンドを実行して Source クラスタを手動で非アクティブ化します。
|
1 |
storkctl deactivate clusterdomain purejp–primary01 |
ドメインが正常に非アクティブ化(INACTIVE)されていることを確認します。
|
1 2 3 |
storkctl get clusterdomainsstatus NAME ACTIVE INACTIVE CREATED px–cluster–xx [purejp–secondary01] [purejp–primary01] 09 Apr 21 17:12 PDT |
Source クラスタ上のアプリケーションの停止(アクセス可能な場合)
Source クラスタがまだ有効でアクセス可能な場合は、アプリケーションを Destination クラスタにフェイルオーバーする前にアプリケーションを停止することをお勧めします。
Deployment と StatefulSet のレプリカ数を 0 に変更することで、アプリケーションの実行を停止できます。アプリケーション・リソースは Kubernetes に残りますが、実際のアプリケーションは実行されません。
|
1 |
kubectl scale —replicas 0 deployment/mysql –n blue |
mysql デプロイメントのレプリカは 0 に設定されているため、Source クラスタでのマイグレーション・スケジュールを一時停止する必要があります。これは、Destination クラスタ上の mysql Deployment のレプリカが 0 に更新されないようにするためです。
|
1 |
kubectl edit migrationschedule –n blue bluemigrationschedule |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
apiVersion: stork.libopenstorage.org/v1alpha1 kind: MigrationSchedule metadata: name: bluemigrationschedule namespace: blue spec: template: spec: clusterPair: remotecluster includeResources: true startApplications: false includeVolumes: false namespaces: – blue schedulePolicyName: bluepolicy suspend: true |
Destination クラスタ上のアプリケーションの起動
上述の「マイグレーションのスケジューリング」の項では、 startApplications: false に設定したため、アプリケーションは自動的には実行されません。レプリカ数を設定することで、アプリケーションをスケーリングできます。
各アプリケーションのスペックには stork.openstorage.org/migrationReplicas という Source クラスタでのレプリカ数を示すアノテーションを設定することができます。
レプリカ数が 0 から更新されると、アプリケーションは実行を開始し、フェイルオーバーが完了します。
次のコマンドを使用して、アプリケーションをスケーリングできます。
|
1 |
kubectl scale —replicas 1 deployment/mysql –n blue |
あるいは、以下のようにスペックに指定されたアノテーションを検索し、自動的に正しい数にスケーリングします。
|
1 |
storkctl activate migration –n blue |
手順 5. アプリケーションのフェイルバック
フェイルした Kubernetes クラスタがリカバリして起動した際は、そのクラスタ内のノードはすぐには Portworx クラスタに参加しません。このクラスタ・ドメインを明示的に Activate するまで、Out of Quorum の状態を維持します。
非アクティブ・クラスタ・ドメインのアクティブ化
フェイルバックを開始するには、まず、アクティブな Destination クラスタの Master ノード上で Source クラスタを Active としてマークします。
|
1 |
storkctl activate clusterdomain purejp–primary01 |
コマンドが成功したことを確認するには、次のチェックを実行します。
|
1 2 3 |
storkctl get clusterdomainsstatus NAME ACTIVE INACTIVE CREATED px–cluster… [purejp–primary1, purejp–secondary1] [] 09 Apr 21 17:13 PDT |
Destination クラスタでアプリケーションを停止
アプリケーションのフェイルオーバー先である Destination クラスタで、Source クラスタにフェイルバックするようにアプリケーションを停止します。
Deployment と StatefulSet のレプリカ数を 0 に変更することで、アプリケーションの実行を停止できます。
|
1 |
kubectl scale —replicas 0 deployment/mysql –n blue |
Source クラスタでアプリケーションを起動
Destination クラスタでアプリケーションを停止したら、Source クラスタでレプリカ数を変更してアプリケーションを再開します。
|
1 |
kubectl scale —replicas 1 deployment/mysql –n migrationnamespace |
Source クラスタのマイグレーション・スケジュールを一時停止していた場合は、suspend: false に設定して解除します。
|
1 |
kubectl edit migrationschedule –n blue bluemigrationschedule |
最後に storkctl を使用して、スケジュールが一時停止されていないことを確認します。
|
1 2 3 |
storkctl get migrationschedule –n blue NAME POLICYNAME CLUSTERPAIR SUSPEND LAST–SUCCESS–TIME LAST–SUCCESS–DURATION bluemigrationschedule bluepolicy remotecluster false 17 Apr 21 17:16 PDT 2m0s |
以上、PX-DR の同期レプリケーションの一連の流れをご説明しました。ここで同期レプリケーションのデモ動画をご紹介します。実際の動きをご覧いただけますので、こちらもぜひ参照ください。
Pure Storage、Pure Storage のロゴ、およびその他全ての Pure Storage のマーク、製品名、サービス名は、米国およびその他の国における Pure Storage, Inc. の商標または登録商標です。その他記載の会社名、製品名は、各社の商標または登録商標です。