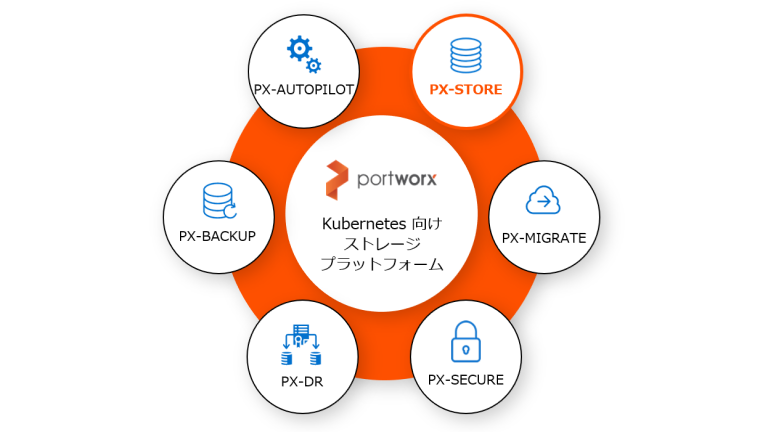


Kubernetes 向け Portworx ストレージ・プラットフォームの基盤「PX-Store」
今回は、Portworx の基盤となるコンテナ向け「ソフトウェア定義のストレージ(Software-Defined Storage、以下 SDS)」の機能を提供する PX-Store をご紹介します。
Portworx は、Kubernetes クラスタ内の worker ノードに接続されたさまざまなタイプ、サイズ、またはベンダーのストレージ・デバイスを抽象化して、1 つの仮想ストレージ・プールを作成します。標準的なブロック・ストレージであれば種類は問いません。SDS である Portworx は、Daemon Set として各 worker ノード上に配置され、クラスタ内の他の worker ノードとやり取りしながら仮想ストレージ・プールを管理します。
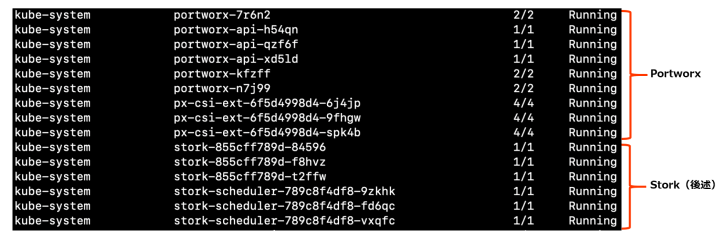
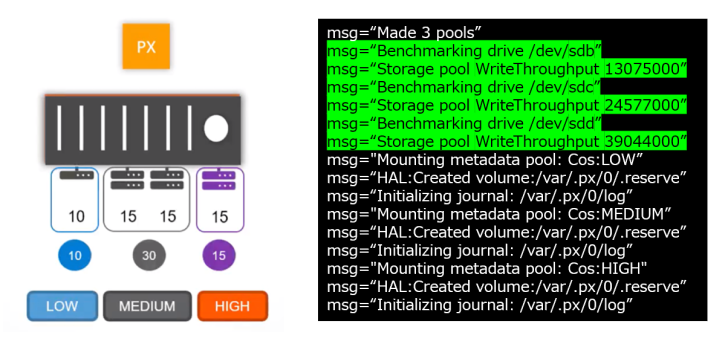
運用中に、利用可能なストレージを持つ worker ノードがノードとして Kubernetes クラスタに追加されると、自動的に Portworx がインストールされます。インストールされた Portworx は、ノード上で利用可能な物理的なストレージを /dev 配下(例:/dev/sdb、/dev/sdc など)から探し、プールに追加します。その際に、各ストレージに対して簡単なベンチマークを行い、「HIGH」「MEDIUM」「LOW」に区分します。コンテナからはアプリケーションの特性にあわせて「HIGH」「MEDIUM」「LOW」のストレージを選択できるようになります。
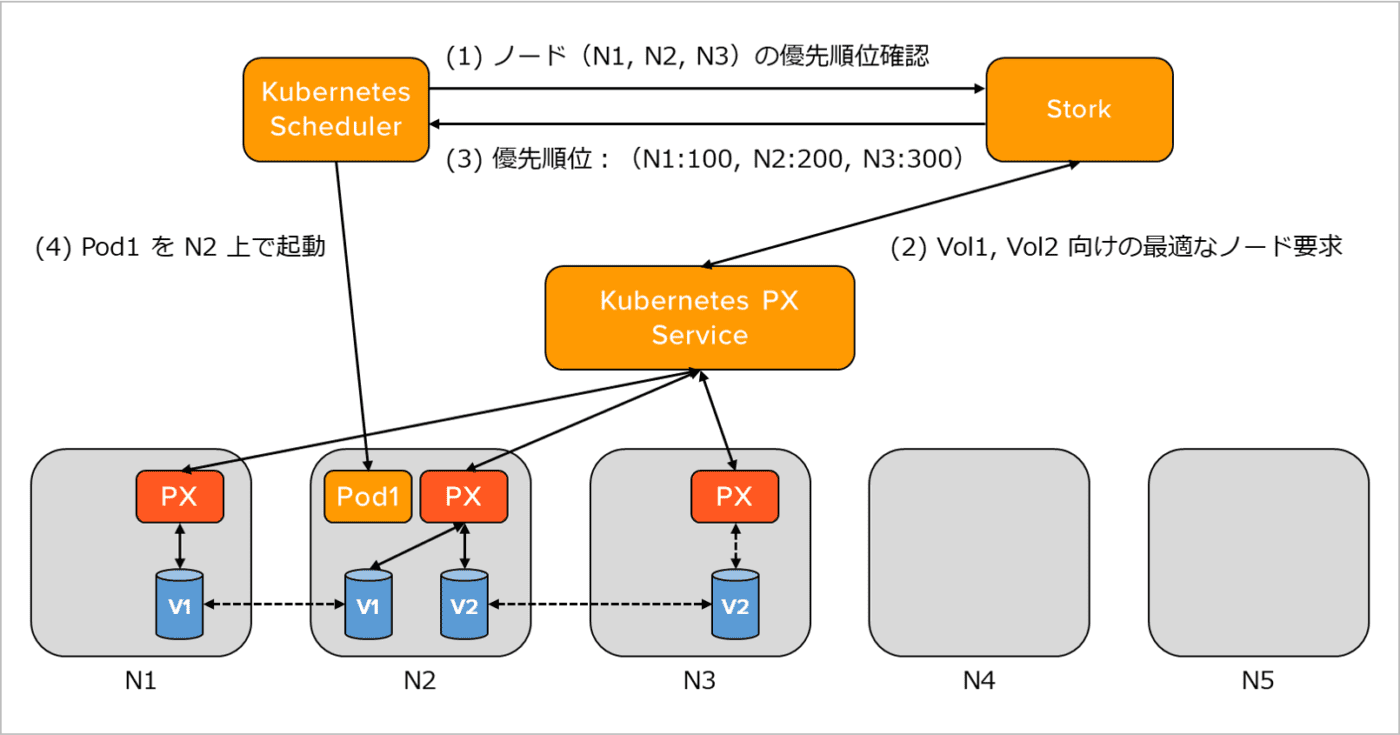
また、Portworx により利用するボリュームが存在するサーバーに、ポッドがスケジュールされます。 アプリケーションのローカル・パフォーマンスを保証するために、同一ノード上へストレージをアプリケーションとともにプロビジョニングし、データをメモリや CPU のそばに配置することで、輻輳の原因になりかねないネットワークの問題を回避します。これには Kubernetes の ポッドを配置するスケジューラのエクステンションとして Stork(STorage Orchestrator Runtime for Kubernetes)が利用されています。Stork は、Portworx が CNCF(Cloud Native Computing Foundation)で Apache 2.0 License のオープンソースとして開発、保守している Kubernetes Scheduler Extension です。ボリューム・スナップショット、ボリューム暗号化、分離、クラスタ内の最適なボリューム配置などを Portworx サービスと連携して実現します。
PX-Store のアーキテクチャ
PX-Store のアーキテクチャを詳しく見てみましょう。
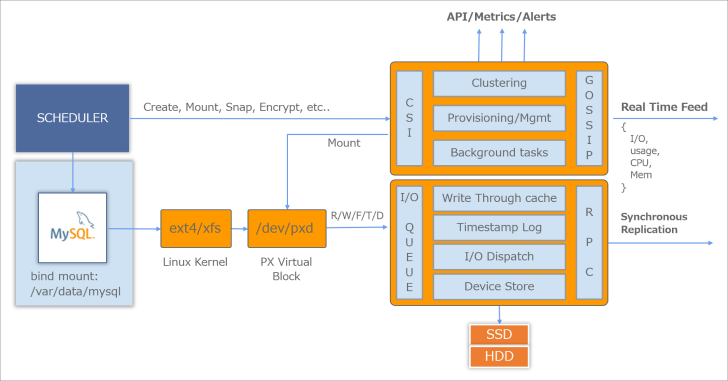
PX-Store は、コントロール・プレーンとデータ・プレーンに分かれています。コントロール・プレーンは、主に Kubernetes スケジューラからのボリューム作成やマウントなどの要求を受け、CSI(Container Storage Interface)を介して自身が管理する仮想ストレージ・プールからボリュームを切り出し、対象のノードにマウントします。ボリュームは、ノード上の /dev/pxd/ 配下に仮想ブロック・ストレージとしてマウントされます。また、Portworx のクラスタ管理として GOSSIP プロトコルを通じて各 worker ノードのリソース状況やクラスタ内のノードの稼働状況を管理します。
データ・プレーンでは、実際の I/O を処理します。例えば、MySQL のコンテナが Portworx を Provisioner として指定した StorageClass で I/O を行うとします。すると、先にマウントされた仮想ブロックを通して Portworx のデータ・プレーンで処理が行われます。データ・プレーンの I/O Dispatch では、各 I/O が、どのノードの、どのストレージに対するものなのかを把握しており、適切なストレージに I/O をディスパッチします。
ボリュームの同期レプリケーション
Portworx では、前述の I/O Dispatch の仕組みを使用して、最大 10 ms 以内のターンアラウンド・タイム環境においてボリュームの同期レプリケーションを実行できます。
- コンテナから Portworx Volume Driver を指定して書き込みを行う。
- データ・プレーンの中の I/O Dispatch が、どのノードのボリューム宛てのものかを判別する。
- レプリカを持ってる場合は、レプリカにも RPC のインターフェース経由で同期する。
- 両方の書き込みバッファに書き込みが完了した時点で、アプリケーション側に Ack を応答する。
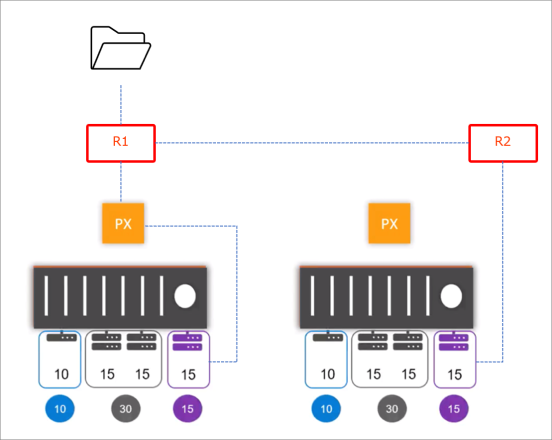
ボリュームのレプリカは最大 3 つまで指定できます。3 つ指定した場合は、2 つのボリュームで同期が完了した時点でアプリケーション側に Ack を応答します。
Aggregation Set
通常 Portworx では、1 つのボリュームは 1 つの仮想ストレージ・プールにマッピングされます。
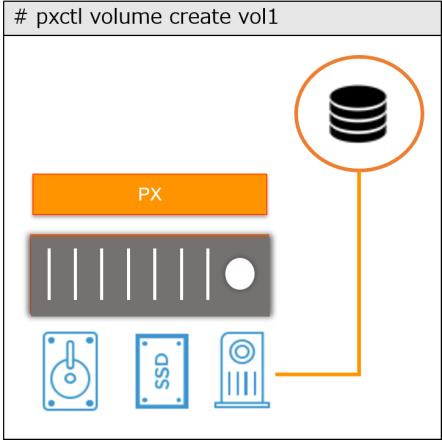
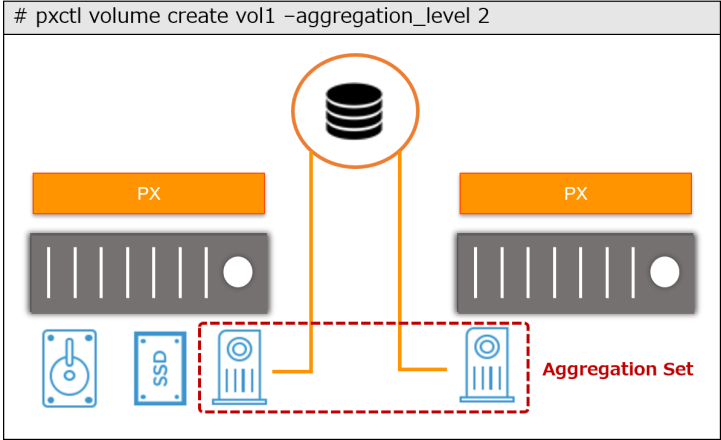
一方、Aggregation Set という機能を使用すると、プールやサーバーをまたいでボリュームの作成が可能となり、書き込みは RAID のストライプのような形で行われます。これにより、1 ボリュームあたりの性能と容量のスケーラブルな拡張が可能になります。なお、Aggregation Set は、最大 3 つのプールまで指定できます。
性能への考慮
I/O を実行する際にデータ・プレーンを通過しますが、これにより性能に対する懸念を感じる方もいらっしゃると思います。そのための工夫の 1 つとして、Portworx ではボリューム単位で I/O プロファイルを設定、または自動検知して最適な I/O を行います。
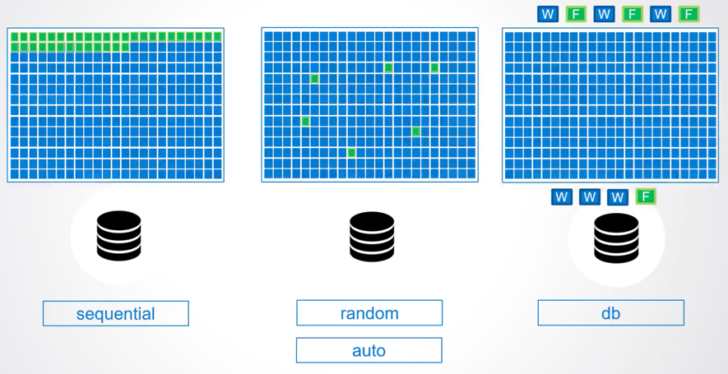
最適な I/O のための工夫には、例えば次のようなものがあります。
- シーケンシャルな Read が多いボリュームに対して、Linux の Page Cache と連動して先読みサイズを最適化する。
- データベースのワークロードが大半のボリュームで、Write → Flash → Write → Flash の繰り返しを 60 ms で Write → Write → … → Flash とまとめて効率的に Flash を行う。
詳細は、パフォーマンス・チューニングのマニュアルをご参照ください。
このような工夫により、通常、Portworx による I/O へのオーバーヘッドは約 3% 以下に収まります。
サンプル Portworx アプリケーション
ここまでは、Portworx のベースとなる SDS の機能について解説しました。次に、Portworx を利用して簡単な Postgres アプリケーションを作成する方法をご紹介します。
1. StorageClass の作成
provisioner に portworx-volume を指定した StorageClasss を作成します。この StorageClass には、ボリュームのレプリケーションを "3" と指定しています。
|
1 2 3 4 5 6 7 8 9 10 |
##### Portworx storage class kind: StorageClass apiVersion: storage.k8s.io/v1beta1 metadata: name: px–postgres–sc provisioner: kubernetes.io/portworx–volume parameters: repl: “3” io_profile: “db” priority_io: “high” |
2. PersistentVolumeClaim の作成
作成した px-postgres-sc という StorageClass を使って、postgres-data という PersistentVolumeClaim を作成します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
##### Portworx persistent volume claim kind: PersistentVolumeClaim apiVersion: v1 metadata: name: postgres–data annotations: volume.beta.kubernetes.io/storage–class: px–postgres–sc spec: accessModes: – ReadWriteOnce resources: requests: storage: 2Gi |
3. ボリュームのマウント
最後に、作成した PersistentVolumeClaim である postgres-data を指定して、/var/lib/postgresql/data に作成されたボリュームをマウントします。
注:ここで schedulerName には必ず stork を指定してください。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
apiVersion: apps/v1 kind: Deployment metadata: name: postgres labels: app: postgres spec: replicas: 1 selector: matchLabels: app: postgres template: metadata: labels: app: postgres spec: schedulerName: stork containers: – name: postgres image: postgres:9.5 imagePullPolicy: “IfNotPresent” ports: – containerPort: 5432 env: – name: POSTGRES_USER value: pgbench – name: PGUSER value: pgbench – name: POSTGRES_PASSWORD value: superpostgres – name: PGBENCH_PASSWORD value: superpostgres – name: PGDATA value: /var/lib/postgresql/data/pgdata volumeMounts: – mountPath: /var/lib/postgresql/data name: postgres–data volumes: – name: postgres–data persistentVolumeClaim: claimName: postgres–data |
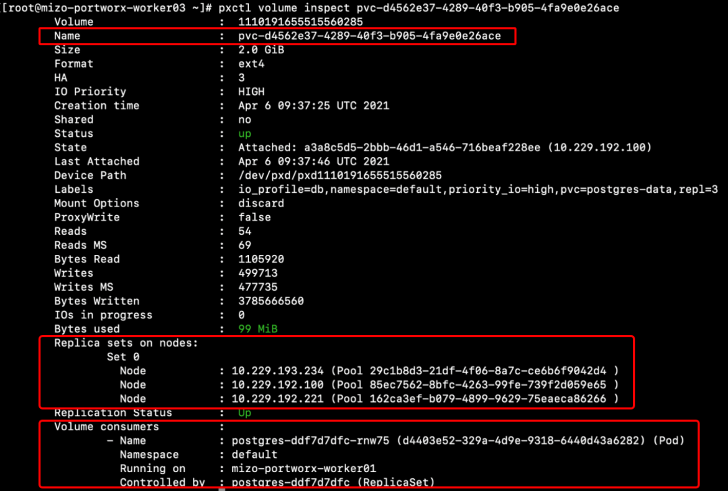
では、実際にどのようにボリュームが作成されているかを見てみましょう。pvc-d4562e37-4289-40f3-b905-4fa9e0e26ace というボリュームが postgres-data という名前で作成されています。

次に、Portworx がインストールされている worker ノードで作成されたボリュームの詳細を確認します。1110191655515560285 というボリュームが 10.229.192.100 - mizo-portworx-worker01 という worker ノードにアタッチされていることがわかります。
また、レプリケーションとして 10.229.192.100 以外にも 10.229.193.234 と 10.229.192.221 の worker ノードにもボリュームが作成されています。
では、10.229.192.100 上でボリュームがアタッチされている様子を確認してみましょう。/dev/pxd の配下に pxd1110191655515560285 というブロック・デバイスが作成されていることがわかります。

このように、Portworx を使用したボリューム作成は非常にシンプルです。その他、Portworx を使ったサンプル yaml ファイルは以下のサイトに掲載されています。ぜひお試しください!
Pure Storage、Pure Storage のロゴ、およびその他全ての Pure Storage のマーク、製品名、サービス名は、米国およびその他の国における Pure Storage, Inc. の商標または登録商標です。その他記載の会社名、製品名は、各社の商標または登録商標です。