

ピュア・ストレージ・ジャパン、FlashBlade セールスリードの大浦と申します。本年もよろしくお願いいたします。
FlashBlade に関する本社ブログの翻訳記事を中心に、数回にわたってご紹介してまいります。第一回目は、『AI の成長に伴う「痛み」とその克服法』と題しまして、Pure Storage Inc. のエミリー・ワトキンズ(Emily Watkins)および Ziff.ai 社の CEO、デビッド・ゴンザレス氏(David Gonzales)との共同執筆記事のご紹介です。
AI プロジェクトにおけるデータパイプラインの構築は簡単ではありませんが、継続的学習(Continuous Training)や拡張型学習(Augmented Learning)などが組み込まれた高度な AI プロジェクトでは、さらに難度が高くなります。
この記事では、AI プロジェクトの成長とともに、アプリケーションレベル、インフラストラクチャレベルの複雑さが通常どのように増大していくかを説明します。軽い気持ちで AI の実装を決断すべきではありません。現状では AI ソリューションはプラグアンドプレイではないからです。今すぐにでも AI パイプラインの構築を始めるという場合は、少なくともプロジェクトがこの先どのように展開していくかを理解しておく必要があります。先を考えておくことで、後で大変な思いをせずにすむのです。
ピュア・ストレージはこれまで、お客様による AI ソリューションの展開に対し、最初から最後まで一貫したお手伝いをしてきました。AI ソリューションの展開には共通する「落とし穴」がいくつかあります。早い段階から考慮しておくべきだと考えます。
AI 導入の初期段階から最先端の拡張型学習に至るまで、データを効率的に管理できることが重要となります。また、アプリケーションとインフラストラクチャの複雑さが問題発生の原因となることがあり、そのリスクは AI を深めるにつれて増大します。
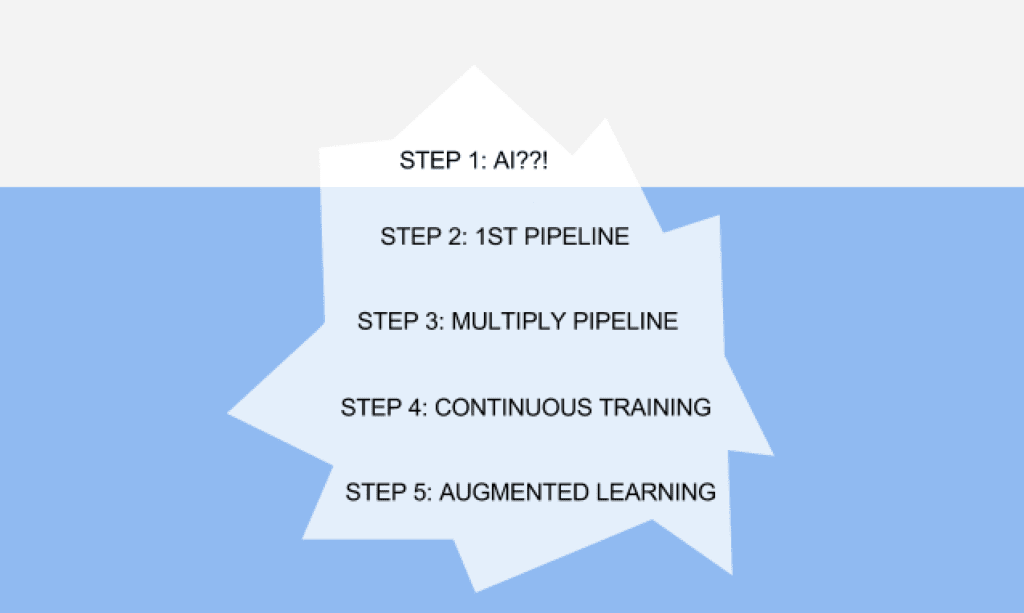
1:AI 戦略を検討する
AI 戦略について検討することに決めたとします。その場合、まず AI がどのように会社へビジネス価値をもたらすかをブレインストーミングし、そのために調査すべきデータセットや解決が必要な指標を特定します。そして、機械学習ではなく単純な発見的問題解決法が採用できないかを評価します。通常、AI ツールの調査には、オープンソースのアプリケーション(TensorFlow など)やオープンソースのデータセット(ImageNet など)を使用します。
一般的には、次のような「痛みのポイント」(pain point)があります。
- 学習データの可用性
- AI に対する過剰な期待
2:最初の機械学習を実稼動環境に導入する
この段階では、人間の推論によって学習データにラベルが付けられている、あるいはあらかじめラベルの付けられたデータを入手していることでしょう。この学習データセットを調べて、その一貫性を検証し、外れ値、空の値、誤りのある値を評価する必要があります。
データの準備段階では、次のような「痛みのポイント」があります。
- 手作業によるデータへのラベル付けに多大な労力が必要で、エラーも起こりやすい
- 正確な結果を得るために、学習データセットは、代表的なものでなければならない
- データ管理と来歴調査に時間がかかり、効率的ではない
好みの学習アプリケーション(Caffe2、TensorFlow、PyTorch など)を使って、ニューラルネットワークに学習させます。このニューラルネットワークを、利用しようとしているデータセットに対して検証し、モデル上で反復して精度を高め、実稼動に向けた準備を進めます。精度が許容できるレベルに達したら、推論の実行を開始する準備は完了です。ニューラルネットワークを新しいデータのストリームに展開して、その場で分析します。
学習段階では、次のような「痛みのポイント」があります。
- ハイパーパラメータの調整の複雑さや、ストレージパフォーマンスの遅さ、データ移動の繰り返しにより、学習の反復速度が遅くなりがち
- ニューラルネットワークのデバッグには、学習ソフトウェアの調整や学習データ自体を細かく調整しなければならない

最初のパイプラインまでの時間を短縮するには、AI パイプラインを集中ストレージハブに閉じ込めておきましょう。
3:範囲を拡大する
通常、AI プロジェクトは拡大し、複数のモデルを含むようになります。これにより、推論中に集められる情報の完全性が高まります。たとえば、顔認識に必要な各要素(年齢、性別、感情)のニューラルネットワークを構築するとします。AI チームは、インフラストラクチャが、同じ学習データを同時に使用する複数のデータサイエンティストやチームをサポートできることを保証する必要があります。
ここでの「痛みのポイント」は、ステップ 2 と同様ですが、取り扱うモデルの数とともに難度が増します。
4:継続的学習を行う
推論中は異常を検知し、パイプラインにフィードバックしてモデルを再学習させることができます。これは「アクティブ学習」(active learning)と呼ばれることもあります。また、急激に発展するネットワーク設計(畳み込みネットワーク、GAN など)やデータソース(人工的な学習データの生成など)のもたらす恩恵を活用し、パイプラインを調整することもできます。成功するチームは、多くの場合 DevOps のような戦術を使ってその場でモデルを展開し、フィードバックループを継続させています。
このフェーズに共通する「痛みのポイント」は次のとおりです。
- パイプラインの変化に伴うパフォーマンス要求の進化に対応できない柔軟性のないストレージやネットワークインフラストラクチャが、AI チームの足かせとなる
- モデルのパフォーマンスの監視
5:拡張型学習を行う
ニューラルネットワークは、サイロ同士の発展に不可欠なものへと変わっていきます。既存のニューラルネットワークを活用する方法はいくつもあります。たとえば、転移学習(transfer learning)を通じて新しいネットワークをすぐに開始させるために、学習データを置き換えたり、隣り合う問題セットに既存のモデルを提供したりすることができます。
人間とデータの相互作用の各段階で、困難さは急激に増していきます。
AI 開発の初期段階からの非効率性と「痛みのポイント」が次々と混ざり合い、1 つのニューラルネットワークの開発から、ダウンストリームにある個々のプロジェクトへと受け継がれていきます。
高速なインフラストラクチャがあれば、AI チームは、開発フェーズを迅速に進められます。
現在、チームが、AI パイプラインの各段階にインフラストラクチャサイロを持っていることは珍しくありませんが、パイプライン全体に接続する集中ストレージハブを持つよりも柔軟性に乏しく、時間もかかります。
ストレージが存在する複数の場所でパイプラインのステージングを実行する代わりに、データの複製をいくつも作成、管理、削除するための待ち時間や手間、リスクを削減し、貴重な時間を科学者チームに返してあげましょう。AI に対応するには、これまでよく使われてきた DAS 接続のストレージ では不十分です。FlashBlade™ は、データパイプラインのあらゆるステージを加速するために設計された、AI に最適な究極のストレージハブです。
私たちは、AI はビジネスにとって有効かという疑問を持つお客様によく出会いますが、実際 AI は有効なものです。分析を専門とした企業のように AI をコアコンピテンシーの中心と位置付けているケースもあれば、保険会社のように中心には据えていないケースもあります。どちらの場合でも、AI はデータを多用するプロジェクトに効率と正確さをもたらす、有用なツールです。AI 戦略の到達点をどこに据えるかには関係なく、大量データの取り込みと分析の急激な進化の両方をサポートするインフラストラクチャを持つことが重要なのです。
ピュア・ストレージはお客様の成功を支援します。GPU+ストレージアーキテクチャやソフトウェアツールに関する疑問や、要素のひとつひとつをすべてつなぎ合わせるにはどうすればいいかといった相談など、あらゆるお問い合わせにお応えする準備を整えています。データから知見を得るまでの時間を短縮する方法について、ぜひご相談ください。スピーディーな AI の導入をお手伝いします。
大浦からのコメント
AI への取り組みには、様々なアプローチがあります。本記事は、「過剰な期待」を避けつつ AI 戦略の検討から始まり、最初の機械学習、範囲の拡大を行い、継続的学習、拡張型学習へとひとつひとつのステップに取り組んで行くことが重要であるということをご紹介しました。
また、AI パイプラインの各段階で、しばしば見受けられる「インフラのサイロ」を FlashBlade が解消し、データパイプラインのあらゆるステージを加速することができることも大きなポイントとなります。
AI に最適な究極のストレージハブである FlashBlade を、ぜひ、皆様の AI ビジネスを加速させるツールとしてご活用ください。
英語版URL: https://blog.purestorage.com/ai-growing-pains-master/