
In the world of software engineering, code can take multiple formats between the time it’s written by a programmer to the point it gets executed by a computer. What starts as high-level source code in a programming language such as Python or Java eventually becomes the lowest level of language a computer can read and execute: machine code. Between high-level source code and machine code, it often takes on an intermediary format known as bytecode.
- In this article, we’ll look closely at both machine code and bytecode to unpack their differences, what they both do, and how they’re related.
What Is Machine Code?
Machine code is the simplest, basic level of code, meant to be directly read and executed by a computer’s hardware. Machine code is so low-level that it’s not readable by humans or higher-level systems. It’s binary, made up entirely of sequences of 1s and 0s that correspond to commands or operations, telling a machine’s components (e.g., its memory) exactly what to execute.
Machine code becomes this low-level format via a code assembler or compiler, translating high-level software commands into operations a machine can perform.
The Role of Machine Code
The role of machine code is to act as an interface between software and hardware, translating high-level software language into code a computer can understand. It’s also an important foundation for the higher-level languages as well as the compilers and interpreters used to create bytecode, which we’ll cover next. When software can be written by programmers in a multitude of languages, the role of machine code is to ensure high-level commands can be translated from human-readable to machine-readable, while also offering code specific to that hardware for the ultimate efficiency and optimization.
Pros and Cons of Machine Code
The pros and cons of machine code include:
Pros:
- It can directly interact with target hardware components. This provides more clarity and the ability to be more granular in instructions and commands, so software programs can be even more optimized for a specific machine.
- It can leverage hardware-specific architecture and capabilities directly. Because the machine code is specific to the hardware, it’s able to be specific to the machine’s capabilities, features, and resources.
Cons:
- It’s not readable by humans and can be very complex. It’s not easy or efficient to code in machine code for more complex operations. That’s why high-level programming languages, which abstract away many steps, are required.
- It’s specific to the machine, so it is not highly portable to other machines (which likely have their own code).
- It’s difficult to convey high-level concepts or operations.
What Is Bytecode?
Bytecode is a compact, platform-independent, and portable version of high-level code. It’s akin to a middle ground between source code and machine code: It’s not readable by a human programmer like source code, but it’s also not readable by hardware, like machine code. Instead, a compiler within a programming environment translates the source code into bytecode, which is then executed by a virtual machine or interpreter or compiled further.
This is important because modern software often needs to be processed on many different devices, operating systems, and platforms. To do this efficiently, bytecode offers a simplified, consolidated version of the source code and presents it in a numeric format. This makes it lightweight and portable, unlike machine or binary code, which are often specific to hardware (e.g., a specific CPU). All the system needs is the right VM, and the code can be executed.
What Is Bytecode in Simple Terms?
In simple terms, bytecode is a more compact version of a high-level program written in a high-level programming language such as Java or Python, but it cannot be run without an interpreter. In this respect, it’s often referred to as intermediary code, specifically designed to make high-level software portable, streamlined, readable, and executable with the appropriate virtual machine or interpreter. It’s also referred to as “p-code,” short for portable code.
Is Binary Code the Same as Bytecode?
No. Binary code is not the same as bytecode. They’re both written in binary format, consisting of numerical 1s and 0s, but beyond that, they serve different purposes.
Binary code is low-level code. It’s executable directly by a computer’s hardware. This is data and instructions in a language a computer can understand and act on. Binary code is also specific to the hardware of the machine it’s run on.
Bytecode, on the other hand, is intermediary code. Unlike binary code, it is not directly executed by hardware but by interpreters or virtual machines. Bytecode is not specific to hardware but is generated by a compiler in a programming language or environment (e.g., Java) and then executed by a virtual machine. It’s a compact, optimized version of source code, made more portable and easier to interpret.
Pros and Cons of Bytecode
The pros and cons of bytecode include:
Pros:
- Allows code to be run cross-platform
- Easier to interpret
- Can reduce hardware and operating system dependencies. When the same bytecode can be run on multiple devices or platforms, it doesn’t have to be modified or interpreted.
Cons:
- Compiler or translator overhead. In software development, there will always be a trade-off between developer efficiency and program efficiency. The abstraction, while enabling greater flexibility and portability, can add overhead to a program, but just-in-time compilers can improve performance with more dynamic translation on the fly.
- More platform dependency. It’s known as p-code for a reason, but it still requires a compatible VM in order to run.
- Lack of hardware control or optimization
- Can be more complex and time-consuming to run testing, debugging, and diagnostics
Virtual Machine Architecture
Deep Dive into VM Internals
Modern bytecode execution environments like the Java Virtual Machine (JVM) and Common Language Runtime (CLR) have sophisticated multi-layered architectures that manage the execution pipeline from bytecode to machine code:
- The Class Loader subsystem is responsible for loading bytecode into memory, verifying its integrity, and preparing it for execution
- The Execution Engine converts bytecode instructions into native machine instructions through interpretation or Just-in-Time (JIT) compilation
- The Memory Manager handles memory allocation, garbage collection, and optimization
The bytecode verification process is particularly critical for security. It performs static analysis to ensure type safety, control flow integrity, and memory access validity before execution begins. This verification includes:
- Stack map frame analysis to validate operand stack states
- Type checking to ensure operations are performed on compatible data types
- Reference validation to prevent unauthorized memory access
Garbage Collection and Bytecode
Garbage collection algorithms interact closely with bytecode execution. Modern collectors implement sophisticated approaches:
- Generational collectors separate objects by age, focusing collection efforts on short-lived objects
- Concurrent mark-sweep collectors minimize application pause times by performing collection alongside program execution
- G1 (Garbage-First) collectors divide heap memory into regions for more efficient collection
The bytecode itself contains metadata that helps the garbage collector identify object references and optimize collection strategies.
Bytecode vs. Machine Code
Abstraction Differences in Bytecode vs. Machine Code
Machine code has a very low level of abstraction, by design. It’s meant to interact directly with hardware and low-level operations. Bytecode has a mid-level of abstraction; however, it’s closer to source code than it is to machine code. That abstraction means it cannot directly interact with the machine without an interpreter.
Why Is Machine Code Generally Faster than Bytecode?
Machine code is generally faster than bytecode because it’s easier and faster for a machine to process compared to when there’s an abstraction layer (the same layer that makes it faster for programmers to write and compile the code, hence the frequent trade-off). Abstraction simply means that the code is less fine-grained, which also results in less direct control over machine operations. Machine code is directly aligned with the hardware’s cache, memory, and more—so the software can be, too.
Other reasons are:
- It’s in its native machine language. Without another layer of interpretation, you’re telling the machine exactly what to do in the language designed for that purpose. Less overhead means faster execution. The interpretation required from bytecode can take more time and effort, although just-in-time compilation can help.
- There’s better optimization at the machine level. Utilizing a compiler for hardware-specific machine code can help you leverage the best features of the hardware, more efficiently. Bytecode may not be able to make the most of all of those features specific to the hardware.
Technical Performance Factors
The performance gap between bytecode and machine code can be attributed to several technical factors:
- Cache Alignment: Machine code can be optimized for specific CPU cache line sizes (typically 64 bytes), minimizing cache misses. Bytecode execution involves virtual machine overhead that disrupts optimal cache usage patterns.
- Memory Access Patterns: Machine code can be structured to take advantage of CPU prefetching mechanisms that predict and load data before it’s needed. Virtual machines executing bytecode add an indirect layer that complicates these predictive mechanisms.
- Branch Prediction: Modern CPUs optimize execution through branch prediction. Machine code can be arranged to maximize prediction accuracy, while bytecode’s abstraction adds complexity that can lead to more branch mispredictions and pipeline stalls.
- Register Allocation: Machine code compiled for specific architectures can optimize register usage, keeping frequently accessed data in fast CPU registers. Bytecode must work through virtual machine register emulation, adding overhead.
Benchmarking shows these differences clearly: computationally intensive tasks like matrix multiplication can execute 2-5x faster in optimized machine code compared to equivalent bytecode, even with JIT compilation enabled.
How Do Just-in-time Compilers Make Bytecode More Efficient?
Just-in-time compilers can help developers get the best of both worlds: the portability of high-level programming compiled into bytecode with the efficiency of machine code and better optimization of machine-specific features.
AI-Powered Bytecode Optimization
In 2025, machine learning algorithms have revolutionized bytecode optimization through:
- Predictive execution pattern analysis that identifies hotspots and optimizes them aggressively
- Dynamic profiling that adjusts optimization strategies based on real-time execution metrics
- Code vectorization determined by ML models that identify parallelization opportunities invisible to traditional compilers
- Experimental results showing up to 4.5% performance improvements through these AI-driven techniques
Bytecode Tokenization and Pre-trained Models
The rise of bytecode-specific pre-trained models has transformed how we work with bytecode:
- ByteT5 and ByteBERT models are specifically designed for understanding hexadecimal bytecode patterns
- These models can identify optimization opportunities, security vulnerabilities, and code smells directly from bytecode
- Tokenization techniques break bytecode into meaningful semantic units for analysis
- This enables advanced static analysis without execution, improving both performance and security
WebAssembly and the Bytecode Alliance
WebAssembly (Wasm) has emerged as a critical bytecode format that extends beyond browsers:
- The Bytecode Alliance, formed by Mozilla, Microsoft, Google, and others, develops standards and tools for secure WebAssembly execution
- Wasmtime, their first Core Project, provides a standalone runtime for WebAssembly outside browsers
- Long-term support releases ensure stability for production deployments
- WebAssembly System Interface (WASI) extends WebAssembly’s reach to system-level programming
- Near-native performance with portable bytecode creates new possibilities for cross-platform development
Hardware Acceleration for Bytecode
Modern processors have evolved to better support bytecode execution:
- Dedicated instruction sets like Intel’s GenuineIntel feature extensions specifically designed to accelerate virtual machine operations
- Hardware-assisted virtualization technologies (Intel VT-x, AMD-V) reduce bytecode interpretation overhead
- Specialized JIT compilation units in modern CPUs optimize the translation from bytecode to machine code
- CPU cache architectures now include optimizations for common bytecode execution patterns
- These advances have narrowed the performance gap between bytecode and native code execution by up to 35%
Use Cases of Bytecode and Machine Code
What Is Bytecode in Java?
Java is one of the most portable modern programming languages, and bytecode is a fundamental principle of the environment. It’s the use of bytecode that makes Java so portable, and it’s run on the Java Virtual Machine (JVM).
When a Java application is written, it gets compiled and generates bytecode, which provides instructions to the JVM, which acts as an interpreter for each method in the Java program. The machine code it generates can be efficiently executed by the CPU.
Is .NET’s CIL the Same as Bytecode?
Yes. The Common Intermediate Language (CIL) of Microsoft’s .NET programming framework is the same as bytecode, which is also used in Java. .NET, like Java, is considered a “write once, run anywhere” environment, and it uses a compiler to turn source code of .NET languages into CIL instructions. As long as a system has a compatible Common Language Runtime (CLR), the runtime can execute the Java program.
Modern Application Contexts
Bytecode has found new applications in emerging technologies:
- Quantum Computing Bridges: Bytecode serves as an intermediate representation between classical programming models and quantum execution environments
- “Vibe Coding”: Large language models now generate code from natural language, with bytecode serving as a verification layer to ensure correctness before execution
- Edge Computing: Bytecode’s portability makes it ideal for heterogeneous edge computing environments with diverse hardware
- Cross-Platform Development: Modern frameworks rely on bytecode to achieve consistent behavior across mobile, desktop, web, and IoT platforms
What Is the Execution Process for Bytecode vs. Machine Code?
Binary, which consists of 0s and 1s that a computer machine can read, becomes executable code through a series of steps and transformations.
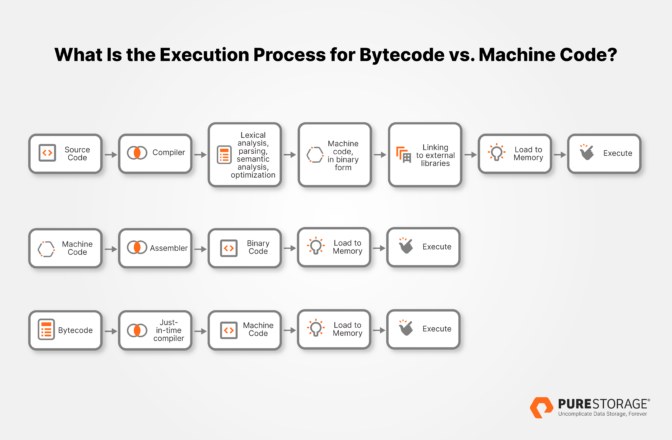
Source Code → Compiler (Lexical analysis, parsing, semantic analysis, optimization) → Machine code, in binary form → [Linking to external libraries] → Load to Memory → Execute
Machine Code → Assembler → Binary code → Load to memory → Execute
Bytecode → Just-in-time compiler → Machine code → Load to memory → Execute
With either process, during runtime, the binary code directly interacts with the hardware, executing the software’s commands, whether it’s running calculations, accessing computer memory, or anything else the program needs it to do.
Security Implications
Technical Analysis of Attack Vectors
Bytecode execution environments present unique security challenges:
- Type confusion attacks exploit vulnerabilities in bytecode verification
- Deserialization vulnerabilities allow bytecode injection through manipulated object streams
- Just-in-Time spraying techniques can bypass memory protection mechanisms
Detailed sandboxing mechanisms protect against these threats through:
- Control flow integrity verification that ensures execution follows valid paths
- Memory access boundary enforcement through hardware-level protections
- Object capability models that restrict operations based on permission policies
Compared to direct machine code execution, bytecode provides stronger security guarantees through its verification processes but introduces new attack surfaces through its execution environment.
Conclusion
The latest polymorphic and metamorphic malware can rewrite their own code at the bytecode level to evade the conventional pattern recognition and signature detection techniques of antivirus software. The morphed code can still compile to the machine code needed to execute its nefarious ends. In a world of ever-evolving cyber threats, your ability to recover your data and get back up and running as soon as possible is more important than ever before. Watch this video to learn more about how SafeMode™ Snapshots can protect your data from the most sophisticated cyberattacks.
As we look to the future, the line between bytecode and machine code continues to blur with advancements in hardware acceleration, AI-driven optimization, and specialized execution environments. Understanding these fundamentals becomes even more crucial as software development embraces new paradigms like quantum computing and AI-assisted programming. By mastering these concepts, developers and organizations can make informed decisions about performance, security, and portability trade-offs in their technology stack.