This article on how to build an open data lakehouse was originally published on Medium. the blog has been republished with the author’s credit and consent.
Data lakes represent the first step towards gaining insights from ever-growing data. In many cases, it is the first place collected data lands in the data system.
A data lake creates two challenges:
- Data quality and governance. Everything is just a file/object in a data lake.
- Performance. Limited query optimisation, such as metadata, indexing, etc.
On the other hand, when it comes to data warehouses, often time is the final destination of analytical data. Data in a data warehouse may come from the data lake or directly from the sources. Data warehouse challenges include:
- Limited support for unstructured data
- Performance for machine learning. SQL over ODBC/JDBC is not efficient for ML. ML needs direct access to data in an open format.
Enter the data lakehouse. A data lakehouse system tries to solve these challenges by combining the strengths of data lakes and data warehouses. Key features of a data lakehouse include:
- Designed for both SQL and machine learning workloads
- ACID transactions
- Partition evolution
- Schema evolution
- Time-travel query
- Near data warehouse performance
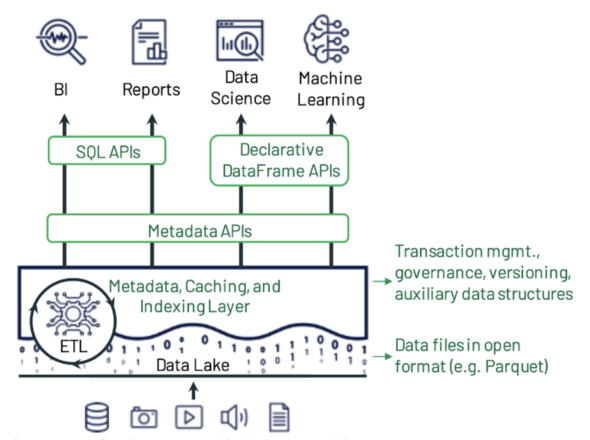
Example data lakehouse system design from the paper by Michael Armbrust, Ali Ghodsi, Reynold Xin, and Matei Zaharia.
Implementing a Data Lakehouse
Key components in a data lakehouse implementation include:
- Leveraging an existing data lake and open data format. Table data is typically stored as Parquet or ORC files in HDFS or an S3 data lake.
- Adding metadata layers for data management. Popular open source choices include Delta Lake, Apache Iceberg, and Apache Hudi. They typically store metadata in the same data lake as JSON or Avro format and have a catalog pointer to the current metadata.
- Having an analytics engine that supports the data lakehouse spec. Apache Spark, Trino, and Dremio are among the most popular ones.
Below, I will explain my process of implementing a simple data lakehouse system using open source software. This implementation can run with cloud data lakes like Amazon S3, or on-premises ones such as Pure Storage® FlashBlade® with S3.
Getting Ready for a Data Lakehouse
To implement a data lakehouse system, we first need to be familiar with and ready for the data lake and data warehouse. In my case, I have already set up my FlashBlade S3 data lake, Spark, and Trino data warehouse.
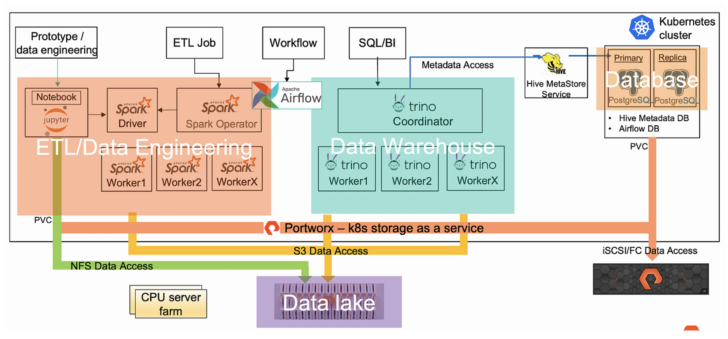
My data lake and warehouse setup.
Refer to my previous blog posts for details of the above setup:
- Apache Spark with Kubernetes and Fast S3 Access
- Trino (formerly Presto) with Kubernetes and S3—Deployment
- Running Spark on Kubernetes: Approaches and Workflow
Adding Open Data Lakehouse Metadata Management
One thing that is missing in my previous setup is the metadata management layer for the data lakehouse. I choose Delta Lake for this because it is easy to get started, has less dependency on Hadoop and Hive, and its documentation is good.
Delta Lake is implemented as Java libraries. Only four jars are required to add Delta Lake to an existing Spark environment: delta-core, delta-storage, antlr4-runtime, and jackson-core-asl. Download these jars from Maven repo, and add them under the $SPARK_HOME/jars directory. Because I run Spark on Kubernetes, I add these jars into my Spark container image.
Next, I add the following configurations to my Spark session, so that Spark will use the Delta catalog and its SQL extension.
|
1 2 3 |
<span style=“font-weight: 400;”>spark.sql.extensions=io.delta.sql.DeltaSparkSessionExtension</span> <span style=“font-weight: 400;”>spark.sql.catalog.spark_catalog=org.apache.spark.sql.delta.catalog.DeltaCatalog</span> |
That’s all we need for Delta Lake and Spark integration.
Data Lakehouse with Delta Lake and Spark
Now let’s demonstrate some data lakehouse features with Delta Lake and Spark.
Save a Spark dataframe in Delta format:
|
1 |
<span style=“font-weight: 400;”>df.write.format(‘delta’).mode(‘overwrite’).save(‘s3a://warehouse/nyc_delta.db/tlc_yellow_trips_2018_featured’)</span> |
This writes both the Parquet data files and Delta Lake metadata (JSON) in the same FlashBlade S3 bucket.
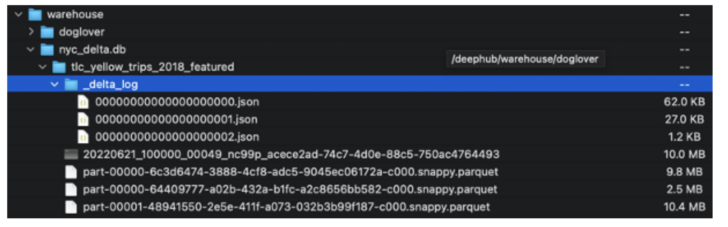
Delta Lake data and metadata in FlashBlade S3.
To read back Delta Lake data into Spark dataframes:
|
1 2 3 |
<span style=“font-weight: 400;”>df_delta = spark.read.format(‘delta’).load(‘s3a://warehouse/nyc_delta.db/tl c_yellow_trips_2018_featured’)</span> |
Delta Lake provides programmatic APIs for conditional update, delete, and merge (upsert) data into tables.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
<span style=“font-weight: 400;”>from delta.tables import *</span> <span style=“font-weight: 400;”>from pyspark.sql.functions import *</span> <span style=“font-weight: 400;”>delta_table = DeltaTable.forPath(spark, ‘s3a://warehouse/nyc_delta.db/tlc_yellow_trips_2018_featured’)</span> <span style=“font-weight: 400;”># Update fare_amount by adding 1 to it</span> <span style=“font-weight: 400;”>delta_table.update(</span> <span style=“font-weight: 400;”> condition = expr(‘trip_duration == 15 and trip_distance == 2.7’),</span> <span style=“font-weight: 400;”> set = {‘fare_amount’: expr(‘fare_amount + 1’)})</span> |
Transaction is not easy, if possible, in a data lake, but is built-in with a data lakehouse. Transactions create snapshots. I can query previous snapshots of my Delta table by using time travel queries. If I want to access the data that has been overwritten, I can query a snapshot of the table before I overwrote the first set of data using the versionAsOf option.
|
1 2 3 |
<span style=“font-weight: 400;”># Read older versions of data using time travel queries</span> <span style=“font-weight: 400;”>df_features = spark.read.format(‘delta’).option(‘versionAsOf’, 0).load(‘s3a://warehouse/nyc_delta.db/tlc_yellow_trips_2018_featured’)</span> |
I can also retrieve a Delta table history like this:
|
1 2 3 4 5 6 7 |
<span style=“font-weight: 400;”>from delta.tables import *</span> <span style=“font-weight: 400;”>features_table = DeltaTable.forPath(spark, ‘s3a://warehouse/nyc_delta.db/tlc_yellow_trips_2018_featured’)</span> <span style=“font-weight: 400;”>full_history = features_table.history()</span> <span style=“font-weight: 400;”>full_history.show()</span> |

Delta table versions.
SQL on Data Lakehouse
While Spark is great for general ETL with its DataFrame APIs, SQL is preferred for advanced analytics and business intelligence. Below, I add data lakehouse support to my existing Trino data warehouse using the Trino Delta Lake connector.
To configure the Delta Lake connector, add the following to the catalog/delta.properties file, and restart Trino.
|
1 2 3 4 5 6 7 8 9 |
<span style=“font-weight: 400;”>hive.metastore.uri=thrift://metastore:9083</span> <span style=“font-weight: 400;”>hive.s3.endpoint=</span><a href=“https://192.168.170.22/” target=“_blank” rel=“noopener”><span style=“font-weight: 400;”>https://192.168.170.22</span></a> <span style=“font-weight: 400;”>hive.s3.ssl.enabled=false</span> <span style=“font-weight: 400;”>hive.s3.path–style–access=true</span> <span style=“font-weight: 400;”>delta.enable–non–concurrent–writes=true</span> |
With this, Trino can understand the Delta spec, query, and update the above Spark Delta format output.
Connect to Trino Delta catalog:
|
1 |
<span style=“font-weight: 400;”>trino–cli —server trino:8080 —catalog delta</span> |
Create a Delta table in Trino, and query the data.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
<span style=“font-weight: 400;”>USE nyc_delta;</span> <span style=“font-weight: 400;”>CREATE TABLE IF NOT EXISTS delta.nyc_delta.tlc_yellow_trips_2018_featured (</span> <span style=“font-weight: 400;”> fare_amount DOUBLE,</span> <span style=“font-weight: 400;”> trip_distance DOUBLE,</span> <span style=“font-weight: 400;”> trip_duration INTEGER,</span> <span style=“font-weight: 400;”> passenger_count INTEGER,</span> <span style=“font-weight: 400;”> pickup_year INTEGER,</span> <span style=“font-weight: 400;”> pickup_month INTEGER,</span> <span style=“font-weight: 400;”> pickup_day_of_week INTEGER,</span> <span style=“font-weight: 400;”> pickup_hour_of_day INTEGER</span> <span style=“font-weight: 400;”>)</span> <span style=“font-weight: 400;”>WITH (LOCATION = ‘s3a://warehouse/nyc_delta.db/tlc_yellow_trips_2018_featured’)</span> <span style=“font-weight: 400;”>;</span> <span style=“font-weight: 400;”>SELECT * FROM tlc_yellow_trips_2018_featured LIMIT 10;</span> <span style=“font-weight: 400;”>Update Trino Delta table (require </span><span style=“font-weight: 400;”>delta.enable–non–concurrent–writes</span><span style=“font-weight: 400;”> set to </span><span style=“font-weight: 400;”>true</span><span style=“font-weight: 400;”>):</span> <span style=“font-weight: 400;”>update tlc_yellow_trips_2018_featured set fare_amount=20.0 where trip_duration = 15 and trip_distance=3.74;</span> |
Note that updates, or transactions in general, are not supported in classic Trino tables on S3. To update even just one row in a table, we need to repopulate the entire partition or table. With transaction support in a Trino Delta table, this becomes much easier as shown above. Transactions are first stored in the _delta_log directory and later merged back to the base Parquet files in the backend.
![]()
An example Delta log including a delete operation.
I also want to stress that, although ACID transaction is normally a built-in feature for data lakehouse systems, this is not meant to be used for general OLTP purposes. Transactions in a data lakehouse system should be infrequent.
As of the time of this blog post, Trino’s Delta Lake connector supports common Delta/Trino SQL type mapping and common queries, including select, update, and so on. Advanced Delta features, such as time travel queries, are not supported yet. For those features, use the APIs from the Delta Lake library.
Conclusion
In this blog post, I explained how to build an open data lakehouse on top of an existing data lake and warehouse system. The technologies I use here are either open source or open standard, so they can be deployed anywhere.
As data lakehouse architectures are getting more and more popular, I started to hear from customers asking about data lakehouse performance. I will write about this and why fast object storage like FlashBlade with S3 is important in a data lakehouse in a follow-up blog post.
![]()



