
In an era where milliseconds can determine market leadership, enterprises face a critical challenge: transforming vast data repositories into actionable intelligence with unprecedented speed and accuracy. Enterprises, hyperscalers, and neoclouds like Meta and Coreweave customers have found resounding success with FlashBlade//S™ and the Pure Storage platform for many of their AI workload needs. With multiple NVIDIA-certified storage validations, customers can be confident that their AI infrastructure deployment will be fast and smooth.
For large-scale customers with sophisticated AI inference requirements, the NVIDIA AI Data Platform reference design implemented with Pure Storage® FlashBlade//EXA™ and Portworx® redefines how organizations can turn massive volumes of data into real-time intelligence. This comprehensive stack doesn’t just accelerate inference—it unlocks precision reasoning at scale, enabling large-scale enterprises to decode complex data sets with surgical accuracy while maintaining production-grade security.
The Intelligence Imperative: Why Speed and Precision Matter
Modern enterprises operate in environments where delayed insights equate to missed opportunities. A Pure Storage implementation of the NVIDIA AI Data Platform addresses this by combining accelerated computing with intelligent data orchestration, creating a feedback loop between enterprise knowledge and AI reasoning. At its core, this infrastructure enables:
- Real-time analysis of multimodal data (text, images, video) with sub-second latency
- Context-aware reasoning across distributed data sets
- Trusted insights and data governance through granular security controls
By leveraging accelerated compute through NVIDIA Blackwell, NVIDIA networking, retrieval-augmented generation (RAG) software, including NVIDIA NeMo Retriever microservices and the AI-Q NVIDIA Blueprint, and the metadata-optimized architecture of Pure Storage, organizations reduce time to insight from days to seconds while maintaining very high inference accuracy in production environments.
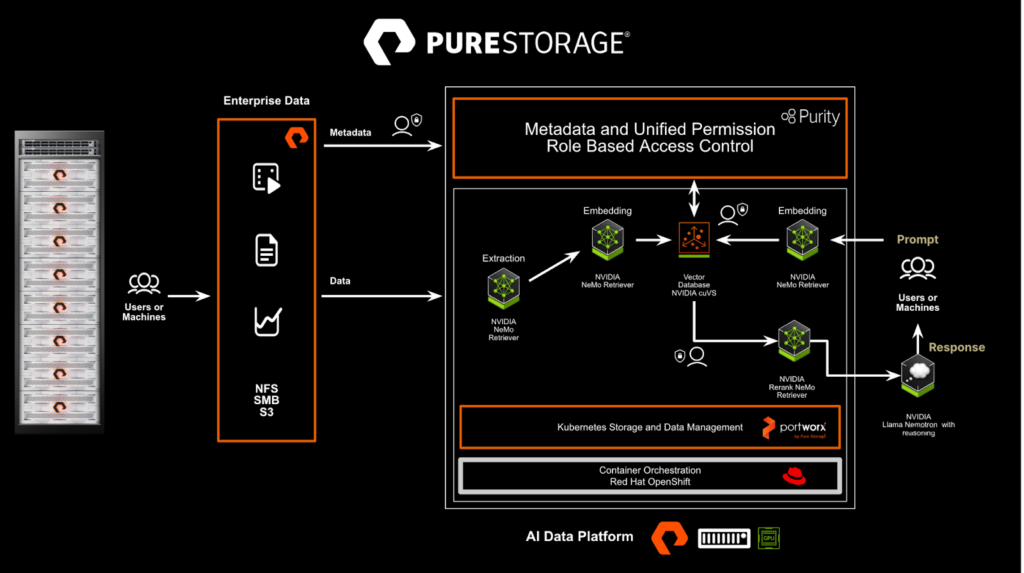
Figure 1. Pure Storage implementation of the NVIDIA AI Data Platform.
FlashBlade//EXA: The Data Velocity Engine
Pure Storage FlashBlade//EXA shatters traditional storage bottlenecks with 10+ TB/s throughput performance in a single namespace—enough to process the entire collection of the Library of Congress in under three minutes.
How Disaggregation of Data and Metadata Nodes Enables Massive Inference at Scale
The key advantage of the disaggregated design of FlashBlade//EXA is the ability to scale metadata and data performance independently. This means organizations can precisely match their storage architecture to the specific demands of their inference workloads without overprovisioning either component.
For inference workloads that require rapid access to thousands or millions of smaller files, the metadata layer can be scaled appropriately. Similarly, for workloads dealing with massive data sets consisting of huge files, the data layer can be expanded without unnecessary metadata overhead. This flexibility enables “virtually infinite scalability.”
The segregation of metadata and data processing provides non-blocking data access that becomes increasingly valuable in high-performance computing scenarios where metadata operations can equal or even exceed actual data I/O operations. This architecture ensures that GPUs are consistently fed with data at the highest possible rates, eliminating costly idle time.
With its disaggregated, massively parallel architecture, FlashBlade//EXA solves the problem of scaling up AI workloads, eliminating idle GPU time, so enterprises can accelerate AI training and inference. This efficient data delivery is crucial for inference workloads where consistent, predictable performance is often more important than peak speeds, which is made possible by efficient KV cache sharing for bursty and mixed workloads.
The Portworx and FlashBlade//EXA Synergy for Inference Acceleration
The synergy between Portworx and FlashBlade//EXA accelerates AI inference at scale by combining Portworx Kubernetes-native data management and intelligent model caching with FlashBlade//EXA ultra-fast, massively parallel storage architecture. Portworx ensures high availability, low-latency access, and seamless scaling of model data across distributed inference workloads, while FlashBlade//EXA eliminates storage and metadata bottlenecks with exceptional throughput and disaggregated scaling. Together, they maximize GPU utilization, minimize inference latency, and provide a robust, flexible foundation for deploying and managing AI inference pipelines in production environments.
The Disaggregated KV Cache Revolution: Precision at Scale
NVIDIA’s FlowKV architecture reimagines inference pipelines through three innovations:
- Near-GPU prefix caching
- Stores common query patterns (e.g., regulatory compliance checks) directly in GPU-adjacent NVMe
- Load-aware scheduling
- Dynamically allocates prefill/decode resources based on query complexity
- Maintains 95% GPU utilization even during traffic spikes
- Heterogeneous GPU pooling
- Enables mixed GPU variant clusters to share KV cache memory
This Pure Storage solution complements the above with the following features to provide end-to-end speed up in tokens-per-second performance for large-scale AI Inference deployments.
- KV cache sharing: Ensures efficient KV cache sharing amongst the exponentially multiplying herd.
- High IO concurrency: The highly concurrent architecture of FlashBlade® is not only ultra-fast but also excels in this exponentially concurrent IO pattern.
- Data reduction: Automatic compression of KV cache means faster IO and shorter prefill times.
Security as an Enabler: RBAC for Trusted Insights in RAG and Agentic AI
Implementing a role-based access control (RBAC) framework within a retrieval-augmented generation (RAG) or agentic pipeline is critical for secure and efficient data handling. This involves establishing a unified permission layer to define user roles and their access rights across various stages: data ingestion, retrieval, processing, and storage. Additionally, the components must support efficient query understanding to tailor data access based on user roles and intents, ensuring compliance with set permissions. The AI augmentation and generation processes must integrate context-specific data within generative models while maintaining security and access protocols. Effective audit and monitoring mechanisms are crucial for tracking access patterns and ensuring adherence to RBAC rules, boosting overall security. Security best practices, such as employing a zero-trust model and JWT-based authentication, emphasize transient and secure access controls while minimizing performance impacts on the pipeline.
Portworx implements a zero-trust security model that accelerates rather than inhibits data access:
- StorageClass granular encryption: Encrypts sensitive PII in flight and at rest while keeping training data accessible
- JWT-based access control: Grants temporary, context-aware access to RAG pipelines
- Audit-compliant logging: Tracks data lineage from raw ingestion to inference output
NVIDIA AI-Q: The Reasoning Intelligence Layer
The AI-Q NVIDIA Blueprint transforms static data into dynamic knowledge through three core components:
- Multimodal extraction engines: Converts PDF schematics, service manuals, and call transcripts into structured knowledge graphs
- NeMo Retriever microservices: Delivers extremely high recall accuracy on billion-scale vector searches
- NVIDIA Agent Intelligence toolkit orchestration: Profiling and optimization for complex agentic systems
When combined with the data velocity of FlashBlade//EXA, this stack enables what we term “precision reasoning”—the ability to derive boardroom-ready insights from raw data in very few query cycles.
Power Precision Reasoning at Scale: The New Competitive Edge
Enterprises adopting this stack report transformative outcomes.
A Pure Storage implementation of the NVIDIA AI Data Platform provides the ultimate in reasoning density—the ability to extract more actionable insights per terabyte processed. By combining NVIDIA Blackwell accelerated computing with the data accessibility of Pure Storage, organizations achieve what was previously unthinkable: turning their entire data estate into a strategic reasoning asset.
Conclusion: Intelligence at the Speed of Business
The Pure Storage-NVIDIA collaboration represents more than just extreme-scale AI infrastructure—our long history of collaboration ensures customers of all sizes and AI maturity can be supported, whether they’re just starting out with FlashBlade//S or AIRI® or scaling to the highest level of AI and HPC requirements.
As AI transitions from experimental project to core revenue driver, this platform provides the foundation for continuous intelligence—the ability to reason, decide, and act on live data streams with machine precision. The future belongs to enterprises that don’t just store data, but understand it at the speed of thought.
Learn more: