


This article originally appeared on Medium.com. It has been republished with permission from the author.
Recently a FlashBlade® customer had a challenge with listing all custom metadata on objects in a large bucket. A standard S3 LIST request does not return custom metadata; therefore, the task requires also issuing a HEAD request for each object. With millions of objects in a bucket, the naive Python approach was serialized and therefore painfully slow. The FlashBlade backend is an all-flash object store designed for high throughput and metadata performance, so the question naturally became how to better utilize the storage backend to complete the requests faster.
By rewriting the code in a compiled language with more concurrency, the performance improved at least 50x compared to the naive Python implementation and 4x versus the parallelized Python version.
This blog covers:
- The performance gain (requests/sec) of Go and Rust relative to Python.
- How to use FlashBlade as an S3 endpoint when coding in Python, Go, or Rust.
- Basic concurrency patterns in these languages.
Writing performant and correct asynchronous code is hard. Inevitably, many threads need to concurrently access and modify shared state, leading to lots of nasty bugs.
While Python is the easiest language to work in in general, it’s subtle and difficult to write performant, parallelized Python code. In contrast, Go and Rust make writing concurrent code relatively easier. In fact, writing concurrent Go code is no harder than writing single-threaded Go code, which is unsurprising given the language’s design goals. Writing concurrent Rust is more challenging, but correctness is mostly baked-in, unlike the equivalent C++ code (unless coroutines eventually save the day!). Go and Rust both have significantly better writability/performance trade-offs than Python.
Results
Go and Rust are faster because they are modern compiled languages, whereas Python is an interpreted language with limited concurrency due to the use of a global interpreter lock (GIL). The best parallelized Python result was still 3x and 4x slower than the Go and Rust versions.
And unsurprisingly, the naive single-threaded Python implementation is two orders of magnitude slower than the Go and Rust versions (50x and 65x difference respectively).
It was surprising to me, though, that Rust was 30% faster than Go in this embarrassingly parallel and straightforward workload. Further, the Rust binary used ~18% less CPU than the Go binary and 3x less CPU than the Python multi-process version.
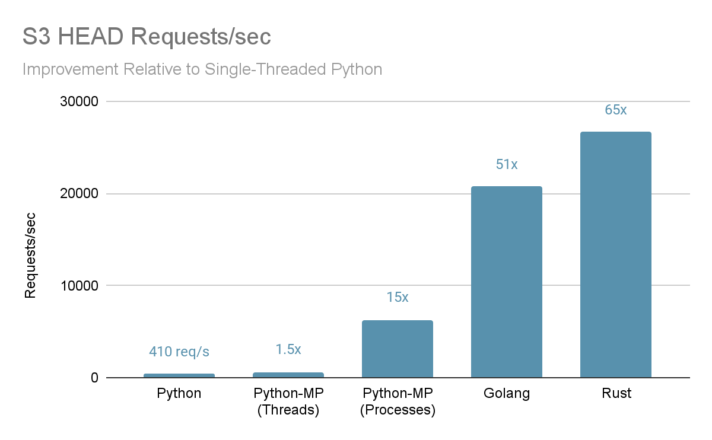
In all of these tests, the HEAD object latencies are consistently between 0.50ms–1.0 ms, indicating that the backend FlashBlade system is not overloaded. Synthetic benchmarking shows that the FlashBlade system can service at least 10x the highest request rate given multiple clients.
Code Walkthroughs
One of the key challenges with this concurrency example is the need to scale to billions of objects in a large bucket. This means spawning a new thread or process per object is inefficient.
In some ways, this is an “easy” concurrency problem because each concurrent task issues a HEAD object request and then prints to stdout any custom metadata. No data needs to be returned from each task; therefore, there is no need to track pending results and aggregate returned data. We only need to ensure that all pending requests complete before finishing the program.
There are almost certainly ways to improve performance on each of these examples, but I have tried to keep programming effort constant across these programs. I would consider myself an average Python and Go programmer and an inexperienced Rust programmer. But I have spent several years writing performant and highly asynchronous C++ code, so I am always looking for languages that ease the pain of writing concurrent code.
Python Baseline
First, I introduce the basic Python elements that make up the single-threaded implementation in Python. This program retrieves object listings in groups of 1,000 (default value) and then sequentially issues HEAD requests to each object before moving on to the next LIST request. There is only ever one outstanding request, LIST or HEAD, at a time.
First, install boto3:
pip install boto3
Configure the s3 client to access the FlashBlade device’s data VIP (10.62.64.200 in my example):
import boto3
FB_DATAVIP='10.62.64.200'
Next, the following code lists all objects in a bucket using the ContinuationToken to retrieve pages of 1,000 keys per request:
while True:
objlist = s3.meta.client.list_objects_v2(**kwargs)
keys = [o['Key'] for o in objlist.get('Contents', [])]
for key in keys:
check_for_custom_metadata(s3, bucketname, key)
try:
kwargs['ContinuationToken'] = objlist['NextContinuationToken']
except KeyError:
break
Note that there are helpers which simplify the listing code above, but I leverage this per-page logic later for concurrency. Finally, a head_object() request retrieves any custom metadata:
def check_for_custom_metadata(s3, bucketname, key):
response = s3.meta.client.head_object(Bucket=bucketname, Key=key)
if response['Metadata']:
print("{} {}".format(key, response['Metadata']))
Python Multiprocessing
To issue the HEAD requests concurrently, I utilize the Python multiprocessing library. There are two ways to run Python multiprocessing: threads or separate processes. A ThreadPool creates multiple threads of execution within the same process, but those threads are still subject to GIL requirements of only a single thread executing code. This means concurrent network requests can be issued, but processing is limited to a single thread. In contrast, process-level concurrency creates independent processes, each with its own GIL, enabling true concurrency at the cost of making information sharing between processes more challenging.
To utilize multiple threads, I create a ThreadPool and use apply_async() to asynchronously execute each head request. The below code augments the previous listing code:
import multiprocessing
p = multiprocessing.pool.ThreadPool(multiprocessing.cpu_count())
… # same listing logic as above
keys = [o['Key'] for o in objlist.get('Contents', [])]
# start HEAD operations asynchronously
for k in keys:
p.apply_async(check_for_custom_metadata, (s3, bucketname, k))
Due to the GIL, threading in Python gives a relatively small speedup (1.5x) and so we must use process-level concurrency. The core challenge moving to process-level concurrency is that the s3 client has internal state and cannot be shared across multiple processes. This means we need a way to ensure that each process has its own s3 client, but since this is an expensive operation, we want this to only happen once per process. When creating a new process, we can pass in a custom initialization function like this:
# make a per process s3_client
s3_client = None
def initialize():
global s3_client
s3_client = boto3.resource('s3', \
aws_access_key_id=AWS_KEY, \
aws_secret_access_key=AWS_SECRET, \
use_ssl=False, endpoint_url='https://' + FB_DATAVIP)
And now the “check_for_custom_metadata()” function uses the global variable for the s3 client instead of a passed argument.
The process pool version then looks almost identical to the threading version.
import multiprocessing
p = multiprocessing.Pool(multiprocessing.cpu_count(), initialize)
… # Listing logic repeated here
keys = [o['Key'] for o in objlist.get('Contents', [])]
# Start async HEAD ops and then continue listing.
for k in keys:
p.apply_async(check_for_custom_metadata, (bucketname, k))
Finally, note that both the multiprocessing versions need to wait after the list operation completes so that all outstanding HEAD requests complete before exiting.
p.close()
p.join()
The challenge of Python multiprocessing is sharing state across processes as even this one-way example demonstrates. And unfortunately, even with this effort, the performance is far below what is possible.
The complete Python multiprocessing code can be found here.
Go: Goroutines and Channels
The two Go primitives that enable “easy mode” concurrent programming are goroutines and channels.
“A goroutine is a lightweight thread of execution.”
“Channels are the pipes that connect concurrent goroutines.”
A first attempt might be to spawn a new goroutine for each head request, but this does not scale to large buckets with millions of objects due to the way that the S3 SDK creates TCP connections for each goroutine. In my testing, this resulted in slow performance and running out of available TCP ports. There are many other concurrency scenarios where creating a new goroutine per task is sufficient, like an HTTP server handling requests.
The option I implemented instead was to create a small number of “worker” goroutines, each of which retrieves object keys from a channel and issues HEAD requests. A separate goroutine lists objects and adds them to the shared channel. The number of workers limits the amount of concurrency in the system, which is necessary to scale to billions of objects. The channel is a work queue in this scenario, as shown in the diagram below.

The full code for the Go version can be found here.
Connecting to FlashBlade S3
Import the following in order to use the AWS SDK:
import (
"github.com/aws/aws-sdk-go/aws"
"github.com/aws/aws-sdk-go/aws/awserr"
"github.com/aws/aws-sdk-go/aws/session"
"github.com/aws/aws-sdk-go/service/s3"
)
First, configure the s3 client to connect to a FlashBlade device based on endpoint which points to the FlashBlade data VIP.
endpointUrl := "https://10.62.64.200"
s3Config := &aws.Config{
Region: aws.String("us-east-1"), // ignored
DisableSSL: aws.Bool(true),
S3ForcePathStyle: aws.Bool(true),
HTTPClient: httpClient,
}
if endpointUrl != "" {
s3Config.Endpoint = &endpointUrl
}
sess := session.Must(session.NewSession(s3Config))
svc := s3.New(sess)
The region can be set to any valid value as it will not be used for FlashBlade connections. Disabling SSL is optional and not recommended for production environments with proper certificates installed on the FlashBlade device. Note the HTTPClient setting, which I will discuss later in the section on TCP connection reuse.
Concurrency Logic
The following function lists the keys in a bucket using ListObjectsPages, which is a paginated helper that hides the continuation logic. This function takes a function object to be called with the result of each page of 1,000 returned keys. In this case, each key is added to the shared channel.
func listToChannelAndClose(svc *s3.S3, bucketname *string, pfix string, channel chan string) {
err := svc.ListObjectsPages(&s3.ListObjectsInput{
Bucket: bucketname,
Prefix: &pfix,
}, func(p *s3.ListObjectsOutput, _ bool) (shouldContinue bool) {
for _, v := range p.Contents {
channel <- *v.Key
}
return true
})
reportAWSError(err)
close(channel)
}
Once the listing is completed, the channel is closed, indicating no more values will be sent.
The main routine creates the channel and then starts the listing operation in a separate thread using the function just described. This channel needs an explicit size of more than 1,000 so that the next list request can start before all head_object requests have completed. If the channel fills up, the sender will block temporarily until more head requests have completed.
channel := make(chan string, 2048)
go listToChannelAndClose(svc, &bucketname, prefix, channel)
A fixed number of worker goroutines will read keys from the shared channel and issue HeadObject requests.
var wg sync.WaitGroup
workerFunc := func() {
defer wg.Done()
for k := range channel {
input := &s3.HeadObjectInput{
Bucket: &bucketname,
Key: &k,
}
res, err := svc.HeadObject(input)
reportAWSError(err)
if len(res.Metadata) > 0 {
printMetadata(k, res.Metadata)
}
}
}
The main program needs to wait to exit until all the work is done. This is done in two phases: first, once the listing is completed, the channel is “closed.” Each worker goroutine will continue reading keys from the channel and then exit once the channel is exhausted. A WaitGroup tracks all outstanding workers and holds up completion of the main thread until all the work is done.
The last section of code starts the worker goroutines and then waits for each to finish:
workerCount := 2 * runtime.NumCPU()
wg.Add(workerCount)
for i := 0; i < workerCount; i++ {
go workerFunc()
}
wg.Wait()
The workerCount variable was originally set to the number of cores (16 in my case), but I found the 2x increase in goroutines to yield 6% higher requests/sec.
Sidebar: TCP Connection Reuse
This high request rate workload triggers port number exhaustion due to the default way TCP connections are poorly reused. Briefly, the S3 SDK by default keeps the open connection pool far too small, only allowing two idle connections.
In AWS, there is a limit of 5,500 HEAD requests/sec, so the TCP connection reuse issue is much less likely to arise. In contrast, FlashBlade imposes no per-client limitations and has orders of magnitude higher metadata performance in even the smallest configurations. Similarly, my Python programs have not experienced this issue due to their far lower requests/sec rate.
To alleviate TCP port number exhaustion, the above code creates a custom HTTP client for the AWS SDK via these instructions. Set the MaxHostIdleConns to a much higher number (e.g., 100) than the default value of 2 so that connections will be reused instead of quickly closed.
Rust: Tokio
Rust provides concurrency primitives async and await. With these, concurrent code can be written similarly to single-threaded code yet still executed with high concurrency. First, the compiler transforms async code blocks into future structures, and second, a “runtime” is required to run a future object and make progress.
Asynchronous Rust code does not run without a runtime, and Tokio is the most widely used async runtime in the Rust ecosystem.
Rust futures are very different from Goroutines or threads. Instead of each future mapping to a thread, Tokio runs a set of threads that poll and advance futures until they complete. Calling an async function does not execute code, but rather creates a future that needs to be given to the Tokio runtime for execution.
The following code example opens and reads a file. The two “.await?” calls indicate to yield if the results are not ready yet, letting the runtime schedule another future instead.
let mut f = File::open("foo.txt").await?;
let mut buffer = [0; 10];
let n = f.read(&mut buffer[..]).await?;
So instead of arranging callbacks to asynchronously respond when the file open returns or when the read completes, the logic is kept together in a block that has almost the same readability as a blocking, single-threaded version. Better readability of asynchronous code means fewer bugs.
Spawning Tokio tasks is a lightweight operation relative to spawning Goroutines. As a result, we can create a task for each key, whereas we could not efficiently create a goroutine per key.
Asynchronous Rust programming is a complex and involved topic; this is only a basic introduction. The full Rust example code can be found here.
Connecting to FlashBlade S3
I use the AWS SDK for Rust, which is currently in developer preview and not yet ready for production use. There are other widely used community implementations, rust-s3 and rusoto, but I use the AWS SDK in anticipation of it growing in importance.
First, my Cargo.toml contents:
[dependencies]
aws-config = “0.6.0”
aws-sdk-s3 = “0.6.0”
aws-endpoint = “0.6.0”
tokio = { version = “1”, features = [“full”] }
http = “0.2”
futures = “0.3”
awaitgroup = “0.6”
Next, configure an S3 client to connect to the FlashBlade S3 endpoint. As with other examples, the endpoint needs to point to the FlashBlade data VIP and the region needs to be valid but is otherwise ignored.
let endpoint = "https://10.62.64.200";
let region = Region::new("us-west-2"); // Value ignored
// load S3 access and secret keys from environment variables
let conf = aws_config::load_from_env().await;
let ep = Endpoint::immutable(Uri::from_static(endpoint));
let s3_conf = aws_sdk_s3::config::Builder::from(&conf)
.endpoint_resolver(ep)
.region(region)
.build();
let client = Client::from_conf(s3_conf);
Concurrency Logic
The Rust listing loop is similar to the Python structure in the use of a continuation token, and it creates a new task for the head_request() operation for each key.
let mut wg = WaitGroup::new();
let mut continuation_token = String::from("");
loop {
let resp = client.list_objects_v2().bucket(bucket).prefix(prefix).continuation_token(continuation_token).send().await?;
for object in resp.contents().unwrap_or_default() {
let key = object.key().unwrap_or_default();
… // start new task here
}
if resp.is_truncated() {
continuation_token = resp.next_continuation_token().unwrap().to_string();
} else {
break;
}
}
The middle of this loop dispatches a new task for each key returned, where the task issues a head_object() request using spawn().
…
let req = client.head_object().bucket(bucket).key(key).send();
let worker = wg.worker();
tokio::spawn(async move {
let resp = match req.await {
Ok(r) => r,
Err(e) => panic!("HeadObject Error: {:?}", e),
};
let info = resp.metadata().unwrap();
for (key, value) in info.iter() {
println!("{}: {}", key, value);
}
worker.done();
});
…
Note that spawn returns a handle that can be used to retrieve results, but we ignore that since the output goes to stdout.
The WaitGroup “worker()” call tracks the number of outstanding tasks. This mechanism keeps an effective reference count of all outstanding tasks so that the main thread can wait before exiting.
wg.wait().await;
Ok(())
}
Unlike Python or Go, Rust by default compiles a debug release and so it’s important to compile with the “–release” flag for performance, otherwise requests/sec is significantly lower (roughly 3x faster with release mode).
Summary
Writing applications that leverage concurrency effectively is a challenge. As an example, to issue HEAD requests for every object in a large bucket requires an application to juggle many concurrent in-flight operations. This is especially true with a backend like FlashBlade capable of handling hundreds of thousands to millions of concurrent requests per second.
I compared concurrent implementations of this example program written using Python multiprocessing, Go, and Rust. Both Go and Rust produce significantly better requests/sec performance than concurrent Python (3x and 4x faster respectively). Surprisingly, Rust is 30% faster than Go, despite this being the first concurrent Rust program that I have written. And unsurprisingly, Go clearly wins in the writability and readability of concurrent code.
I then walked through two interesting elements of each program: 1) how to configure an S3 client to connect to a FlashBlade device via endpoint override and 2) the pattern used to generate the concurrency in each language. My hope is that these code examples are educational to others hoping to write high-performance S3 applications.

Written By:



