
This article originally appeared on Medium.com. It has been republished with permission from the author.
Many scale-out data tools, like noSQL databases, expand cluster capacity by either adding new nodes or new drives within each node. These applications were built for direct-attached storage, where adding storage to a node was labor intensive and space-limited. Modern architectures disaggregate compute and storage, making it easy to scale out and increase available storage when needed.
Modernizing these scale-out analytics applications to a Kubernetes environment (example: ECK operator) requires pre-allocated storage for each pod. But in Kubernetes, pods and containers are usually ephemeral and not tied to specific physical node. Requiring local storage for a pod restricts Kubernetes’ ability to schedule pods efficiently. As a result, a disaggregated storage system enables applications to better take advantage of scalability and self-healing functionality of Kubernetes. For example, a pod can be restarted on a different physical compute node, re-attach to the same storage volume, and therefore move without needing to rebalance data.
Kubernetes also simplifies and automates storage administration through PersistentVolumeClaims and CSI plugins like the Pure Service Orchestrator. This post focuses on how to use a new CSI feature volume resizing, which allows online expansion of storage volumes.
Though many applications can benefit from this new feature, I will focus on Elasticsearch as I am a frequent user.
CSI Volume Expansion
Kubernetes CSI volume expansion allows online growth of existing persistentVolumes that were dynamically provisioned. This means volumes in-use can be dynamically grown, though not shrunk. CSI volume expansion is a beta feature starting in Kubernetes v1.16.
The Pure Service Orchestrator is a CSI-compliant plugin from Pure Storage that implements the volume expansion API as of version 5.2.
To expand a volume, issue a patch command to modify the underlying PersistentVolumeClaim:
kubectl patch pvc pure-claim-name -p=’{“spec”: {“resources”: {“requests”: {“storage”: “20Ti”}}}}’
Replace the PVC name and desired size (both in bold above) with appropriate values.
The volume expansion feature should be automatically enabled upon upgrade of PSO. Confirm by listing the available StorageClasses and checking the “ALLOWVOLUMEEXPANSION” column.
$ kubectl get storageclass
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
pure-block pure-csi Delete Immediate true 53d
pure-file pure-csi Delete Immediate true 53d
You can also manually enable the volume expansion feature for each StorageClass.
For FlashBlade:
> kubectl patch sc pure-file --type=json’ -p=’[{“op”: “add”, “path”: “/allowVolumeExpansion”, “value”: true }]’
For FlashArray:
> kubectl patch sc pure-block --type=’json’ -p=’[{“op”: “add”, “path”: “/allowVolumeExpansion”, “value”: true }]’
Use-case: Capacity Expansion for Elasticsearch
Elasticsearch is immensely useful; as a consequence, clusters often grow much larger than originally planned. Ingest volumes or retention periods can increase, resulting in the need for more available storage.
Traditionally, expanding capacity in an Elasticsearch cluster has always been done by adding new nodes. This approach derives from original design assumptions tied to bare-metal hardware; adding storage meant adding physical drives somewhere. In modern cloud-native architectures with disaggregated infrastructure for applications and storage, we need more flexible ways to add capacity.
While resizing the per-node storage in a cluster can be simplified for the administrator, it still requires significant data migration. Migration of data means that scaling a cluster requires time linear in the total amount of data. CSI volume resizing add flexibility with a new way to grow capacity.
To resize all volumes belonging to an Elasticsearch cluster, I adapt the patch command for each PVC that matches a label assigned by the ECK operator, “elasticsearch.k8s.co/clustername.”
$ kubectl get pvc -l elasticsearch.k8s.elastic.co/cluster-name=quickstart -o name | xargs kubectl patch -p=’{“spec”: {“resources”: {“requests”: {“storage”: “200Gi”}}}}’
persistentvolumeclaim/elasticsearch-data-quickstart-es-all-nodes-0 patched
persistentvolumeclaim/elasticsearch-data-quickstart-es-all-nodes-1 patched
persistentvolumeclaim/elasticsearch-data-quickstart-es-all-nodes-2 patched
persistentvolumeclaim/elasticsearch-data-quickstart-es-all-nodes-3 patched
The above pipelined command uses kubectl to retrieve the list of PVCs and then uses xargs to issue “kubectl patch” commands for each volume.
After the CSI volumes are resized, the additional space is available immediately for Elasticsearch with no node reboots necessary.
Today, modifying the Statefulset definition to increase volume size is not allowed, though there is an open issue tracking this enhancement. This future leads to even simpler administration when operators like ECK fold in this functionality.
Because the Stateful cannot be updated yet, any new nodes added will still use the original PVC size, resulting in uneven node capacities.
After expanding the Statefulset replicas, check per-node capacity with the following command:
$ curl -XGET 'https://localhost:9200/_cat/allocation?v'
shards disk.indices disk.used disk.avail disk.total disk.percent host ip node
13 8.6gb 9.5gb 483mb 10gb 95 10.233.95.19 10.233.95.19 quickstart-es-all-nodes-2
10 7.8gb 8.7gb 1.2gb 10gb 87 10.233.104.39 10.233.104.39 quickstart-es-all-nodes-0
10 3.9gb 4.2gb 801mb 5gb 84 10.233.80.112 10.233.80.112 quickstart-es-all-nodes-4
11 8.6gb 9.6gb 373.5mb 10gb 96 10.233.70.19 10.233.70.19 quickstart-es-all-nodes-1
14 8.5gb 9.4gb 550.5mb 10gb 94 10.233.94.129 10.233.94.129 quickstart-es-all-nodes-3
Until you can expand volumes through the Statefulset definition, it will require some care to maintain the cluster long-term if you need to add more nodes. Options include a data migration to a new nodeSet within the cluster where the volume size matches the expanded volume sizes.
Experimental Validation
The scenario I will test is an Elasticsearch cluster indexing new data continuously such that it runs out of storage after some time. The cluster starts with three nodes, provisioned by ECK, using PersistentVolumes backed by FlashBlade. Each node has 32 CPUs, 64GB of DRAM, and 128GB of storage. I am using small storage volumes to illustrate out-of-space conditions more easily.
In these experiments, I monitor the available space with the allocation API and a Prometheus/Grafana dashboard.
Approach 1: Adding nodes
In the following set of graphs, a fourth node is added to the cluster by updating the ECK cluster yaml “nodeCount” field. After the update, ECK adds an additional node with 128GB of storage to the cluster, increasing the overall storage by 33%.
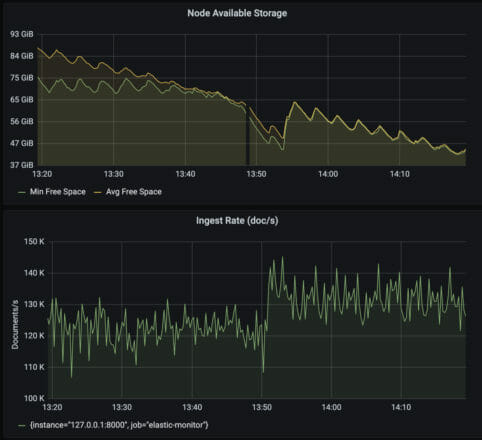
The top graph plots the average and minimum available space per Elasticsearch node. The available space increases on all nodes because of shard rebalancing. Additionally, the bottom graph shows an increase in ingest performance because of the additional CPU added to the cluster along with the storage.
There are two downsides to this approach to increasing capacity. First, additional CPU and DRAM were also added, even if they are not necessary. Second, the increment of scaling is fixed at the existing node specification, limiting the flexibility of what increments storage can be added.
Approach 2: CSI Volume Resize
The second approach to increasing Elasticsearch capacity leverages the CSI resize functionality to dynamically expand the node’s storage in-place.
To resize the volumes associated with an Elasticsearch cluster named ‘quickstart’, I use the following command:
kubectl get pvc -l elasticsearch.k8s.elastic.co/cluster-name=quickstart -o name | xargs kubectl patch -p=’{“spec”: {“resources”: {“requests”: {“storage”: “192Gi”}}}}’
In the experiment below, I resize the volumes twice. The first time increases storage as before, whereas the second time I wait for indexing to stop entirely because the cluster is out of space. The purpose of allowing the cluster to run out of space is to show how easy it is to use the resize functionality to unblock a stalled cluster.

As expected, the first resize adds additional capacity and allows indexing to smoothly continue. What might be unexpected, though, is that the second resize also results in Elasticsearch automatically resuming with no other intervention required. Elasticsearch detects the change in available space and moves out of read-only mode.
Summary
Kubernetes CSI volume resizing brings the benefit of seamless storage scalability to applications originally designed for direct-attached storage. Previously, growing storage required adding new nodes with a fixed ratio of compute and storage, even if only storage is needed. Now, CSI volume resizing can add exactly the amount of additional storage desired, without extra CPU or DRAM or expensive data migrations. Combine this with a seamless scale-out storage platform like FlashBlade for easier overall scalability.




