


This blog originally appeared on Medium.com and has been republished with permission from ths author.
This post presents a modern data warehouse implemented with Presto and FlashBlade S3; using Presto to ingest data and then transform it to a queryable data warehouse.
A common first step in a data-driven project makes available large data streams for reporting and alerting with a SQL data warehouse. I will illustrate this step through my data pipeline and modern data warehouse using Presto and S3 in Kubernetes, building on my Presto infrastructure(part 1 basics, part 2 on Kubernetes) with an end-to-end use-case.
A basic data pipeline will 1) ingest new data, 2) perform simple transformations, and 3) load into a data warehouse for querying and reporting. The only required ingredients for my modern data pipeline are a high performance object store, like FlashBlade, and a versatile SQL engine, like Presto. There are many variations not considered here that could also leverage the versatility of Presto and FlashBlade S3.
In building this pipeline, I will also highlight the important concepts of external tables, partitioned tables, and open data formats like Parquet. The combination of PrestoSql and the Hive Metastore enables access to tables stored on an object store. So while Presto powers this pipeline, the Hive Metastore is an essential component for flexible sharing of data on an object store. For brevity, I do not include here critical pipeline components like monitoring, alerting, and security.
The diagram below shows the flow of my data pipeline.
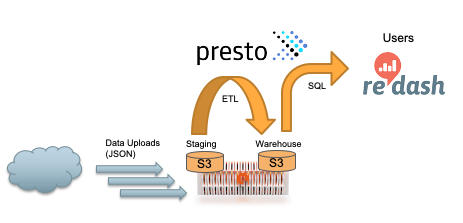
- First, an external application or system uploads new data in JSON format to an S3 bucket on FlashBlade.
- Second, Presto queries transform and insert the data into the data warehouse in a columnar format.
- Third, end users query and build dashboards with SQL just as if using a relational database.
The Application: Tracking Filesystem Metadata
This Presto pipeline is an internal system that tracks filesystem metadata on a daily basis in a shared workspace with 500 million files.
Managing large filesystems requires visibility for many purposes: tracking space usage trends to quantifying vulnerability radius after a security incident. For some queries, traditional filesystem tools can be used (ls, du, etc), but each query then needs to re-walk the filesystem, which is a slow and single-threaded process. Walking the filesystem to answer queries becomes infeasible as filesystems grow to billions of files.
Pure’s Rapidfile toolkit dramatically speeds up the filesystem traversal and can easily populate a database for repeated querying. This allows an administrator to use general-purpose tooling (SQL and dashboards) instead of customized shell scripting, as well as keeping historical data for comparisons across points in time.
Next, I will describe two key concepts in Presto/Hive that underpin the above data pipeline.
Presto+Hive Concept 1: External Tables
The first key Hive Metastore concept I utilize is the external table, a common tool in many modern data warehouses. An external table connects an existing data set on shared storage without requiring ingestion into the data warehouse, instead querying the data in-place. Creating an external table requires pointing to the dataset’s external location and keeping only necessary metadata about the table.
An external table means something else owns the lifecycle (creation and deletion) of the data. One useful consequence is that the same physical data can support external tables in multiple different warehouses at the same time! To DROP an external table does not delete the underlying data, just the internal metadata.
Why to use an external table:
- Decouple pipeline components so teams can use different tools for ingest and querying
- One copy of the data can power multiple different applications and use-cases: multiple data warehouses and ML/DL frameworks
- Avoid lock-in to an application or vendor by using open formats, making it easy to upgrade or change tooling
An example external table will help to make this idea concrete. Create a simple table in JSON format with three rows and upload to your object store. I use s5cmd but there are a variety of other tools.
> cat people.json
{“name”:”Michael”}
{“name”:”Julia”, “age”:30}
{“name”:”Melissa”, “age”:19}
> s5cmd cp people.json s3://joshuarobinson/people.json/1
The table location needs to be a “directory” not a specific file. It’s okay if that directory has only one file in it and the name does not matter. In an object store, these are not real directories but rather key prefixes.
Create the external table with schema and point the “external_location” property to the S3 path where you uploaded your data. The table will consist of all data found within that path.
CREATE TABLE people (name varchar, age int) WITH (format = ‘json’, external_location = ‘s3a://joshuarobinson/people.json/’);
This new external table can now be queried:
presto:default> SELECT * FROM people;
name | age
— — — — -+ — — —
Michael | NULL
Andy | 30
Justin | 19
(3 rows)
Presto and Hive do not make a copy of this data, they only create pointers, enabling performant queries on data without first requiring ingestion of the data. For frequently-queried tables, calling ANALYZE on the external table builds the necessary statistics so that queries on external tables are nearly as fast as managed tables.
Presto+Hive Concept 2: Partitioned Tables
A table in most modern data warehouses is not stored as a single object like in the previous example, but rather split into multiple objects. The most common ways to split a table include bucketing and partitioning. Partitioned tables are useful for both managed and external tables, but I will focus here on external, partitioned tables.
Partitioning breaks up the rows in a table, grouping together based on the value of the partition column. In other words, rows are stored together if they have the same value for the partition column(s). When queries are commonly limited to a subset of the data, aligning the range with partitions means that queries can entirely avoid reading parts of the table that do not match the query range. Partitioning impacts how the table data is stored on persistent storage, with a unique “directory” per partition value.
A frequently-used partition column is the date, which stores all rows within the same time frame together.
A concrete example best illustrates how partitioned tables work. Consider the previous table stored at ‘s3://bucketname/people.json/’ with each of the three rows now split amongst the following three objects:
bucketname/people.json/school=central/1
bucketname/people.json/school=west/1
bucketname/people.json/school=west/2
Each object contains a single json record in this example, but we have now introduced a “school” partition with two different values. The path of the data encodes the partitions and their values. Table partitioning can apply to any supported encoding, e.g., csv, Avro, or Parquet.
To create an external, partitioned table in Presto, use the “partitioned_by” property:
CREATE TABLE people (name varchar, age int, school varchar) WITH (format = ‘json’, external_location = ‘s3a://joshuarobinson/people.json/’, partitioned_by=ARRAY[‘school’] );
The partition columns need to be the last columns in the schema definition. While you can partition on multiple columns (resulting in nested paths), it is not recommended to exceed thousands of partitions due to overhead on the Hive Metastore.
If we proceed to immediately query the table, we find that it is empty. The Hive Metastore needs to discover which partitions exist by querying the underlying storage system. The Presto procedure sync_partition_metadata detects the existence of partitions on S3.
CALL system.sync_partition_metadata(schema_name=>’default’, table_name=>’people’, mode=>’FULL’);
Subsequent queries now find all the records on the object store.
presto:default> SELECT * FROM people;
name | age | school
— — — -+ — — — + — — — — -
Andy | 30 | west
Justin | 19 | west
Michael | NULL | central
(3 rows)
And if data arrives in a new partition, subsequent calls to the sync_partition_metadata function will discover the new records, creating a dynamically updating table.
Partitioned external tables allow you to encode extra columns about your dataset simply through the path structure. For a data pipeline, partitioned tables are not required, but are frequently useful, especially if the source data is missing important context like which system the data comes from.
Pipeline Implementation
Data Collector
Data collection can be through a wide variety of applications and custom code, but a common pattern is the output of JSON-encoded records. The pipeline here assumes the existence of external code or systems that produce the JSON data and write to S3 and does not assume coordination between the collectors and the Presto ingestion pipeline (discussed next).
My data collector uses the Rapidfile toolkit and ‘pls’ to produce JSON output for filesystems. Two example records illustrate what the JSON output looks like:
{“dirid”: 3, “fileid”: 54043195528445954, “filetype”: 40000, “mode”: 755, “nlink”: 1, “uid”: “ir”, “gid”: “ir”, “size”: 0, “atime”: 1584074484, “mtime”: 1584074484, “ctime”: 1584074484, “path”: “\/mnt\/irp210\/ravi”}
{“dirid”: 3, “fileid”: 13510798882114014, “filetype”: 40000, “mode”: 777, “nlink”: 1, “uid”: “ir”, “gid”: “ir”, “size”: 0, “atime”: 1568831459, “mtime”: 1568831459, “ctime”: 1568831459, “path”: “\/mnt\/irp210\/ivan”}
The collector process is simple: collect the data and then push to S3 using s5cmd:
pls --ipaddr $IPADDR --export /$EXPORTNAME -R --json > /$TODAY.json
s5cmd --endpoint-url https://$S3_ENDPOINT:80 -uw 32 mv /$TODAY.json s3://joshuarobinson/acadia_pls/raw/$TODAY/ds=$TODAY/data
The above runs on a regular basis for multiple filesystems using a Kubernetes cronjob. Notice that the destination path contains “/ds=$TODAY/” which allows us to encode extra information (the date) using a partitioned table.
While the use of filesystem metadata is specific to my use-case, the key points required to extend this to a different use case are:
- Uploading data to a known location on an S3 bucket in a widely-supported, open format, e.g., csv, json, or avro.
- Optional, use of S3 key prefixes in the upload path to encode additional fields in the data through partitioned table.
In many data pipelines, data collectors push to a message queue, most commonly Kafka. To keep my pipeline lightweight, the FlashBlade object store stands in for a message queue. The S3 interface provides enough of a contract such that the producer and consumer do not need to coordinate beyond a common location. Specifically, this takes advantage of the fact that objects are not visible until complete and are immutable once visible. For more advanced use-cases, inserting Kafka as a message queue that then flushes to S3 is straightforward.
The Destination: Presto Data Warehouse
First, we create a table in Presto that servers as the destination for the ingested raw data after transformations. Dashboards, alerting, and ad hoc queries will be driven from this table. This section assumes Presto has been previously configured to use the Hive connector for S3 access (see here for instructions).
First, I create a new schema within Presto’s hive catalog, explicitly specifying that we want the table stored on an S3 bucket:
> CREATE SCHEMA IF NOT EXISTS hive.pls WITH (location = 's3a://joshuarobinson/warehouse/pls/');
Then, I create the initial table with the following:
> CREATE TABLE IF NOT EXISTS pls.acadia (atime bigint, ctime bigint, dirid bigint, fileid decimal(20), filetype bigint, gid varchar, mode bigint, mtime bigint, nlink bigint, path varchar, size bigint, uid varchar, ds date) WITH (format='parquet', partitioned_by=ARRAY['ds']);
The result is a data warehouse managed by Presto and Hive Metastore backed by an S3 object store.
ETL Logic: Ingest via External Table on S3
The ETL transforms the raw input data on S3 and inserts it into our data warehouse. Though a wide variety of other tools could be used here, simplicity dictates the use of standard Presto SQL.
The high-level logical steps for this pipeline ETL are:
- Discover new data on object store
- Create temporary external table on new data
- Insert into main table from temporary external table
- Drop temporary external table
- Remove data on object store
Step 1 requires coordination between the data collectors (Rapidfile) to upload to the object store at a known location. My pipeline utilizes a process that periodically checks for objects with a specific prefix and then starts the ingest flow for each one.
Steps 2–4 are achieved with the following four SQL statements in Presto, where TBLNAME is a temporary name based on the input object name:
1> CREATE TABLE IF NOT EXISTS $TBLNAME (atime bigint, ctime bigint, dirid bigint, fileid decimal(20), filetype bigint, gid varchar, mode bigint, mtime bigint, nlink bigint, path varchar, size bigint, uid varchar, ds date) WITH (format='json', partitioned_by=ARRAY['ds'], external_location='s3a://joshuarobinson/pls/raw/$src/');
2> CALL system.sync_partition_metadata(schema_name=>'default', table_name=>'$TBLNAME', mode=>'FULL');
3> INSERT INTO pls.acadia SELECT * FROM $TBLNAME;
4> DROP TABLE $TBLNAME;
The only query that takes a significant amount of time is the INSERT INTO, which actually does the work of parsing JSON and converting to the destination table’s native format, Parquet. Further transformations and filtering could be added to this step by enriching the SELECT clause.
There are alternative approaches. We could copy the JSON files into an appropriate location on S3, create an external table, and directly query on that raw data. But by transforming the data to a columnar format like parquet, the data is stored more compactly and can be queried more efficiently. With performant S3, the ETL process above can easily ingest many terabytes of data per day.
Using the Warehouse
We have created our table and set up the ingest logic, and so can now proceed to creating queries and dashboards!
My dataset is now easily accessible via standard SQL queries:
presto:default> SELECT ds, COUNT(*) AS filecount, SUM(size)/(1024*1024*1024) AS size_gb FROM pls.acadia GROUP BY ds ORDER BY ds;
day | filecount | size_gb
— — — — — -+ — — — — — + — — — — -
2019–10–05 | 417905229 | 44354
2019–10–06 | 417905350 | 44467
2019–10–07 | 417905603 | 44586
2019–10–08 | 712302359 | 45610
2019–10–20 | 377790894 | 47421
2019–10–28 | 482777169 | 50193
2019–10–29 | 482552818 | 50275
…
Issuing queries with date ranges takes advantage of the date-based partitioning structure. For example, the following query counts the unique values of a column over the last week:
presto:default> SELECT COUNT (DISTINCT uid) as active_users FROM pls.acadia WHERE ds > date_add('day', -7, now());
active_users
— — — — — — —
16
When running the above query, Presto uses the partition structure to avoid reading any data from outside of that date range.
Next step, start using Redash in Kubernetes to build dashboards…
Even More: Combining Presto and Spark
Even though Presto manages the table, it’s still stored on an object store in an open format. This means other applications can also use that data. For example, the entire table can be read into Apache Spark, with schema inference, by simply specifying the path to the table.
df = spark.read.parquet(“s3a://joshuarobinson/warehouse/pls/acadia/”)
df.printSchema()
<code”>root
| — atime: long (nullable = true)
| — ctime: long (nullable = true)
| — dirid: long (nullable = true)
| — fileid: decimal(20,0) (nullable = true)
| — filetype: long (nullable = true)
| — gid: string (nullable = true)
| — mode: long (nullable = true)
| — mtime: long (nullable = true)
| — nlink: long (nullable = true)
| — path: string (nullable = true)
| — size: long (nullable = true)
| — uid: string (nullable = true)
| — ds: date (nullable = true)
Spark automatically understands the table partitioning, meaning that the work done to define schemas in Presto results in simpler usage through Spark.
Now, you are ready to further explore the data using Spark or start developing machine learning models with SparkML!
Summary
Presto and FlashBlade make it easy to create a scalable, flexible, and modern data warehouse. The FlashBlade provides a performant object store for storing and sharing datasets in open formats like Parquet, while Presto is a versatile and horizontally scalable query layer. The example presented here illustrates and adds details to modern data hub concepts, demonstrating how to use S3, external tables, and partitioning to create a scalable data pipeline and SQL warehouse.




