



As data continues its inevitable upward growth, the focus on separation of compute and storage becomes an increasingly important part of scale-out applications. Scaling compute separate from storage creates opportunities for more tailored budget spend and more flexible designs based on use case requirements. Companies are at different points along their path to disaggregation, but the overall direction to create efficient architectures that can be scaled in a “brick by brick” fashion is clearly seen in the existing cloud providers and just as important to on-prem solutions as well.
Let’s look a bit more closely at what that means in terms of ElasticSearch and FlashBlade®.
Building an ElasticSearch cluster that takes advantage of a disaggregation approach can have many benefits. One of the ways you can realize those benefits is to use ElasticSearch searchable snapshots.
Searchable snapshots were designed to allow ElasticSearch to efficiently retrieve data from less frequently accessed S3 data sources. By using partially mounted index restores from what Elastic calls the frozen tier, ElasticSearch is able to retrieve only the data that is required to fulfill a particular search instead of performing a full index restoration to cache.
To utilize searchable snapshots, you need a registered repository that will store your indexes, commonly an S3 endpoint. This is easily configured in the Kibana “Register repository” page via the existing cloud provider selection options.
Figure 1:
What if you’re unable to use a public cloud provider, though?
In cases where you’re unable to use a cloud provider due to internal or external regulations, but would like to have a solution that could provide that cloud-like experience, FlashBlade can be a great fit. FlashBlade was built to scale with modern applications like ElasticSearch. With a native S3 API and a “grow as you need” approach, FlashBlade can scale easily as your S3 frozen tier grows.
There are benefits to this architecture right out of the box. One benefit is that an on-prem solution with FlashBlade S3 has zero egress cost. There is no direct charge for reads from an on-prem FlashBlade S3 solution. This means you can utilize your on-prem FlashBlade to augment the hot tier for searching to a much greater degree, depending on your search response requirements. Another advantage is that searchable snapshots on the frozen tier don’t use replicas. So you’re storing less data overall. The underlying FlashBlade is responsible for ensuring the data integrity and availability. This also means you are not sending copies of data to other nodes for HA protection, which means less network traffic.
This leads to a rethinking of what an ElasticSearch cluster might look like for a given use case. “Do I really need 90 days of hot storage data?” “What requirements do I have of my hot tier data?” “What are my search response requirements?” By asking these questions and adding a FlashBlade system into the equation, you’re able to create a more tailored solution that matches your true requirements.
So how difficult is it to create an architecture like that? Let’s look at an outline of the general steps.
Searchable Snapshots on FlashBlade
Setting up an S3 bucket on a FlashBlade system is a straightforward process. After a few configuration steps on the FlashBlade system, assign a bucket to an ElasticSearch cluster and use an Index Life Cycle Management policy to automatically move index data. (Note: A searchable snapshot license from Elastic is required on the ElasticSearch cluster to utilize frozen tier searchable snapshot functions.)
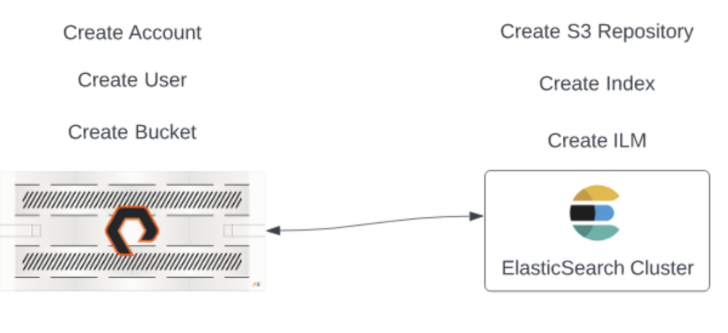
Figure 2:
How Is It Set Up?
S3 Bucket on FlashBlade
Configure the ElasticSearch Nodes
On each node, run the following to set the access key and secret keys from the FlashBlade bucket creation and then reboot each node.
Example:
Configure the Repository on the ElasticSearch Cluster
Run the following command from a Kibana Dev console. You can also run this as a curl command:
You can run the following to verify connectivity from each node:
Creating the ILM
An ILM can be created using a few methods: Curl, Dev Console, or GUI. Here I’m showing the GUI and the basic steps.
Create the hot phase, choose your retention, and then set your frozen tier to write data to the FlashBlade S3 bucket. Lastly, associate the ILM to the index.
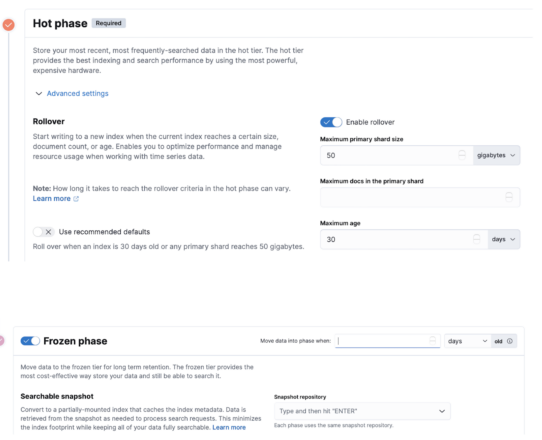
Figure 3:
Simplicity, Scale, and Efficiency
When you create this tiering setup, you have the opportunity to size your cluster very differently as I mentioned previously. What does that look like from a sizing calculation?
As an extreme example (based on standard capacity-sizing calculations):

239 hot nodes are required for Sizing 1.
40 nodes are required for Hot Tier with S3 Sizing 2.
That is an 83% reduction in the number of nodes required to meet the 365-day retention requirement. Not to mention, the rack space, power, and cooling required to support 239 nodes.
Obviously, in a typical ElasticSearch cluster, you would not store all of your data in the hot tier. That being said, this is a good illustration of what you might be able to achieve with a different approach to your ElasticSearch cluster configuration.
A quick note about ElasticSearch sizings: It’s important to remember that capacity calculations are not performance calculations. Elastic uses a different calculation when talking about performance-related cluster configurations. Conflating a capacity-sizing exercise with performance improvement is not accurate. In this example, we’re talking about capacity only, not performance improvement.
That being said, performance can be impacted by your storage tier choices and it’s an important consideration when determining what tier should hold what data and for what reason.
To Wrap Up
There are many ways to configure an ElasticSearch cluster and often the answer to the question “What is the best way to set up ElasticSearch?” is “It depends.” Not necessarily helpful, but true. ElasticSearch is a highly customizable search platform that requires careful consideration to get the best out of it. So questions like: What are you trying to achieve? What are the metrics most important to your use case? What results are most important to you? are all valid questions and will help define what configuration you end up using.
Overall, this post is focused on how you might think differently about your ElasticSearch architecture for use cases that can’t go to the cloud. It looks at using FlashBlade S3 with ElasticSearch to flexibly grow in a more tailored approach to take advantage of the simplicity, scalability, and efficiency FlashBlade offers.
At the same time, you can gain environmental benefits such as:
- Less data stored
- A possible reduction in expensive hot tier nodes count
- More tailored purchase decisions around workload requirements
- Power, cooling, and rack space benefits
Lastly, combining FlashBlade with Evergreen//One™ and ElasticSearch creates a true cloud-like experience for on-prem workloads. If you’re interested in learning more, please reach out to your local sales representative for a deeper dive.
Your Data Storage Solution
Learn more about the simplicity, scalability, and efficiency of FlashBlade.




