

I have been traveling around lately talking about VVols and one of the most commonly misunderstood objects is the VVol datastore. What is it? What does capacity mean on it? Why does it even exist?
These are all good questions. The great thing about VVols is that very little changes in how the VMware user interacts with vSphere. But at the same time, what actual happens is VERY different. So let’s work through this.
Let’s start off with what a VVol datastore is NOT:
- It is not a LUN.
- It is not a volume/device/disk.
- It is not a file system.
- It is not formatted with anything.
So what is it? Well a few things.
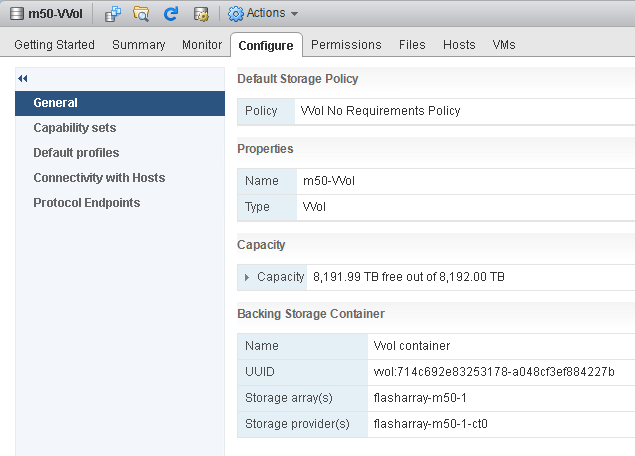
First off, it is a representation of an array. This represents an array (and an array can have more than one VVol datastore if the array supports it). So in other words, if a user wants a VM or virtual disk to be on a given array, they choose a VVol datastore that represents it. This is no different, conceptually, from VMFS or NFS.
Furthermore, it is a provisioning limit. A VVol datastore has a capacity and this capacity limits how much a VMware admin can provision using it. If the VVol datastore is 40 TB, you can provision up to 40 TB. This is also no different than VMFS or NFS. Though, since VVol datastores are not physical objects or file systems, they do not have the same constraints that a file system might have, like total size. A VVol datastore can be up to the zettabytes in size if needed. So there is no practical limit, like the 64 TB limit that VMFS has. So the actual limit of a VVol datastore is really up to the storage vendor.
Note that the virtual disk size limit does not change. You can see that when you try to mount a VVol datastore:
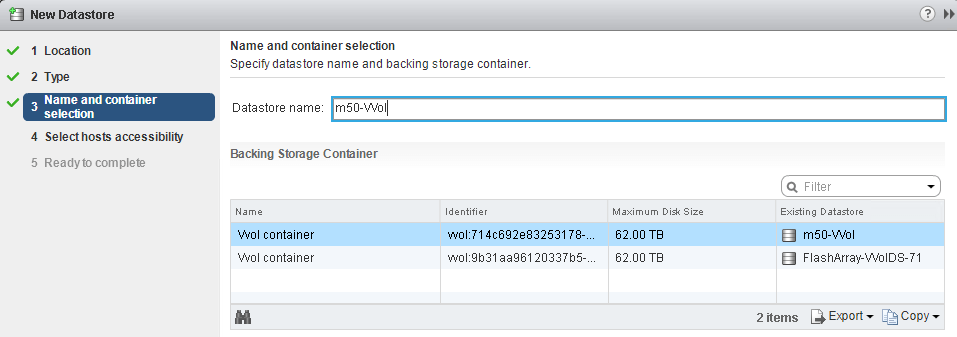
It says the max disk size is 62 TB. This is not the size of the VVol datastore–that is seen after the datastore is mounted. This says how big of a virtual disk you can create on this datastore. This is the same limit of VMFS. There is no real reason why a virtual disk cannot be bigger than 62 TB on VVols, but the problem is, if you create one larger you would not be able to Storage vMotion it back (or clone it) to VMFS if you wanted to. Therefore, the traditional VMDK size limit of 62 TB holds.

It is a collection of VMs. Every VM has a config VVol and and each config VVol is a mini-file system that has pointers to VVols and VM configuration information. When a virtual disk is created on a VM in a VVol datastore, a vmdk file is created in that config VVol that points the VM to the VVol (the volume) on the array. See more information on config VVols here:
What is a Config VVol Anyways?
How a VVol datastore tracks capacity is also interesting. VVol datastores are array-aware. How much space is used in a VVol datastore is entirely up to the storage array to decide. With VMFS, for instance, how much is used is the summation of the allocated size of the virtual disks on it (plus snapshots and other files). If a virtual disk is thick, the whole size of the virtual disk counts towards the used amount. If a virtual disk is thin, just how much has been written to it is what counts. With VVols, it is entirely up to the array to decide how much space a virtual disk uses. Let me give you an example:
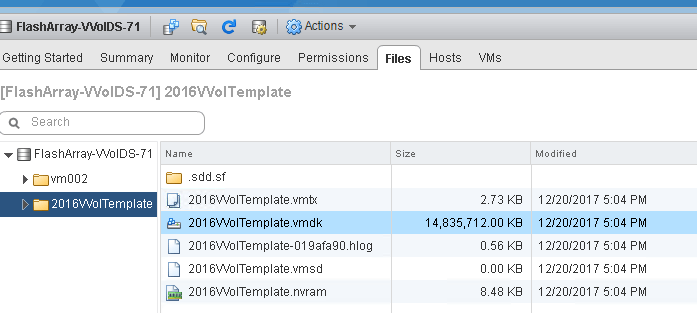
The above screenshot is of a VVol datastore in a specific VM folder. A VM folder is just a mount point in the VVol datastore to a VM config VVol. In this there is a VMDK file that is 14 GB. This VMDK points to a data VVol that is allocated to be 200 GB. But only 14 GB of that is actually written. But we can be smarter than what you are used to with VMFS. It can be made dedupe aware, or compression aware, or pattern-removal aware. Whether it is or not is up to your vendor. For the FlashArray, we report how much has been written by the guest BEFORE data reduction. So it is very similar to a thin disk in VMFS, which one major exception. If the guest writes all zeros to a thin virtual disk on VMFS, the thin virtual disk grows. If you write zeros to a VVol on the FlashArray, the VMDK size does NOT grow–we make the VMDK size zero aware. So a VVol VMDK on the FlashArray is the guest-written space minus zeroing (more on this in a later post).
Every vendor will do something different, but the idea is that there is a lot more flexibility built into it–VMware allows arrays to do what makes sense for that platform.
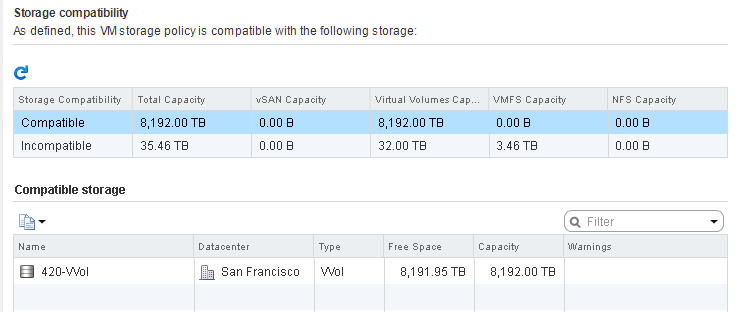
A VVol datastore is also a representation of features. When you choose a storage policy when provisioning, datastores are filtered out on whether they are compatible or not. VMware basically asks each datastore “can you offer this feature?”. If the array that offers up that VVol datastore cannot, the VVol datastore says no and is marked as an incompatible option for that policy.
VVol datastores abstract the physical connection to the array, So how is data accessed if the datastore is not a physical object or connection? Well this where protocol endpoints come in. I have blogged a bit about these in the past:
Queue Depth Limits and VVol Protocol Endpoints
Virtual Volumes: VVol Bindings Explained
But PEs are akin to a network switch. If every host was direct connected to each other via cables, only so many could be connected to one other at once. It would be limited by the number of ports each host had. Introducing a switch allows everyone to connect to the switch and the switch then provides access to everyone else.
Without a protocol endpoint, every VVol would be a LUN connection and you would exhaust ESXi’s supported LUN limits and SCSI slots and/or logical path limit. Instead the protocol endpoint acts a “switch” the VVol datastore is associated with it and all I/O goes to the PE and the PE routes the I/O to the appropriate VVol on that array,
Conclusion
The important thing is that a VVol datastore exists to not BREAK your existing workflows or integrations. You have a backup that backs up VMDKs? It can still see VMDKs even if they are technically VVol pointers and do the backup. You have a PowerCLI script that has a new-vm operation with the -datastore option? Just put in the name of the VVol datastore and the script still works.



