
The reason it is asked is that it is often tricky if not impossible to support in an active/active scenario. Because the storage platform first has to perform the operation on one array, but also on the other. So XCOPY, which offloads VM copying, is often not supported. Let’s take a look at VAAI with ActiveCluster, specifically these four features:
- Hardware Assisted Locking (ATOMIC TEST & SET)
- Zero Offload (WRITE SAME)
- Space Reclamation (UNMAP)
- Copy Offload (XCOPY)
Hardware Assisted Locking/ATS
This is fully supported with ActiveCluster and there is nothing to really prove out here. If you look at a volume that is enabled with ActiveCluster in ESXi, you certainly see it as supported:

ATS is good. Furthermore, in esxtop we can see that these operations are being issued and are succeeding:
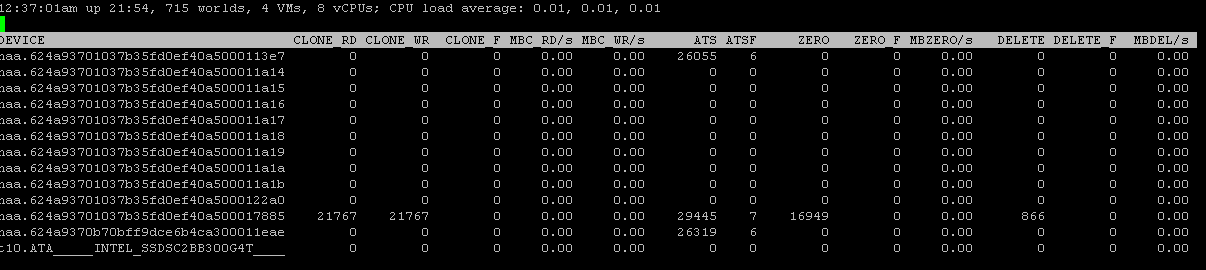
And not only ATS but the other three as well. So let’s go into this in more detail.
Zero Offload/WRITE SAME
The best way to test zero offload or WRITE SAME, is the create an eagerzeroedthick virtual disk. WRITE SAME is engaged in many ways, but this is the simplest way to tell if it is working and how well it is working.
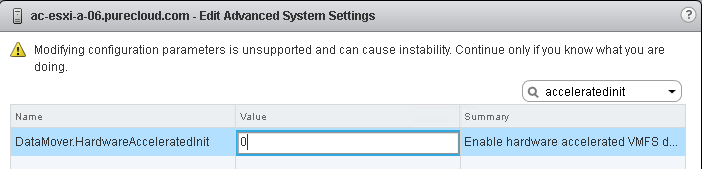
So to get a baseline, I will create a EZT virtual disk on my ActiveCluster datastore with WRITESAME disabled on the host:
So from a VM on that host I will create the disk:
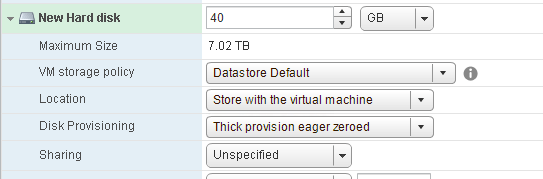

It took 36 seconds to do 40 GB of eagerzeroing without WRITE SAME.
So now re-enable it:
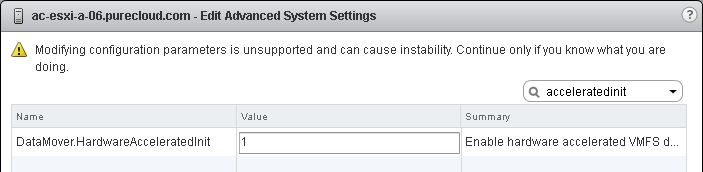
First, for a WRITE SAME baseline, creating a 40 GB EZT virtual disk with a non-ActiveCluster volume:

Takes 6 seconds–so much faster with it on.

And now run the same test, create a 40 GB EZT virtual disk but this time on an ActiveCluster volume. With WRITE SAME on, it takes 16 seconds.
My lab has a distance simulator between my arrays, so latency is induced for replication, so that is likely the cause of the time difference of 6 to 16 seconds. But it definitely still works and still accelerates!
Let’s move to UNMAP.
Space Reclamation/UNMAP
UNMAP means a lot of things in a VMware environment. But in short, it is once files have been deleted on a block volume, UNMAP is what is issued to the array to tell the array that the LBAs that hosted that file are cleared and do not need to be kept anymore. This is what makes array-based thin provisioning possible.
So I have a VMFS datastore called vMSC-VMware-UNMAPTest, that is stretched across two FlashArrays.
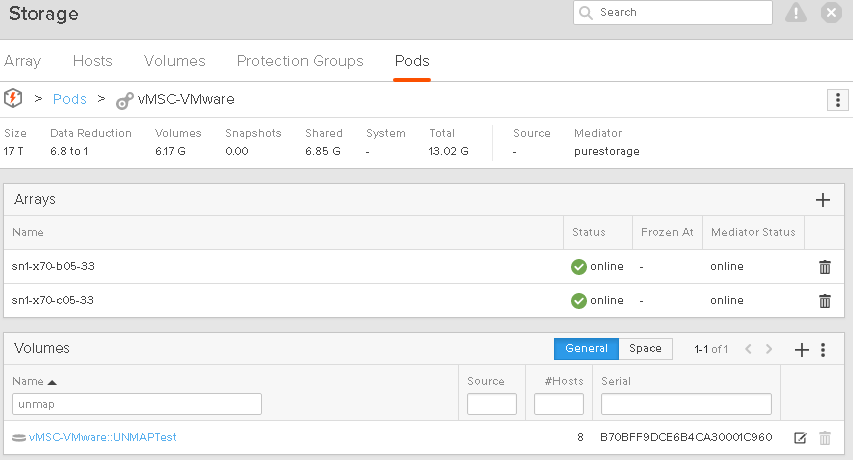
The current usage of the volume is zero:
So let’s put some data on it. I will put a Windows 2016 VM on it and to get it more actual footprint I will use vdbench to write a few GBs of data in the VM too.
Now, I wait for UNMAP to do its thing and then take a look at the capacity usage of that volume on both FlashArrays:
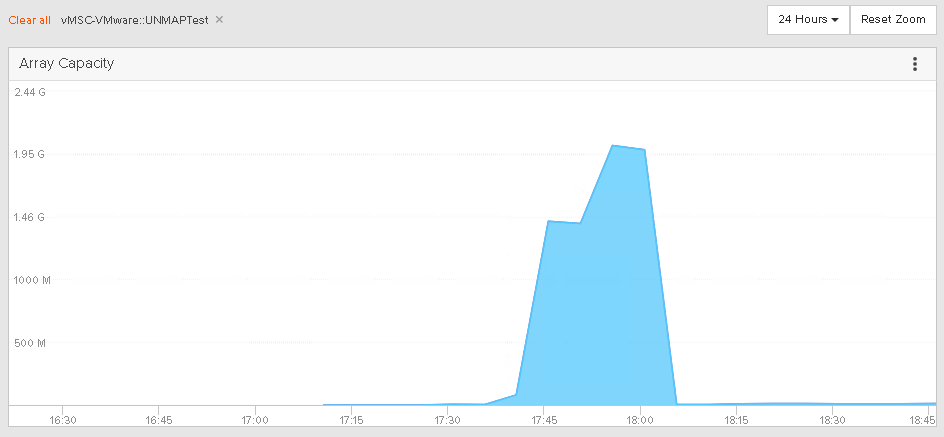
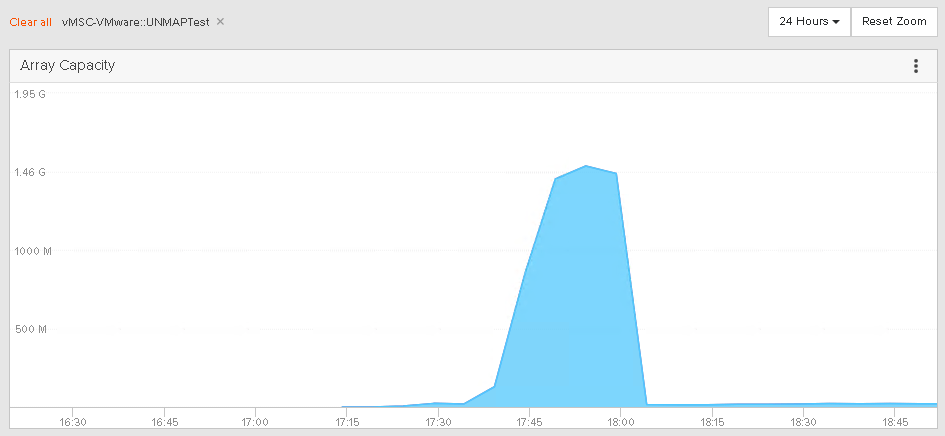
You will not the capacity usage is slightly different on each array, and that is because each FlashArray is globally deduped, so even though the volume has the same data on each side, they might reduce differently on each array, depending on what other data is on each array. But the point here is that yes UNMAP works and it definitely is passed across FlashArrays when issued to a ActiveCluster enabled volume.
This brings us to XCOPY.
Copy Offload/XCOPY
XCOPY being one of the most “visible” VAAI primitives, it is the one that gets asked about the most when it comes to is it supported with feature X or Y. It is easy to demo and it is easy to see the benefits and therefore also easy to feel the pain of not having it. On the FlashArray, XCOPY has always been supported-it is never turned off if you want to use any feature on the array. ActiveCluster though is a feature that spans two arrays, so let’s revisit that question.
First off, let’s remind ourselves what XCOPY is and how it works on the FlashArray. The traditional mechanism for copying a VM (or Storage vMotion or deploy from template) is for ESXi to read the data from one datastore and then write the data down to the target location, whether that be the same datastore or a different one. This process is very read/write intensive. It sucks up a lot of bandwidth.
XCOPY makes this process more efficient. If the source and target datastores are on the same array, ESXi, instead of reading and writing, issues a series of XCOPY commands down to the array. These XCOPY commands essentially tell the array, “hey copy these blocks from here to there”. So the array then does the copy itself. At the least, this makes the process more efficient, as the actual data does not need to traverse the SAN and host. At best it also speeds up the operation, and sometimes significantly, depending on how the underlying array implements XCOPY.
On the FlashArray, a volume is really just a collection of metadata pointers. A volumes LBAs don’t really point to some place on flash directly. The FlashArray is constantly compressing and deduping the data to get better data reduction, so the data physical layout changes constantly. So when writes come in to a volume, a meta data change occurs, in other words, the LBA metadata pointers change. If the actual data already exists, the pointer is created to the pre-existing data. If it doesn’t, the data is written down and the metadata points to it.
This is what makes our snapshots so efficient and quick as well–they are no copy-on-write or redirect on write, they are simply preserving the point-in-time of the metadata pointers of a volume. This is how they can be created instantly and copied from instantly. The process is just a metadata copy, not actual data movement or copying.
XCOPY works the same way. When the FlashArray receives an XCOPY command, we just copy the metadata from that LBA to the target LBA. So no data needs to be moved or copied. Makes it very fast.
So now ActiveCluster. Let’s run through a few tests. I will use the “deploy from template” operation for all of the tests.
- Operation with XCOPY off (disabled in VMware) between two non-ActiveCluster volumes
- Operation with XCOPY on (enabled in VMware) between two non-ActiveCluster volumes
- Operation with XCOPY on between one non-ActiveCluster volume and one ActiveCluster volume
- Operation with XCOPY on between one ActiveCluster volume and another ActiveCluster volume
Baseline XCOPY Off
So for a baseline, let’s do it with XCOPY off.
I have a datastore on my FlashArray called XCOPYsource and another called XCOPYtarget. My template is on the source. Neither are currently involved in ActiveCluster.
I will use PowerCLI to do the copy with the measure-command cmdlet to see how long it takes. Using this command:
|
1 2 |
measure–command {new–vm –Template Windows2016XCOPY –Name VMXCOPY01 –Datastore XCOPYtarget –vm host ac–esxi–a–01.purecloud.com} |
Let’s give it a try.
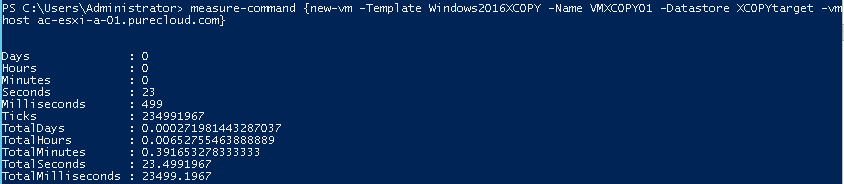
So about 23.5 seconds.
XCOPY On
So now let’s try one with XCOPY ON. Once again, no ActiveCluster involved.
Now, let’s run the test again.
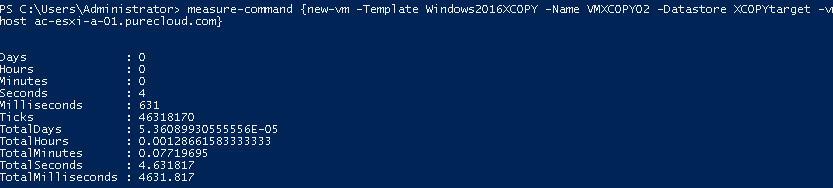
4.5 seconds that time. Yay XCOPY!
XCOPY with ActiveCluster enabled on the target
So let’s enabled XCOPY on the target. I will:
- Create a new pod
- Add the XCOPYtarget into it
- Stretch the pod to my 2nd array
- Test XCOPY
So, create:
Then move it into the pod:
Then stretch it:
Then let’s wait for it to sync.
Once online:
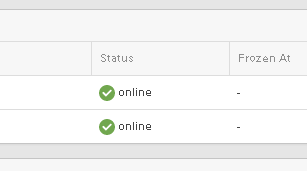
The volume is stretched and Active/Active. Let’s try to XCOPY from a non-AC volume to an AC-volume.
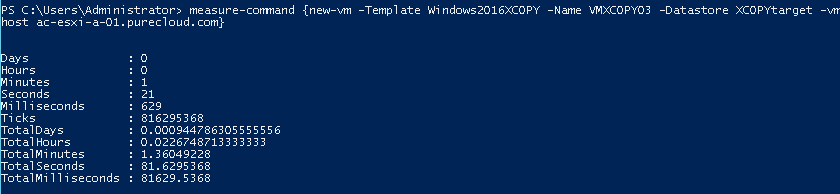
1 minute 22 seconds. Longer than non-XCOPY. So this means that XCOPY is not on. Furthermore, because of my distance simulator, the additional latency is slowing the copy down.
XCOPY with ActiveCluster enabled on the target and source
So let’s create a new VMFS in the pod, called xcopytarget2

Then put VMFS on it.
So, now let’s copy one of the VMs on XCOPYtarget to XCOPYtarget2, both of which are in my pod.
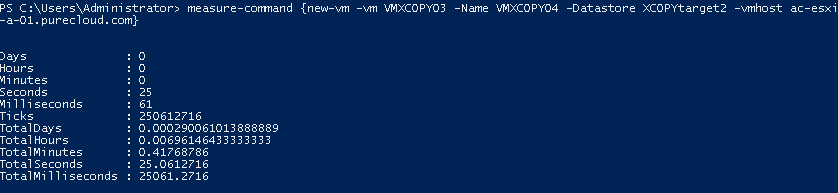
25 seconds. XCOPY is being used! Though it is slower than non-AC XCOPY. Once again this is because the move has to be acknowledged on the remote FlashArray too, so it will slow down the copy a bit.
Conclusion
So first off, why does XCOPY not work from a volume to a volume in a pod? Well the issue is that the pod is synchronously writing data to the other side and therefore before we can acknowledge the XCOPY back we have to know if it is at the other side. When a volume is outside of a pod we can’t guarantee that the data is already there. So, we reject XCOPY and just do the normal copy. For volumes inside of a pod, we DO KNOW that the data is on the other side. So not only do we not need to check, we don’t even have to send the data itself. We simply mirror the XCOPY to other side, so both sides make the metadata change and then we acknowledge. So there is always going to be a little bit of a slow down in XCOPY in a pod as compared to just local, but it still works and still is faster. Depending on the latency between the FlashArrays the different might be smaller or larger than mine (I think my distance simulator is set at 4 ms RTT).
Everything else is pretty much the same. UNMAP, ATS, WRITE SAME. XCOPY has the lone exception, so generally I’d either put templates inside of a pod, if you plan on deploying them on ActiveCluster volumes a lot. Or do your deployment first, then add the volumes to the pod, then stretch.



