In the first post of this series I tried to put a SQL Server spin on answers to questions we get from our customers regarding dedupe and compression. In this installment, I’d like to show how our built-in dedupe and compression mechanisms can increase compression on already compressed tables.
The Setup
The fine folks at StackExchange have made their Q&A site database publicly available through several means – you can even interactively query it at Data.StackExchange.com. Of particular interest for this post is their full database dump, available on the Internet Archive. My friend Jeremiah Peschka [blog|twitter] contributed to a tool called SODDI to create SQL Server databases based on the SE data dumps.
Armed with the StackOverflow database, I started asking myself questions about the effectiveness that FlashArray dedupe and compression would have on SQL Server compressed data.
The Tests
I wanted to start clean, so I rebuilt all the indexes for all tables on the StackOverflow database with DATA_COMPRESSION=NONE. Then, I went ahead and ran the standard “Disk Tables by Top Tables” report bundled with SQL Server Management Studio – since this database has only 7 tables, I didn’t need anything fancier than that. I repeated that process for DATA_COMPRESSION=ROW, then DATA_COMPRESSION=PAGE. The results (merged) are below:
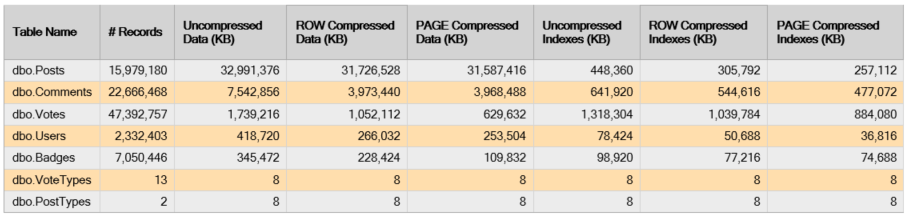
A few things can be observed from these numbers: some tables compressed extremely well, and others….not so much. Take dbo.Votes, for example – the base table went from 1.66GB down to 0.6GB. That’s pretty good. Well done, SQL Server.
Then there is dbo.Posts. I took a look at the table definition for clues as to why it didn’t compress, and something popped up immediately:
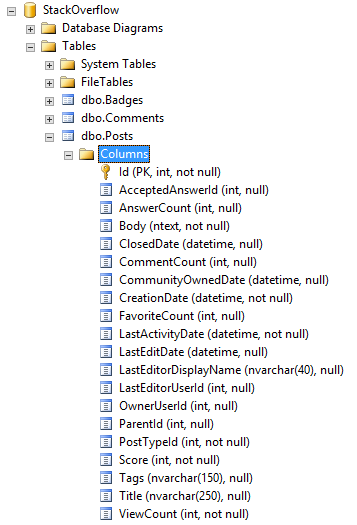
“Aha!” I said to myself, “That ntext column right there!” To confirm, I ran the following query (results included):
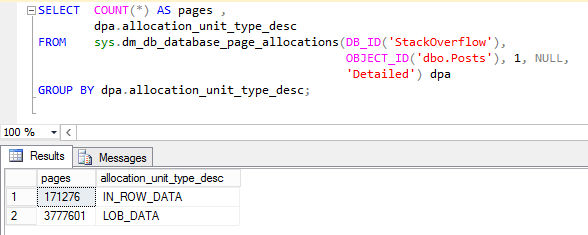
Surely enough, that table has 3.78 million pages of LOB_DATA – the allocation unit type for data kept on a separate data structure from the clustered index/heap. SQL Server’s row and page compression methods do not effect data that is stored off-row. And thus the majority of the data in this dbo.Posts table remains uncompressed. This sounds like an opportunity for our FlashArray!
After I rebuilt the indexes with page compression, I went to look at the data reduction ratio on the array’s console, and I showed what’s outlined in the screenshot below:
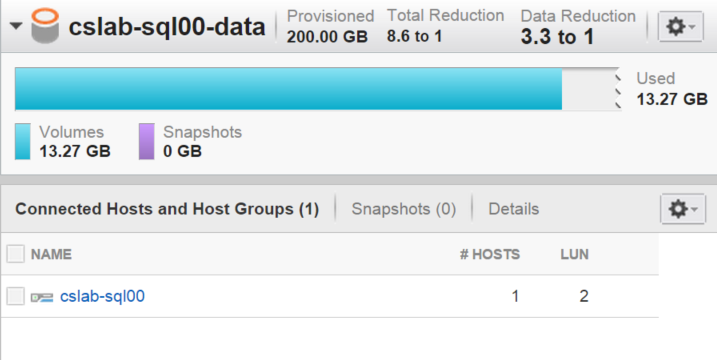
Mind you, the StackOverflow database file (.mdf) and transaction log (.ldf) are the only files in this volume. To give you an idea of what kind of compression ratio you would get from the uncompressed data, this is what I showed once I rebuilt all indexes with DATA_COMPRESSION=NONE:
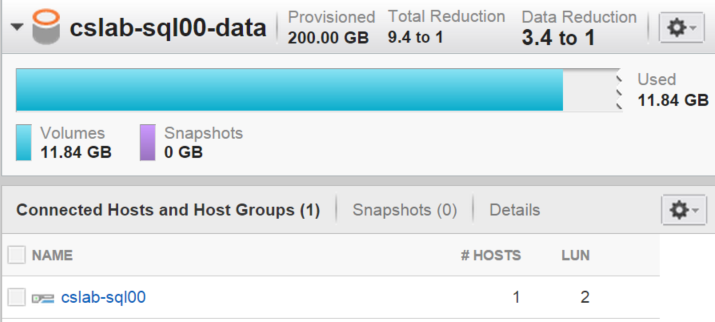
Now some of you might be saying “Hey! This is an edge case – the big majority of the pages in the entire database are in LOB_DATA allocation units!” I agree with you, but this is just one example – that of a very well known database. Here’s another data point: at my previous job, where we used a FlashArray, the main database (~11TB in size) compressed at a very healthy 3:1 ratio.
Summary
Pure Storage’s FlashArray can indeed help you reduce your data footprint on your already natively-compressed database structures. After all, those LOB data types in SQL Server (nvarchar(max), ntext, XML, etc) are, unfortunately, more common than you might think.



