L’informatique parallèle et l’informatique distribuée existent depuis longtemps et ont grandement contribué à l’amélioration des processus informatiques. Cependant, elles présentent des différences essentielles au niveau de leur fonction principale.
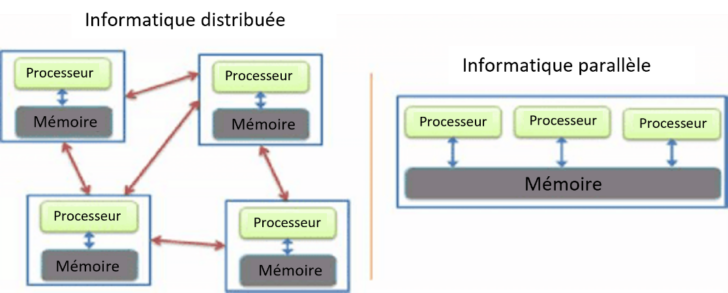
L’informatique parallèle, ou traitement parallèle, accélère une tâche de calcul en la divisant en tâches plus petites réparties sur plusieurs processeurs au sein d’un même ordinateur. L’informatique distribuée, quant à elle, utilise un système distribué, comme Internet, pour augmenter la puissance de calcul disponible et permettre l’exécution de tâches plus importantes et plus complexes sur plusieurs machines.
Source : ResearchGate
Qu’est-ce que l’informatique parallèle ?
Le traitement parallèle consiste à effectuer des tâches de calcul sur plusieurs processeurs à la fois afin d’améliorer la vitesse et l’efficacité du calcul. Les tâches sont divisées en sous-tâches et exécutées simultanément par différents processeurs.
Il existe trois principaux types de parallélisme :
- au niveau des bits : utilisation de « mots » plus grands, c’est-à-dire de données de taille fixe traitées comme une unité par le jeu d’instructions ou le matériel du processeur, afin de réduire le nombre d’instructions dont le processeur a besoin pour effectuer une opération ;
- au niveau de l’instruction : emploi d’un flux d’instructions pour permettre aux processeurs d’exécuter plus d’une instruction par cycle d’horloge (oscillation entre les états haut et bas dans un circuit numérique) ;
- au niveau de la tâche : exécution du code informatique sur plusieurs processeurs afin de réaliser plusieurs tâches en même temps avec les mêmes données.
Qu’est-ce que l’informatique distribuée ?
Le traitement distribué est un processus qui consiste à connecter plusieurs ordinateurs via un réseau local ou un réseau étendu afin qu’ils puissent agir ensemble comme un seul ordinateur ultra-puissant, capable d’effectuer des calculs qu’aucun ordinateur du réseau ne pourrait réaliser seul.
Les ordinateurs distribués présentent deux avantages :
- Évolutivité simplifiée :il suffit d’ajouter des ordinateurs pour étendre le système.
- Redondance : puisque plusieurs machines différentes fournissent le même service, ce dernier peut continuer à fonctionner même si un ou plusieurs ordinateurs tombent en panne.
Informatique parallèle : bref historique
Les premiers ordinateurs parallèles ont été esquissés dans les années 1950, lorsque d’éminents chercheurs et informaticiens, notamment d’IBM, ont publié des articles sur les possibilités (et la nécessité) du traitement parallèle pour améliorer la vitesse et l’efficacité des calculs. Plus tard, dans les années 1960 et 1970, apparaissent les premiers superordinateurs, qui utilisent pour la première fois des processeurs multiples.
L’objectif derrière le développement des premiers ordinateurs parallèles était de réduire le temps de transfert des signaux sur les réseaux informatiques, au centre des ordinateurs distribués.
Le traitement parallèle a atteint un autre niveau au milieu des années 1980, lorsque des chercheurs du Caltech ont commencé à utiliser des processeurs massivement parallèles pour créer un superordinateur destiné à des applications scientifiques.
Aujourd’hui, les processeurs multicœurs sont devenus monnaie courante et les efforts en matière d’efficacité énergétique ont mis l’accent sur le traitement parallèle, car il améliore les performances et tend à être beaucoup plus économe en énergie que l’augmentation des fréquences d’horloge des microprocesseurs.
Principales différences entre l’informatique parallèle et l’informatique distribuée
Les ordinateurs parallèles et distribués sont des technologies importantes, mais ils présentent plusieurs différences essentielles.
Différence n° 1 : le nombre d’ordinateurs nécessaires
Le traitement parallèle nécessite généralement un ordinateur doté de plusieurs processeurs. Le traitement distribué, en revanche, implique plusieurs systèmes informatiques autonomes (et souvent géographiquement séparés et/ou éloignés) travaillant sur des tâches divisées.
Différence n° 2 : l’évolutivité
Les systèmes informatiques parallèles sont moins évolutifs que les systèmes distribués, car la mémoire d’un seul ordinateur ne peut gérer qu’un nombre limité de processeurs à la fois. Un système informatique distribué peut toujours évoluer via l’ajout d’ordinateurs supplémentaires.
Différence n° 3 : la mémoire
Dans l’informatique parallèle, tous les processeurs partagent la même mémoire et communiquent entre eux à l’aide de cette mémoire partagée. Les systèmes informatiques distribués, quant à eux, disposent de leur propre mémoire et de leurs propres processeurs.
Différence n° 4 : la synchronisation
Dans l’informatique parallèle, tous les processeurs partagent une horloge principale unique pour la synchronisation, tandis que les systèmes informatiques distribués utilisent des algorithmes de synchronisation.
Différence n° 5 : l’utilisation
Le traitement parallèle est utilisé pour augmenter les performances des ordinateurs et pour les calculs scientifiques, tandis que le traitement distribué sert à partager les ressources et améliorer l’évolutivité.
Utilisation de l’informatique parallèle : exemples
Cette méthode de calcul est idéale pour les simulations ou les modélisations complexes. Parmi les applications courantes, on peut citer les études sismiques, les modélisations numériques en astrophysique, les modélisations climatiques, la gestion des risques financiers, les estimations agricoles, la correction des couleurs vidéo, l’imagerie médicale, la découverte de médicaments et la mécanique des fluides numérique.
Utilisation de l’informatique distribuée : exemples
L’utilisation de l’informatique distribuée est particulièrement indiquée pour la création et le développement d’applications puissantes impliquant un grand nombre d’utilisateurs et de zones géographiques. Lorsqu’on effectue une recherche sur Google, on utilise déjà le traitement distribué. Les architectures de systèmes distribués ont façonné une grande partie des « solutions modernes », y compris le cloud computing, l’informatique de périphérie et les logiciels en tant que service (SaaS).
Quel est le meilleur système : parallèle ou distribué ?
Il est difficile de déterminer quel type de traitement est « mieux » que l’autre, car cela dépend du cas d’utilisation (voir la section ci-dessus). Si vous avez uniquement besoin de puissance de calcul et que vous travaillez dans un domaine scientifique ou un autre secteur fortement axé sur l’analytique, il est probablement préférable d’opter pour l’informatique parallèle. Si vous avez besoin d’évolutivité et de résilience et que vous pouvez vous permettre de créer et d’entretenir un réseau informatique, il vaudra mieux vous tourner vers l’informatique distribuée.
Written By: