La maggior parte delle startup, magari dopo una fase prototipale con risorse minimali, inizia a costruire le proprie piattaforme di data processing e data science su cloud provider pubblici. Questo dà loro velocità e flessibilità nella fase di avvio.
Tuttavia, nel tempo, far crescere una data pipeline nel cloud di pari passo con le esigenze del business può diventare un costo o un peso per diverse ragioni e le architetture software e hardware utilizzate devono necessariamente adattarsi e cambiare rispetto a nuove esigenze e scenari
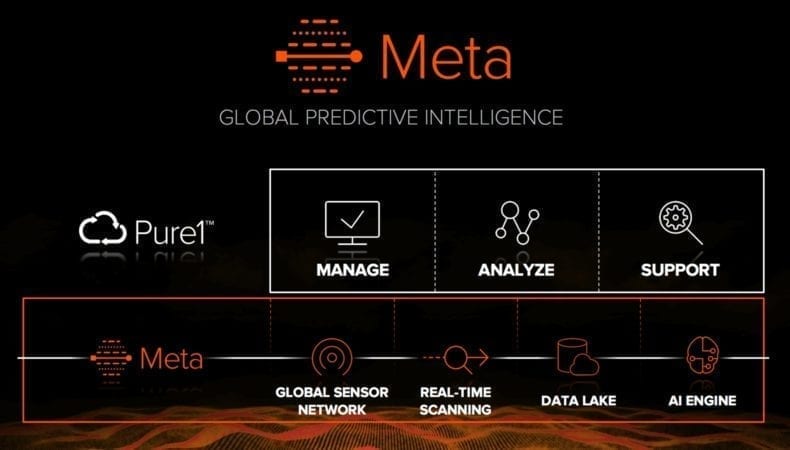
Anche Pure1 è nato nel cloud. Non solo è cloud-native ma è anche “born in the cloud” e, come vedremo, si è mosso su una strada che ha un canone inverso rispetto a quanto siamo abituati a vedere nella gran parte dei percorsi verso il cloud.
Originariamente nato come sistema dedicato al supporto tecnico di Pure Storage nella diagnosi e correzione dei problemi dei clienti, Pure1 è evoluto in un formidabile strumento di gestione e analisi, sia per i clienti di Pure Storage sia per team di supporto tecnico e engineering dell’azienda.
Oggi raccoglie dati da quasi 20.000 array di 7.800 clienti, con volumi di ingestion giornaliera di circa 30TB al giorno e una magnitudine totale di dato memorizzato di circa 15PB.
Nel post affronteremo i temi della raccolta e valorizzazione dei dati di telemetria raccolti giornalmente dagli array sparsi nei data center dei nostri clienti: come il dato raccolto viene raccolto e usato a valore, quali scelte architetturali sono state fatte e come solo evolute nel tempo e come FlashBlade abbia giocato un ruolo fondamentale in una architettura cloud ibrida.
Il focus del post è raccontare tutto ciò che c’è dietro le quinte in un’ottica inside-out, quali sono le basi e i punti di forza di una tecnologia abilitante fatta di tante componenti e scelte. Per la prospettiva outside-in, quanto valore eroga la soluzione e come risponde ai bisogni di clienti e partner, vi consiglio di leggere questo bel post di Umberto che spiega molto bene quali sono i vantaggi e le opportunità che Pure1 mette a disposizione.
Pure1
Pure1 è uno strumento web-based a cui i clienti Pure Storage hanno accesso per monitorare le proprie appliance (FlashArray, FlashBlade e Cloud Block Store): assolve funzioni di monitoring, fault management e analytics sugli apparati Pure.
E’ anche il principale responsabile di tutti i meccanismi di Predictive alerting che aiutano Pure a mantenere in perfetta efficienza l’infrastruttura dei clienti, motivo che nel tempo ne ha caratterizzato l’altissima soddisfazione.
Immaginate una rete distribuita globalmente di decine di migliaia di endpoint, rappresentati dai sistemi dei nostri clienti, che ogni 30 secondi e ogni ora, inviano dati di telemetria e diagnostica in forma cifrata e vengono raccolti e trattati, valorizzandoli, centralmente.
Questi metadati includono log, statistiche di performance e alert degli array.
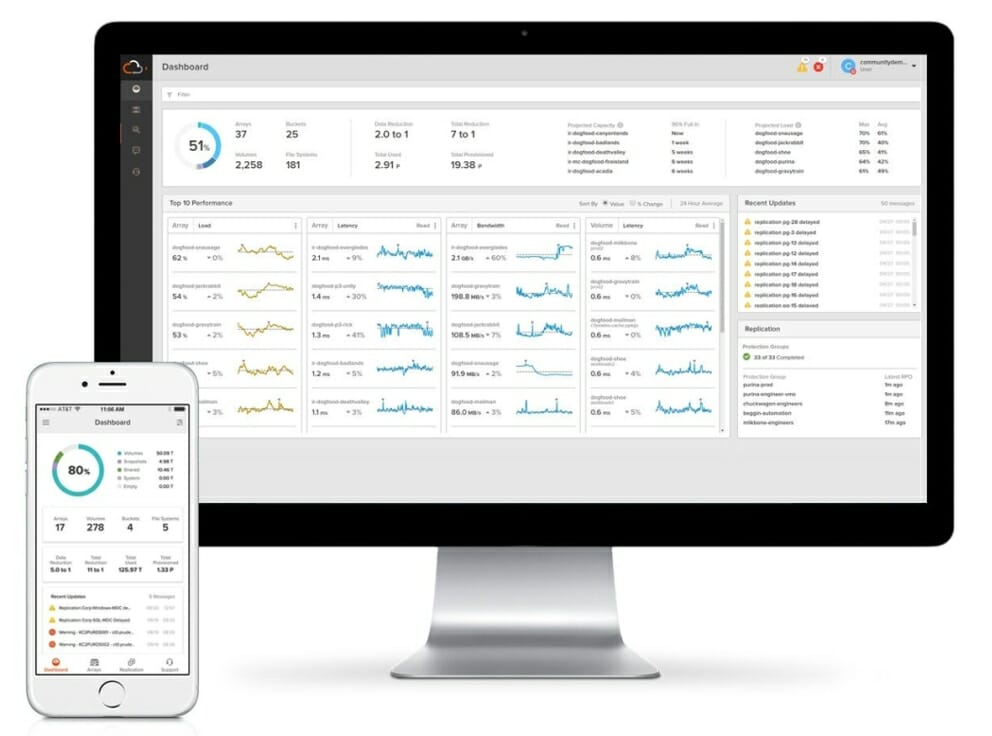
Pure1 li memorizza, li elabora e li presenta sotto forma di dashboard, grafici e pannelli di analisi e di controllo affinché utenti autorizzati (clienti, partner e personale di Pure) possano averne accesso per visualizzare le prestazioni dei sistemi, la loro storia di utilizzo, tracciare alert e case e eseguire sofisticate analisi predittive.
Proviamo a vedere più nel dettaglio cosa succede a questi dati e come è strutturata la data pipeline di Pure1.
Data Collection & Pipeline
Partiamo dai sistemi che alimentano Pure1 e percorriamo la strada dei log di diagnostica attraverso queste 6 fasi.
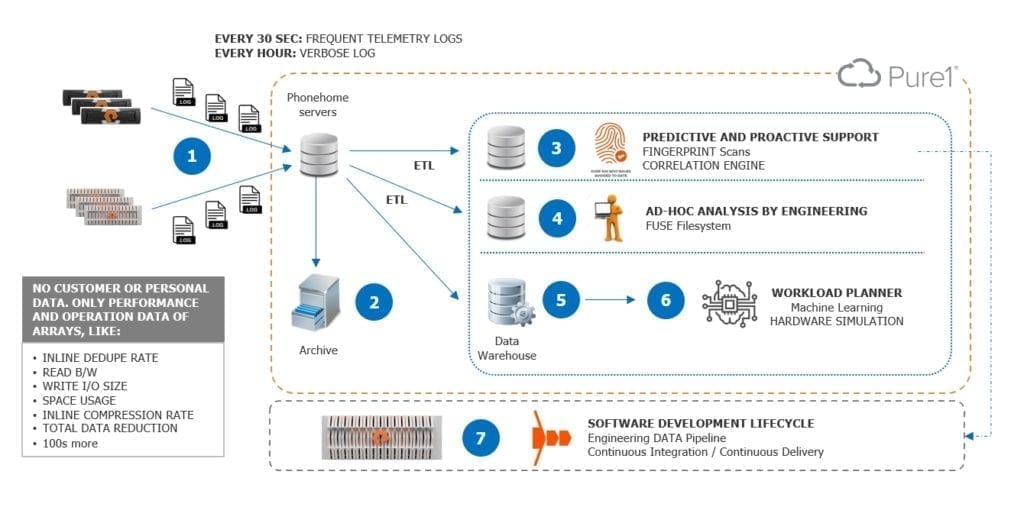
1. Ingestion
I sistemi connessi inviano costantemente metadati di performance, status e alert ai server di phonehome. Nel nostro caso la destinazione è un insieme di virtual machine in public cloud
2. Archive
A mano a mano che i dati invecchiano e sono acceduti meno frequentemente, questi sono passati ad un livello di archiviazione inferiore. Questo serve a ridurre i costi di gestione del dato nel public cloud
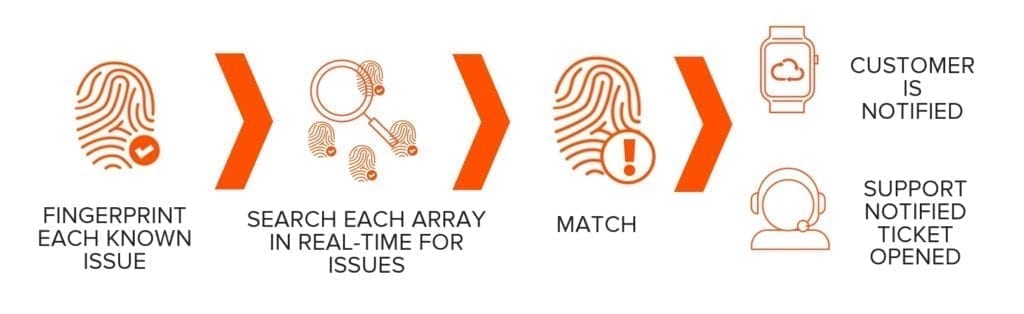
3. Analisi e scansione di issue note
Algoritmi automatizzati effettuano scansioni dei dati raccolti per ricercare tracce (fingerprint) di issue note in modo che i problemi possano essere prevenuti prima che insorgano sugli array dei clienti. Gli sviluppatori Pure hanno accesso a questi dati che analizzano per valutare le prestazioni e l’affidabilità del software.
4. Analisi Ad Hoc
L’engineering Pure di prodotto, ha accesso ai dati granulari per analisi ad-hoc: tipicamente per individuare, diagnosticare e rimediare ai problemi non noti e che non sono stati individuati dai meccanismi di fingerprinting.
5. Consolidamento dei dati in Data Warehoue
I dati sono consolidati e storicizzati in forma strutturata per poter effettuare analisi storiche
6. Machine Learning and Simulation
Gli utenti Pure1 possono usare modelli predittivi per simulare scenari di crescita delle proprie macchine e pianificarne l’approvvigionamento. Mediante sofisticati meccanismi di Machine Learning, con Pure1 è possibile avere risposta a domande del tipo: come crescerà la capacità e le performance del mio sistema? come saranno le prestazioni nel momento in cui aggiornerò i sistemi ad un modello superiore? E se attestassi un nuovo workload su quella macchina, cosa succederebbe?
In sintesi: i dati che arrivano su Pure1 non si limitano a rimanere in attesa che i clienti li interroghino.
- gli ingegneri dello sviluppo Pure Storage li usano per valutare le prestazioni e l’affidabilità delle versioni del software.
- i Technical Support Engineer lo usano per diagnosticare i problemi dei clienti
- script automatici passano in rassegna i dati per identificare matrici note di “impronte digitali” di problematiche per avvisare proattivamente i clienti di potenziali problemi prima che questi possano emergere
- i data scientist dell’azienda costruiscono modelli basati su machine learning che i clienti possono usare per prevedere le loro prestazioni di I/O e le previsioni di capacità.
L’evoluzione della architettura
Pure1 è nato nel cloud 10 anni fa con i primi clienti: sorgenti dati distribuite globalmente, crescita rapidissima del dato e la necessità di una implementazione rapida hanno di fatto imposto questo tipo di scelta.
Oggi, con 7800 clienti nel mondo e con la continua crescita della base installata, va da sé che il volume del dato gestito è in continuo aumento. Da pochi MB raccolti al giorno 0, ad oggi i sistemi dei nostri clienti inviano decine di TB giornalmente a Pure1.
A un certo punto nel tempo, un’analisi dei costi di archiviazione del cloud ha determinato che circa la metà del costo era dovuta all’archiviazione dei dati attivi (gli ultimi 30 giorni di log), il 20% era per i dati inattivi di livello inferiore e il restante 30% era dovuto al trattamento (query e interrogazione) di dati memorizzati.
In media, i dati archiviati venivano recuperati (letti) circa 8 volte complessivamente dai processi di analisi, ETL e machine learning. Questo paradigma è tipico dei modelli di machine learning e dei sistemi di analytics ed è noto come read amplification. Ed è anche una conseguenza dalla politica dei cloud provider che tendono a non far pagare nulla per l’ingestion dei dati, ma prevedono dei costi per il trattamento una volta che il dato è atterrato sulle loro piattaforme.
La stessa cosa avviene per Pure1: il costo dell’invio dei log dei sistemi non è significativo, ma ogni volta che un’applicazione legge un log, viene addebitato un costo e come abbiamo visto i log sono sottoposti a diversi trattamenti in diverse fasi.
Poiché Pure non era disposta a ridurre la quantità di dati archiviati, ha deciso di ridurre il costo dell’I / O per i dati archiviati; e anche di aumentare le prestazioni.
Cloud ibrido
Per ridurre i costi di I/O del cloud, abbiamo deciso di utilizzare un approccio ibrido. Il servizio cloud usato da Pure offre un servizio di connessione diretta per sfruttare più collegamenti da 10 Gb / s dai loro data center ai data center gestiti di colocation attraverso i loro partner.
In colocation è stato posizionato FlashBlade come storage centralizzato. Come già descritto in questo post, è un prodotto Pure e ha caratteristiche di capacità, performance e disponibilità – e supporto per S3 – che ne hanno fatto un candidato ideale.
Nonostante questo, il team di sviluppo di Pure1 ha esplorato diverse altre configurazioni hardware e software, ma quando il costo dell’implementazione e della manutenzione dello storage è stato incluso nell’analisi, la completezza di una soluzione come FlashBlade l’ha resa la scelta ovvia.
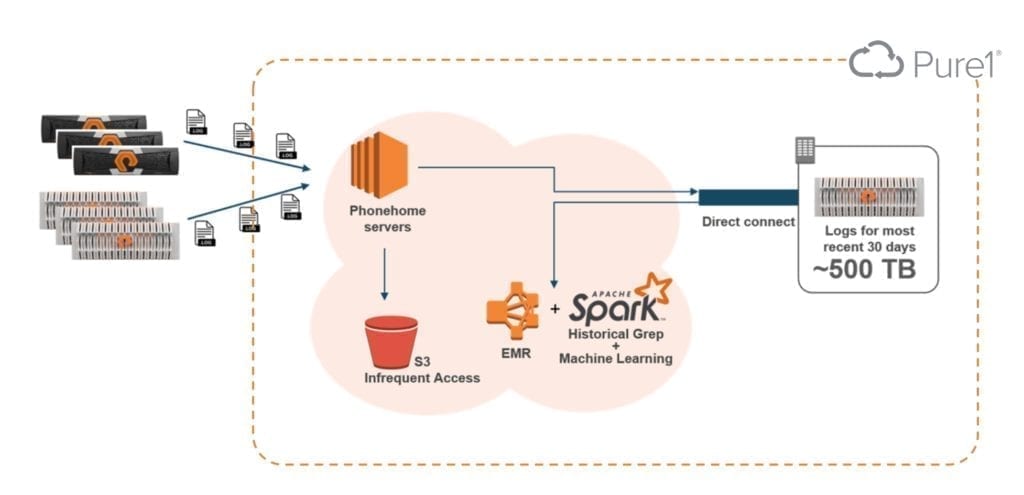
La ragione per cui questo ha senso dal punto di vista dei costi è che una volta archiviati i dati su un dispositivo in colocation, esterno al cloud provider, accedervi è praticamente gratuito e sicuramente meno costoso del cloud. Questo aiuta tantissimo specie per il fattore 8x delle letture medie rispetto alle scritture.
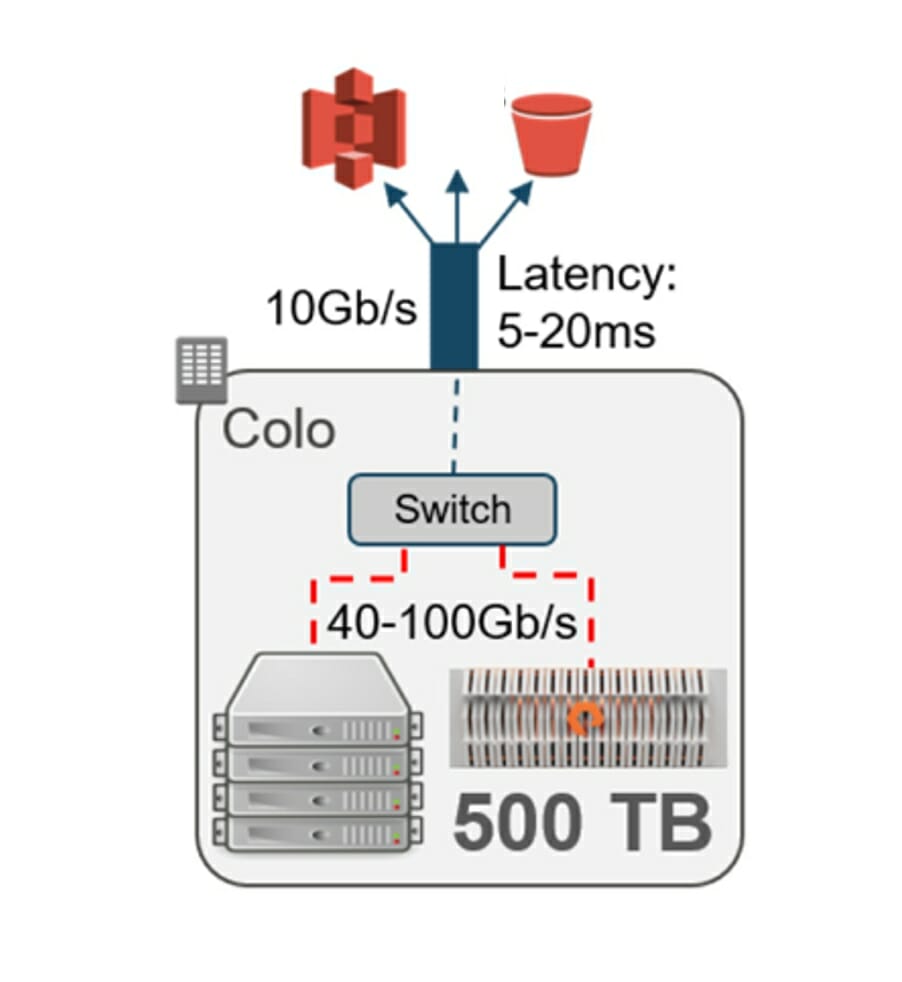
Per aggiungere prestazioni il passaggio successivo è stato quello di sostituire lo switch da 10 Gb / s in colocation con uno di capacità 40-100 Gb / s e compute locale. Collegamenti ad alta velocità tra lo storage e le applicazioni locali hanno migliorato notevolmente le prestazioni, in alcuni casi di un ordine di grandezza.
Conclusioni
Nell’implementare un cloud ibrido l’obiettivo del team Pure1 era duplice: ridurre il costo di trattamento del dato nel public cloud e aumentare le prestazioni delle applicazioni.
Poiché le applicazioni della data pipeline leggono i dati dallo storage in colocation anziché dal cloud pubblico, i relativi costi di lettura non sono più sostenuti. Questo è particolarmente vantaggioso per tutte le componenti di Machine Learning incluse in Pure1 che prevedono necessariamente ripetuti passaggi sui dati durante le sessioni di training.
Aggiungere compute locale e uno storage all-flash di tipo scale out come FlashBlade si è dimostrata la scelta giusta per aumentare le prestazioni di workload orientati alle letture, latency-sensitive e ad elevata larghezza di banda
In caso di approfondimento vi consiglio di vedere questo video in cui viene spiegato più nel dettaglio quali scelte architetturali sono state fatte e come solo evolute nel tempo e come FlashBlade abbia giocato un ruolo fondamentale in una architettura cloud ibrida.
Contattatemi per ulteriori informazioni, sarò felice di aiutarvi.
Luca Rossetti Systems Engineer
T @lucaR055



