

以前のブログ「Portworx でパブリック・クラウドのコンテナ・コストを大幅に削減」では、Kubernetes のデータ・サービス・プラットフォームである Portworx をご利用いただくことで、パブリック・クラウドのコンテナ・コストを大幅に削減できるという内容をご紹介しました。今回は、Portworx がパブリック・クラウドにおいてコンテナ・データの可用性を向上させる仕組みについてご紹介します。なお、本ブログの一部は、Kai Davenport による記事をもとに、わたくし溝口が日本語化および加筆、再構成したものです。
EBS フェイルオーバー時の問題を解決
EBS のフェイルオーバー
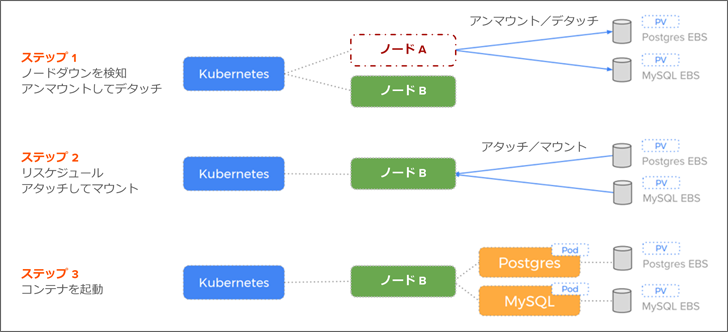
コンテナで永続データ、特にデータベースや重要なデータを持つ場合には、レプリケーションやフェイルオーバーは欠かせない機能となります。通常、コンテナ・ノードがダウンした際には、次のような手順で EBS(Amazon Elastic Block Store)をフェイルオーバーします。
- ノードダウンを検知し、ダウンしたノードから EBS ボリュームをアンマウントしてデタッチする。
- ノード上のコンテナを別のノードにリスケジュールし、上記の EBS ボリュームを新しいノードにアタッチする。
- EBS ボリュームを使いながらコンテナを起動する。
上記の手順には、エラーの原因となりやすい操作がいくつか含まれています。
- ダウンして反応しないノードからブロック・デバイスをデタッチ
- 新しいノードにブロック・デバイスをアタッチ
- 新しいコンテナにブロック・デバイスをアタッチ
これらの操作では、API コール、ルートユーザー権限によってコマンドを実行しますが、ここでさまざまな問題が発生します。下記に例を示します。
- AWS への API コールが失敗する。
- 障害ノードから EBS ドライブのアンマウント、デタッチに失敗する。
- 移行先ノードが既に EBS ボリュームの制限数に達している。
- 移行先ノードがマウント・ポイント数の上限に達している。
インターネット上で「stuck ebs volumes」で検索すると、多くの現象が報告されていることがわかります。

コンテナと物理ストレージの分離
Portworx では、上述のような問題への対策として、コンテナから見えているボリュームから物理ストレージを分離します。
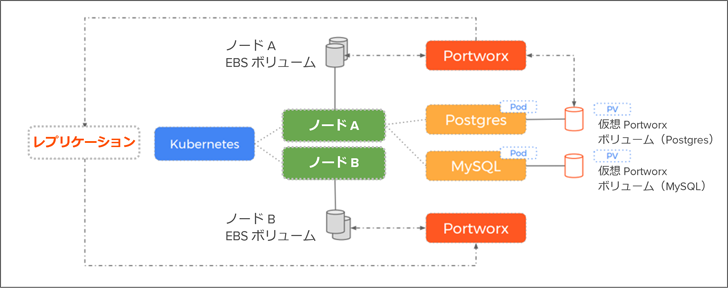
さらに、Kubernetes スケジューラと Portworx の連携により、ポッドはレプリケーションが配置されているノードに優先的に再配置されます。これにより、フェイルオーバーはよりシンプルになり、切り替え時間も格段に短くなります。
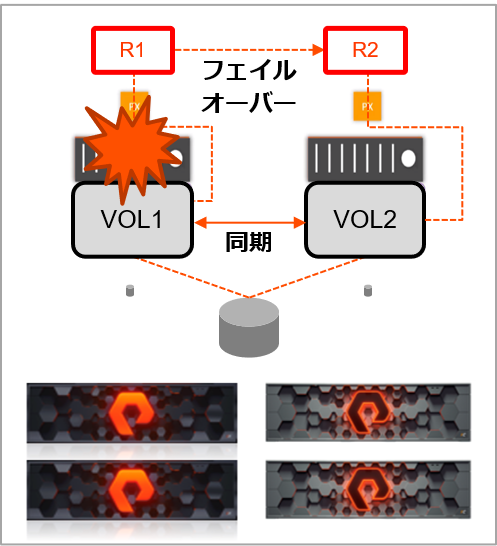
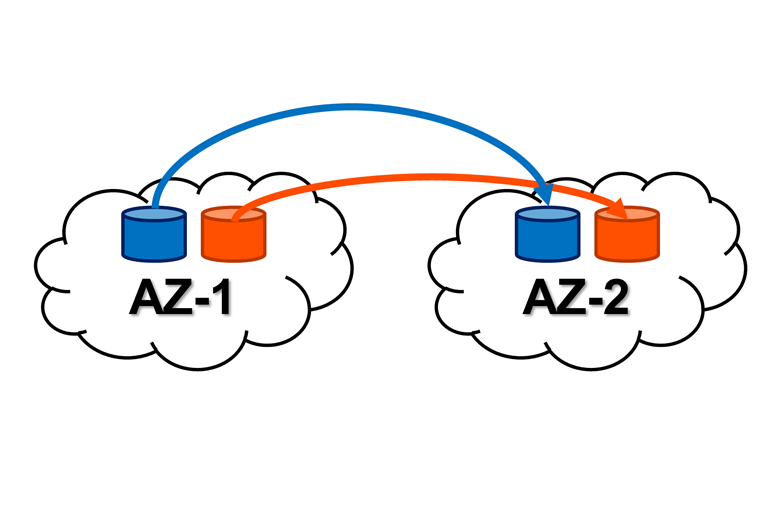
アベイラビリティ・ゾーンをまたいだレプリケーション
EBS ボリュームを作成すると、そのボリュームは同じアベイラビリティ・ゾーン(AZ)内で自動的にレプリケートされます。一方、Portworx 永続ボリュームは、前述のとおり、コンテナから見えているボリュームと物理ストレージを分離します。ソフトウェア定義のストレージ(SDS:Software-Defined Storage)として仮想ボリュームを作成し、自らのレプリケーション機能で AZ 間での同期レプリケートができるようになります。そのため、ステートフル・ポッドまたはホストが失われた場合に、Kubernetes は、別の AZ であっても、ダウンタイム中にクラスタ内の他のホストに再スケジュールすることで、可用性を高めます。
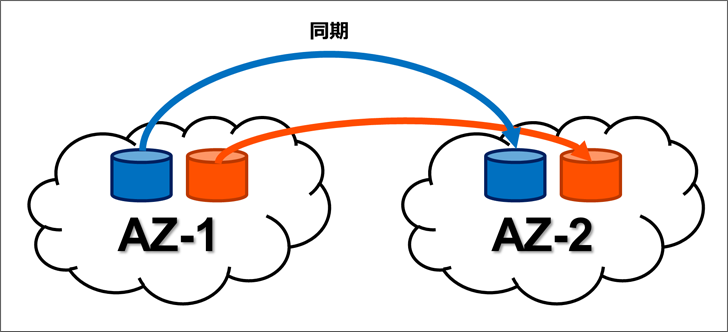
注:同期は一方向のみで、AZ-2 のボリュームは、同期元の AZ-1 のボリュームが見えなくなったときに、AZ-1 のボリュームを参照していたコンテナが AZ-2 のボリュームを参照するようにスケジュールされます。
今回は、SDS である Portworx ならではの同期レプリケーションと、コンテナから見えるボリュームと物理ストレージの分離によるシンプルかつ迅速なフェイルオーバーをご紹介しました。Portworx は、これらの機能によって、パブリック・クラウドにおけるコンテナ・データの可用性を向上させます。
Portworx をクラウドでご利用いただくことで、大幅なコスト削減も可能になります。以下の記事もあわせてご参照ください。
Pure Storage、Pure Storage のロゴ、およびその他全ての Pure Storage のマーク、製品名、サービス名は、米国およびその他の国における Pure Storage, Inc. の商標または登録商標です。その他記載の会社名、製品名は、各社の商標または登録商標です。