
주식시장의 리스크를 예측하는 은행, 사용자 맞춤형 쇼핑 경험을 제공하는 온라인 기업 등 오늘날의 비즈니스에서 데이터 처리 및 분석의 가치는 어마어마합니다. 그리고 그 중심에는 데이터 과학자가 있습니다.
데이터 과학자는 슈퍼히어로입니다. 소프트웨어 1.0의 시대를 소프트웨어 개발자와 프로그래머가 이끌었다면 소프트웨어 2.0 시대는 데이터 과학자들이 주도하고 있습니다. 데이터 과학자들은 컨브넷(ConvNet)이나 회귀트리(regression tree)를 활용해 인공지능(AI) 중심의 솔루션을 구축하며, 매개변수 최적화, 모델 탐구, 트레이닝, 평가 및 시각화를 통해 데이터의 숨겨진 의미를 파악하는 예측 모델을 구축합니다. 그리고 궁극적으로 저희가 데이터 과학자들에게 원하는 바는 혁신적인 머신러닝 알고리즘을 구축하는 것입니다.
그러나 데이터 과학자들의 업무의 80%를 차지하는 것은 알고리즘 연구가 아닌 데이터 준비와 파이프라인 관리입니다. 일련의 느리고, 수동적인 절차로 이뤄진 업무 탓에 데이터 과학자들은 많은 시간을 가만히 앉아 기다리는 데에 허비하고 있습니다.
더 이상의 기다림은 없다
최근 “GTC 유럽” 컨퍼런스에서 NVIDA는 GPU 상에서 데이터 과학과 애널리틱스를 가속화하는 RAPIDS 오픈소스 소프트웨어를 발표했습니다. RAPIDS는 데이터 과학자들이 시간의 80%를 쏟는 업무에 대량 병렬 GPU 사용을 가능하게 해, 데이터 준비에서 머신러닝 모델 트레이닝에 이르는 전체 인공지능 파이프라인을 가속화할 뿐 아니라, 새로운 툴을 학습할 필요 없이 데이터 과학자들의 생산성을 향상시킵니다. 이에 따라, 데이터 과학자들은 모델들을 더 빠르게 반복할 수 있고, 모델 적용 빈도를 높일 수 있어 모델의 정확도가 높아집니다.
RAPIDS 오픈소스 소프트웨어의 주요 이점은 다음과 같습니다:
- 모델 반복 속도와 용도를 높여 머신러닝 모델 정확도 향상
- 워크스테이션에서 멀티 GPU 서버, 그리고 멀티노드 클러스터로의 쉬운 확장
- Apache Arrow에 구축되어 맞춤화, 확장 및 데이터 과학 툴체인과의 상호 운용 가능
RAPIDS는 데이터 과학계의 든든한 뒷받침입니다. 퓨어스토리지는 NVIDIA와 퓨어스토리지의 고객들에게 지속적으로 더 큰 가치를 제공하는 NVIDIA의 노력을 뒷받침할 수 있어 매우 기쁘게 생각합니다.
플래시블레이드(FlashBlade): 인공지능 파이프라인을 위한 데이터 허브
인사이트를 가장 빠르게 확보하는 방법은 GPU를 계속 활용하는 것입니다. 퓨어스토리지의 고객인 ElementAI가 기존 스토리지 솔루션을 이용했을 때는GPU 사용률이 20%밖에 되지 않았습니다. 그러나 플래시블레이드(FlashBlade)를 데이터 허브로 사용함에 따라, GPU 사용률이 100% 가까이로 치솟았으며, 데이터 과학자들이 모델을 더 빠르게 트레이닝할 수 있게 되었습니다.
최신의 고성능 스케일-아웃 공유형 스토리지 플랫폼은 가장 중요할 뿐 아니라 RAPIDS를 이용해 자체적인 인공지능 워크플로우를 구축하려는 고객들에게 필수적입니다. 첫째, 공유형 스토리지는 각 파이프라인 단계별로 데이터 서브세트를 수동으로 복사할 필요를 제거해 엔지니어링 시간을 단축하고, GPU 사용률을 개선시킵니다. 또한 데이터 과학자들이 워크플로우를 쉽게 공유하고, 데브옵스 환경에서 개발된 모델을 어플리케이션에 쉽게 통합할 수 있게 해 데이터 과학자들의 협업을 촉진합니다. 둘째, 여러 데이터 과학자들이 데이터 세트와 모델을 탐구하기 때문에, 데이터를 네이티브 포맷으로 저장해 개별 사용자가 데이터를 변형하고, 데이터를 정제하고, 개별적으로 데이터를 사용할 수 있도록 유연성을 주는 것이 중요합니다. 다양한 경험을 통해 더 강력한 모델을 만들 수 있기 때문입니다. 마지막으로 고성능 공유형 스토리지는 점점 늘어나는 데이터 세트의 저장뿐 아니라 전체 인공지능 파이프라인에 있어 매우 중요합니다.
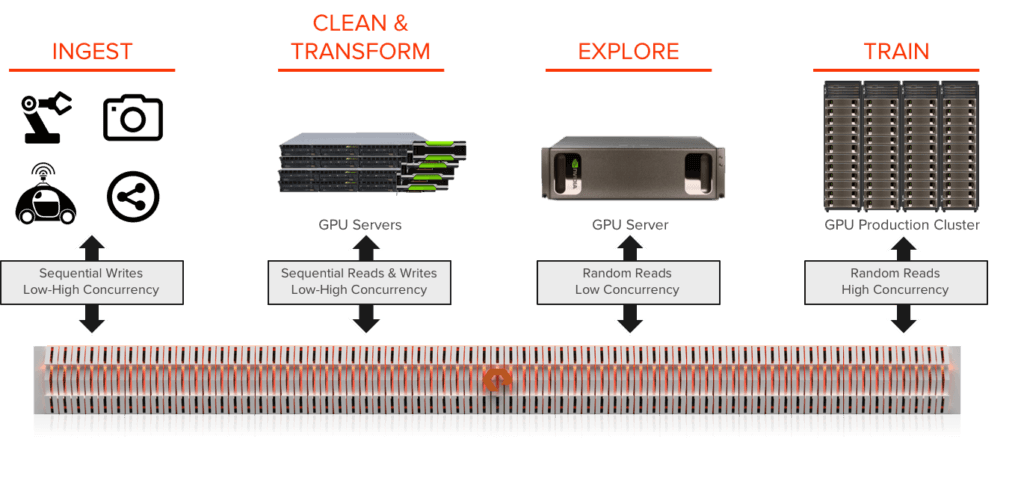
플래시블레이드(FlashBlade)의 데이터 허브 아키텍처는 애널리틱스와 인공지능을 뒷받침하기 위한 이상적인 스토리지 플랫폼을 제공합니다. 데이터 허브는 인공지능 파이프라인의 4가지 특징: 대용량 처리성능을 요구하는 파일 및 오브젝트, 네이티브 스케일-아웃, 다차원적 성능, 대량 병렬구조의 아키텍처를 하나의 플랫폼에 통합시킵니다. RAPIDS와 통합된 데이터 허브는 기업들이 데이터 사이언스 팀들과 빠르게 데이터를 공유할 수 있게 해, 생산성을 극대화하고, 협업을 도모하고, 모델을 더 빠르게, 더 높은 민첩성으로 개발할 수 있게 해줍니다.
보다 많은 내용은 www.RAPIDS.ai를 방문하시거나 퓨어스토리지에 문의 주세요. 여러분의 인공지능 개발 과정에 플래시블레이드(FlashBlade)와 에이리(AIRI)가 제공할 수 있는 가능성을 보여드리겠습니다.



