Welcome to the second post in our four-part blog series, where we’re taking a look at what makes the combination of Portworx® and Pure Storage so awesome. If you’re a virtualization or enterprise storage ninja and getting bombarded with requests or questions from a Kubernetes platform or application architecture team, then this series is for you!
In Part 1, Virtualization Solves Enterprise Challenges, we went through an overview of all of the goodness that virtualization and enterprise storage has given us over the years. In this blog post, we’ll cover how containerization and Kubernetes came about and how that changed the way your application and developer teams consume infrastructure.
How We Got Here: The Helmsman Arrives!
We left off talking about “the aaS-ification of all the things” and how IaaS/PaaS/SaaS had taken off, giving way to a new method of developers and application architects consuming infrastructure. Now, let’s dig in a bit to understand containers, container orchestration, some modern application development challenges, and how they affect your ability to provide enterprise services.
Building On the Shoulders of Giants
Container-based technology is nothing new, just like virtualization and hypervisors were nothing new (at least on non-x86 architectures—see LPARs). In fact, we can trace the roots of containers all the way back to 1979 and the chroot process, which was introduced in UNIX V7. Whereas virtual machines give us the capability to separate out multiple operating systems running on a single bare metal server, chroot gives us the capability to create and separate virtualized copies of software systems within a single operating system.
Another way to look at this difference is that virtual machines emulate the entire “computer” entity—including hardware and everything required to run an operating system. However, containers run within an existing operating system and leverage resources within that operating system—representing a virtual userspace with separate CPU, memory, and filesystems to run protected processes. In terms of density, we can usually run three to four times more containers on a bare metal machine than virtual machines, due to not having several copies of the base underlying operating system binaries and libraries.
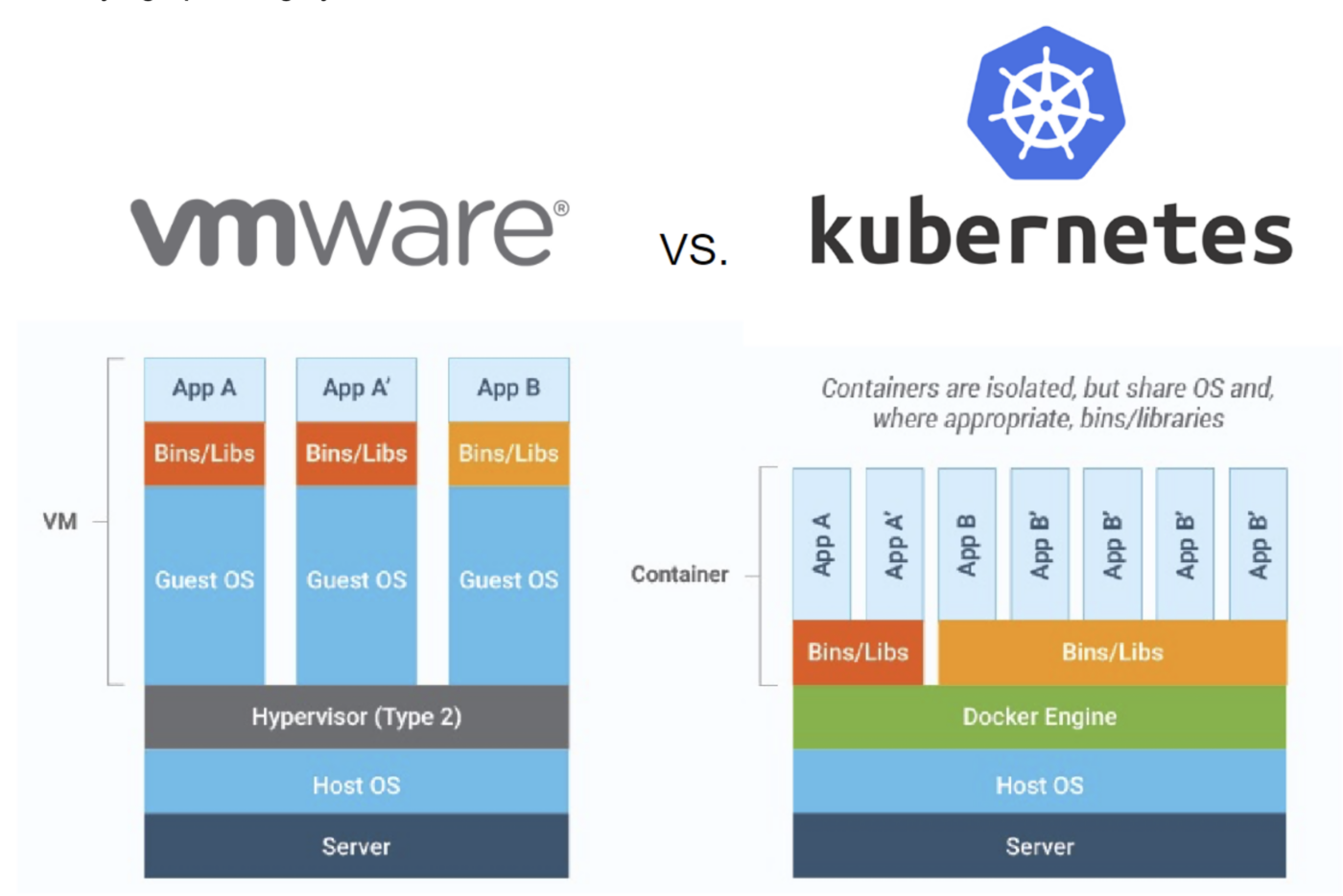
Figure 1: A comparison of the architecture of VMware virtual machines and Kubernetes containers.
Modern Containers Arrive on the Scene
Process containers were developed by Google around 2006 and were the real genesis of what we know as containers today. They were then renamed to cgroups and merged into the Linux kernel in 2008. These cgroups lacked a management structure around them to manage their lifecycles, and products such as Docker and Warden from Cloud Foundry were developed to handle lifecycle management for containers (think of VMware vCenter as a parallel).
None of the container management projects or products really took off until Docker arrived on the scene in 2013. Coincidentally, Portworx was founded shortly thereafter—and provided persistent storage functionality to containers. As a result, Docker was the primary installation target for early versions of Portworx.
Finding the Best Symphony Conductor and the Rise of CNCF
The explosion of container usage once Docker arrived brought a plethora of container orchestration products to market such as Docker Swarm, Apache Mesos, HashiCorp Nomad, Pivotal Cloud Foundry, and a new and interesting open-source project called Kubernetes from Google.
The landscape was confusing for many customers as is typical in any early technology adoption phase, with customers trying to determine “which horse to bet on.” Several of the orchestrators supported (and still support) free plus “Enterprise” versions that were paid offerings, but the x86 container community interest was largely piqued by Kubernetes, due to its 100% open-source approach to container orchestration.
Kubernetes began at Google in 2014, where its design was heavily influenced by the internal cluster manager Borg and developers that had worked on Borg. Kubernetes brought well-proven methods from Google’s internal usage experiences to manage, orchestrate, and automate the CRUD (Create/Read/Update/Delete) churn present in dynamic, container-based ecosystems. Google worked with the Linux Foundation to create the Cloud Native Computing Foundation (CNCF)—and Kubernetes 1.0 was released in 2015!
The Early Days of Portworx: Multi-orchestrator Madness!
All of the first customers of Portworx were Docker-based, “roll your own” implementations or using Docker Swarm. But with the “Orchestration Wars” still ongoing, customers were branching out and using Portworx with Mesosphere DC/OS, Nomad, and Pivotal products as well. By 2016 and into 2017, customers had gained interest in Kubernetes, and the balance of power for container orchestration had really come down to Kubernetes vs. Mesosphere.
By late 2017, the majority of container platforms had introduced Kubernetes support and Kubernetes had finally claimed its crown—by 2018, the majority of customers had moved to Kubernetes, and by 2019, Kubernetes was the primary orchestrator for consuming Portworx.
Now, you may have heard the term “Cattle vs. Pets” when looking at how modern application stacks and infrastructure are managed. The story behind this phrase is that instead of treating infrastructure like we did with VMs in the past (pets) with undying care and fragility, you should not care if infrastructure dies on you and everything should be replaceable (cattle)—this was the purist view of cloud-native infrastructure and DevOps. But how does this affect stateful applications that require persistent storage?
Ephemeral (non-persistent) storage was how Kubernetes assumed the majority of pods would consume storage from the beginning. Some purists still believe that ephemeral storage should be the only storage used within containerized applications and that persistent storage requirements should be serviced from outside Kubernetes and containers. However, there are still many applications that require persistent storage, and customers who wish to run these services inside of Kubernetes alongside their ephemeral containers!
Early in the Kubernetes timeline, storage vendors were contributing directly to the Kubernetes code base to provide persistent storage capabilities for their specific enterprise storage hardware (think VAAI/VASA/SPBM from a VMware perspective). However, direct vendor contribution to Kubernetes was heavy and did not scale well, so the Container Storage Interface (CSI) spec was born! This enabled vendors to write drivers out-of-tree without having to contribute directly to the Kubernetes code base and kept the velocity of Kubernetes releases as it should be—open source and separate from any single enterprise vendor.
Why External CSI Is Just a Shim
With CSI drivers moving out-of-tree, storage vendors had a choice of whether to do what they had always done and create integrations with their external storage controller hardware or to innovate and create cloud-native storage solutions. The majority of enterprise hardware arrays were not built to handle the churn of several thousand provisioning operations, snapshot/clone operations, or API requests per day that CRUD lifecycles created. Moving the control plane into Kubernetes for a true cloud-native storage experience was the only answer to keeping up with the CRUD churn.
Since most traditional CSI drivers rely on the external hardware controller features for things like snapshots, clones, and replication, consistency for app deployments that use or need these types of features must have the same hardware at each site. This approach is exactly what storage vendors want—as it allows them to sell “more boxes” and entrench themselves in the customer environment, creating vendor lock-in and forcing new model upgrades (but not with Pure Evergreen//One™, Evergreen//Flex™, or Evergreen//Forever™, by the way). The challenge for customers is that instead of focusing on providing innovative solutions within their applications, they now have to ensure that they’re running on the correct or specific storage hardware. This completely goes against the developer and app-centric model that we talked about in Part 1!
Portworx is a cloud-native solution that is backend storage agnostic and provides the agility, flexibility, and portability for customers to consume enterprise storage features regardless of where or what they’re running on—this prevents future “modernization” efforts from needing to occur if hardware or platforms change.
Common Challenges Between Traditional and Kubernetes Architectures
Whew. That was quite a bit of history on containers, orchestrators, and how stateful applications in Kubernetes have challenges with persistent storage across different platforms and infrastructure—thanks for sticking with me! If you’re like I was a few years ago in my career, it might feel overwhelming and there might be things you don’t understand, or you might be confused about how you can bring all of the enterprise goodness we’re accustomed to in virtualized environments over to Kubernetes infrastructure.
I went into Kubernetes blindly at first. I mean, I am a triple-VCAP, well-versed in Linux, have seen almost everything in the virtualization world, and helped companies become successful using those technologies, so this should be a breeze, right? Ha! When I was asked to start developing reference architectures and designs for our customers around stateful applications running on Kubernetes at my previous job, I continually ran into roadblocks. I learned that it’s not as simple as it seemed if I was going to provide the same enterprise features and architectures that I’d become accustomed to in the VMware realm.
These roadblocks were primarily due to limiting factors with the external CSI driver that had to be used with the specific hardware array I needed to include in these architectures. I could not develop a proper cloud-native architecture for stateful applications running in Kubernetes that would scale across on-premises, public cloud, and disparate hardware. I quickly understood what I needed was a consistent storage layer that could be used anywhere—with any backing storage that I wanted to provide—whether that was an enterprise array, an EBS or Azure Disk, or simple local drives from hyper-converged servers.
Let’s take a look at the same areas we discussed in Part 1 of our blog series on how virtualization changed experiences and how some of those challenges parallel experiences for stateful applications in Kubernetes environments. We’re not going to go into deep detail here—I have to save the amazing features and functionality of the Portworx platform for the next blog post! I’ll give you some teaser questions to ponder until we have our next discussion, though:
Application Availability
Kubernetes runs a scheduler that can dynamically deploy containers across available nodes in the Kubernetes cluster via deployments and daemonsets. However, a problem around storage availability for containers remains since persistent storage is a separate entity that relies on CSI functionality.
How do you think vSAN would help in this scenario in a VMware environment? What happens to VM storage when a node in a vSAN cluster goes down?
Resource Utilization
Cloud-native storage solutions for Kubernetes consume resources on your cluster nodes, and control plane resources will run as a workload on your cluster. It’s imperative that any cloud-native storage solution consumes a small footprint regardless of the number of volumes being provisioned or used.
What would your application workload capacity look like if ESXi hypervisor resources used exponentially more CPU and memory as you deployed more and more VMs?
Cost Management and Staff Skills
Storage management with Kubernetes, especially as organizations move toward multi-cloud environments, can be expensive—not only from an underlying volume perspective if things like thin provisioning and capacity management are not available but also from a staffing perspective.
What if you didn’t have the abstraction layer of VMFS for VMware storage? Would it be challenging to provide consistent enterprise services across disparate storage backends, not only from an operational perspective but also from a maintenance, troubleshooting, and staffing perspective?
Data and Application Portability
Applications in Kubernetes are deployed via YAML manifests. For stateful applications, moving between clusters or copying applications for blue-green testing requires two steps: First, copying or backup/restore of the underlying persistent storage, then a redeploy of the container (application) using the storage.
What if something like vMotion was available to migrate a container plus its persistent storage across Kubernetes clusters?
Capacity Management
Again, Kubernetes provides great capacity management from a CPU and memory perspective using its scheduler. However, capacity management for storage is left up to the storage provider being used. And again, this brings all kinds of challenges when a consistent storage layer is not provided. Thin provisioning and right-sizing storage is critical in dynamic, high-churn environments like Kubernetes clusters.
What if you had the capability to set policies on VMDKs in VMware to automatically grow a VMDK and expand the underlying filesystem as a function of VMFS or vSAN datastores? Would that be helpful and prevent VMs from stunning when their disks filled unexpectedly?
Storage Infrastructure
Since Kubernetes relies on CSI implementations to provide specific features for storage, ensuring that you have feature parity across disparate infrastructure is critical. Primitives such as snapshotting, volume migration, and replication are nice extras to have to match enterprise features we have in VMware infrastructure. But critical features such as being able to support the most popular volume modes in Kubernetes such as ReadWriteOnce (RWO) and ReadWriteMany (RWX) become very important as applications are deployed across different platforms and infrastructure.
What if vSphere snapshots didn’t exist, and you had to rely on the underlying storage hardware to snapshot your VMDKs? Would they be portable, consistent, and compatible?
Developer Agility
Developers typically build and deploy their applications themselves in Kubernetes environments. When persistent storage is needed, developers can create PersistentVolumeClaims (PVCs) that reference a StorageClass which defines specific storage capabilities they need. It’s very similar to how Storage Policy Based Management (SPBM) works in vSphere—a policy defines the storage capabilities (StorageClass) and can be referenced when requesting a vVol (PVC) to be provisioned. This allows self-service of persistent volume provisioning by the developer depending on the application’s storage requirements.
Before SPBM, were you able to easily provide developers with the ability to provision specific storage capabilities by themselves? What if they needed to provision a volume with similar capabilities, but were backed by different storage hardware at a different site?
Disaster Recovery
Kubernetes has no native disaster recovery built in for stateful applications. As we all know, having a consistent storage layer on both sides of a set of clusters to replicate between is critical to the success of a low-touch and proper disaster recovery plan in VMware—and it is no different in Kubernetes. Some vendors may lay claim to having disaster recovery solutions for Kubernetes with simple backup and restore. But the hard truth is, unless you’re able to tie into the storage layer and perform proper asynchronous and synchronous replication, disaster recovery as we’ve known it for years is impossible.
Would you rely on a simple backup and restore as the sole method for disaster recovery and to meet business-critical RPOs and RTOs in your business continuity plan in a VMware environment?
Security, Encryption, and RBAC
Encryption is built into Kubernetes for encrypting data within etcd (the configuration database for Kubernetes). Comprehensive role-based access controls exist for controlling access to objects within Kubernetes. But again, storage gets treated as a separate citizen within Kubernetes, and the storage solution used for persistent storage must support these primitives and features separately from Kubernetes.
Would you feel comfortable if every tenant in your private VMware cloud had unencrypted access to another tenant’s VMDKs?
Data Protection
Just like traditional bare-metal backup solutions had to transition to supporting VMware infrastructure, backup solutions for Kubernetes need to support all of the primitives used within a Kubernetes cluster for proper data protection. Being namespace-aware, having the capability for application-consistent backups, adhering to the 3-2-1 backup rule, providing ransomware protection, and the ability to restore to a separate Kubernetes cluster are critical features to support Kubernetes data protection.
Would you feel comfortable using a backup solution that was meant for bare metal for your VMware environment where you had to load a third-party agent onto every VM?
Performance
Storage performance for cloud-native storage solutions is critical and should not be dependent on other protocols to function in a performant manner. Native presentation of storage and file systems to the container should be used where possible to ensure high levels of IOPS and throughput, regardless of the I/O profile of the underlying application. In addition, the ability to control IOPS and throughput (think Storage I/O Control within VMware) is critical to prevent noisy neighbor situations on the Kubernetes cluster.
Would you couple highly performant CPU and memory with low-performance storage for applications that require high performance in a VMware environment? What are the challenges you might have if you could not control noisy neighbor situations and one VM was consuming all of the IOPS or throughput of the backing storage for a shared VMFS datastore?
What’s Next with Portworx?
In Part 3 and Part 4, we’ll cover how Portworx can provide the operational excellence that your platform consumers are looking for, how enterprise features you’ve been accustomed to providing can be deployed for Kubernetes and modern architectures, and how Portworx+Pure can be an absolute game-changer for you and your organization! Next up, we’ll cover how Portworx solves many of the enterprise challenges around storage in Kubernetes environments—just like VMware solved for virtualized environments. I can’t wait to describe and walk you through all of the features and benefits that Portworx can provide—and draw parallels to how Portworx orchestrates storage in the same manner that Kubernetes orchestrates compute!

Written By: