NVMe is a PCIe communications protocol designed with flash and modern architectures in mind. PCIe offers higher throughput than SAS and SATA, and the NVMe protocol is also lighter weight than SCSI or SATA. Pure designed the world’s first software-defined flash module to fully exploit the advantages of 100% NVMe as part of our FlashArray//X flagship product in 2017.

With storage solutions, fewer CPU cycles are consumed per IO, which becomes significant with the high IOPS of SSDs. Finally, multiple queues connect the native parallelism of flash with modern multicore CPUs making NVMe enabled solutions not only fast, but extremely efficient, for demanding applications.

Pure proved the advantages in performance and efficiency that NVMe brought to FlashArray//X when we shipped the industry’s first 100% enterprise solution. This week, we announced an entire FlashArray//X family providing the benefits of DirectFlashTM with 100% all flash storage, our 4th generation of product with NVMe technology.

The natural next step, is to bring the advantages of NVMe to systems that connect to storage over a network rather than PCIe. It is a great way to talk to storage, but connecting to SSDs over PCIe still has the disadvantages of direct-attached storage: capacity and management sprawl and limited intelligent storage services. What we really want is a way to talk to a FlashArray over it, so that servers get the efficiency of it, but also the full set of Purity services, including resiliency, thin provisioning, snapshots, and replication.
Fortunately, there’s an open, non-proprietary standard to solve this: NVMe over Fabrics (NVMe-oF), the extension of NVMe to Ethernet and Fibre Channel storage networks. NVMe-oF takes the lightweight NVMe command set and the efficient queueing model, and adds an abstract interface to allow the PCIe transport to be replaced with other transports that provide reliable data movement.
The first transport for NVMe-oF connections to FlashArray will be RDMA, specifically RoCEv2 running over 25G, 50G and 100G Ethernet. We have a lot of experience with NVMe/RoCE — it is the protocol we use between FlashArray//X and the DirectFlash Shelf.
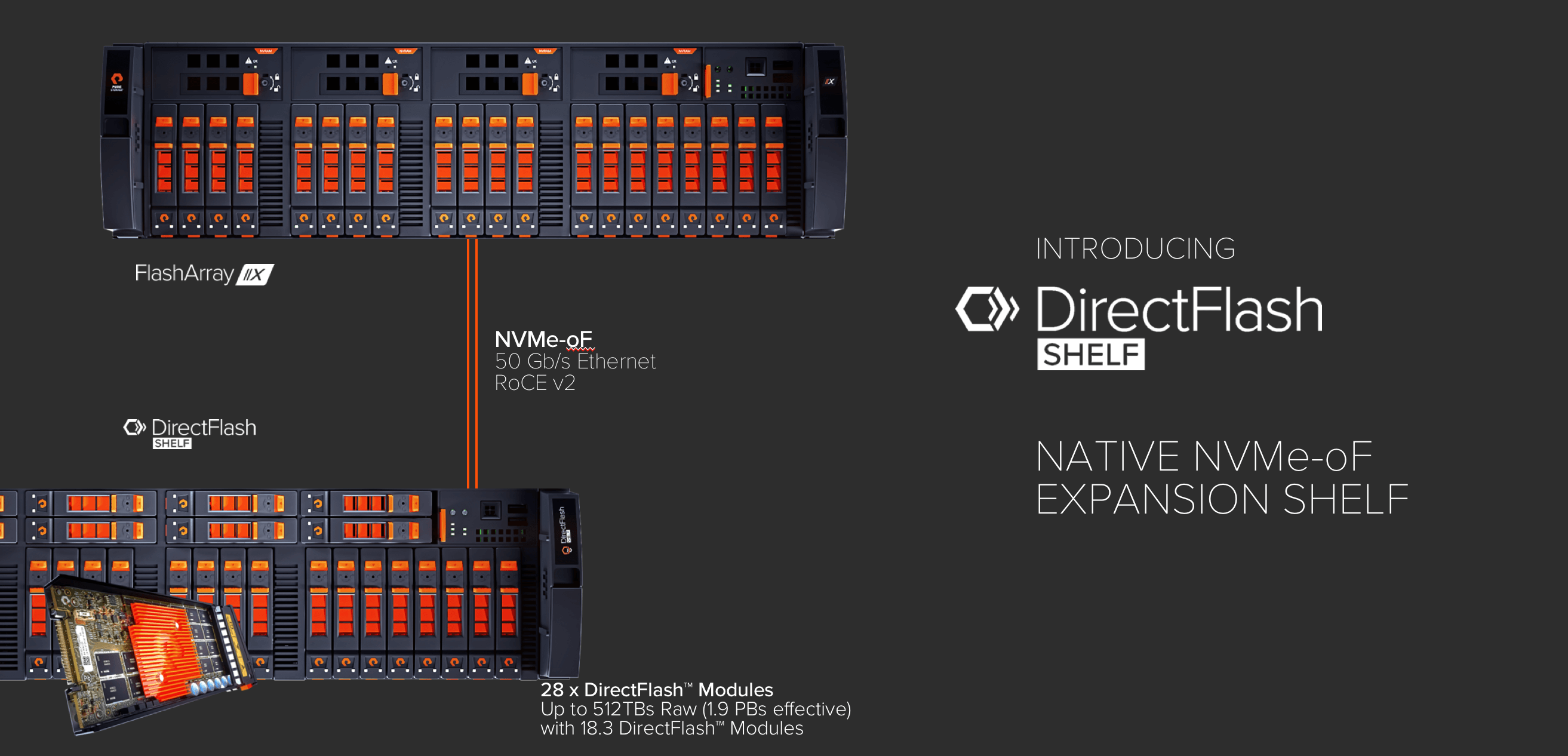
The DirectFlash shelf allows FlashArray//X to grow capacity beyond a single chassis with drives. With our new FlashArray//X90 and a single DirectFlash shelf, assuming 5:1 average data reduction, we can squeeze 3PB of data into 6U. To build the DirectFlash Shelf, we created an extremely efficient implementation of NVMe/RoCE, and this same code is shared with Purity on the FlashArray.
Gartner has identified a convergence of technologies that enable a new architecture for storage, and coined it, “Shared Accelerated Storage”.

We agree: the efficiency of NVMe, running over a converged Ethernet fabric at 25G and beyond, and supported by the performance and rich services of FlashArray//X, will balance the simplicity of DAS with the manageability of shared storage. NVMe-oF RoCE is a key ingredient in enabling data centers built on stateless, elastic compute. NVMe-oF allows external storage to essentially match the latency of direct attached, is significantly more efficient at storage IO processing than iSCSI or HCI, and makes the entire architecture more parallel, avoiding bottlenecks in modern applications.
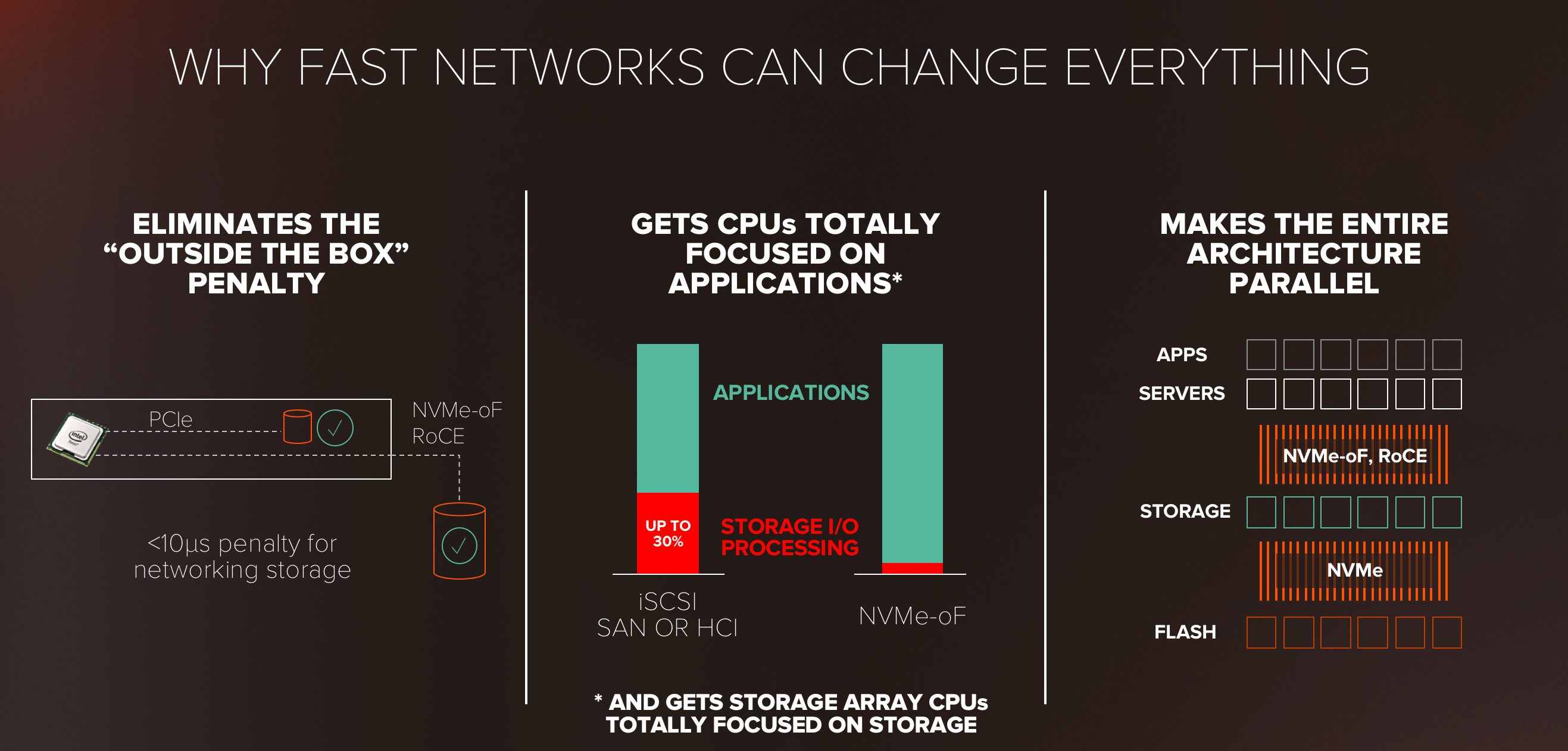
We plan on releasing support in FlashArray//X before the end of 2018. This will open a new set of uses for FlashArray, where shared storage on a converged fabric is appealing, but where the performance of iSCSI on 10G Ethernet won’t cut it.
Of course, Fibre Channel is also an important part of the storage world. “Ethernet people“ have been declaring that “FC is dead” for more than a decade (https://www.networkworld.com/article/2296242/is-fibre-channel-dead-.html is one of the earliest declarations I could find) and they haven’t been right yet. That’s why we continue to advance FlashArray’s FC interfaces — we’re launching 32G FC support with FlashArray//X, and we continue to develop new features for resiliency and manageability. Also recognizing this, the standard includes FC as a transport.
The advantages of NVMe/FC over SCSI-FCP are not as stark as the comparison between NVMe/RoCE and iSCSI, because FC HBAs already offload a lot of the data movement for SCSI-FCP. For example, we already achieve latencies as low as 250us on FC even before NVMe-oF. But the advantages of NVMe in having a lighter stack and offering multiple queues still exist, and we’re excited to unlock those host-side benefits for FC.
Therefore, in a future release we plan to add support for NVMe/FC to FlashArray. The current FlashArray//X hardware is ready for NVMe, and enabling NVMe/FC will just require a Purity software upgrade, which is of course always evergreen – NVMe/FC won’t be a cost-added licensed feature!
At Pure, we caught the wave early. Two generations of FlashArray//M have shipped with NVMe NVRAM modules since way back in 2015, FlashArray//X was the first enterprise all-NVMe AFA in 2017, and this week at Pure//Accelerate, we announced an entire family of FlashArray//X products that will provide goodness and ease of upgradeability for all workloads. We’re excited to continue to drive the storage industry to fully end-to-end arrays!

L