ActiveCluster is part of our strategy to raise the bar for Tier 1 storage, and if you’ve ever tried to set up or use stretch clustering before, we promise you’ve never experienced simplicity like this.
From the earliest days at Pure, reliability has been job #1, and we’ve always strived to not only raise the bar on storage reliability, but we’ve tried to reduce human mistakes by automating as much as we can and simplifying our product, because simplicity drives reliability. We think about reliability in the following hierarchy:

Step #1 is to deliver 6x9s availability, that’s the foundation. We just announced that our FlashArray product has achieved 6x9s availability for 2 years running now, since the first introduction of the FlashArray//M. On top of that base of 6x9s, you then work to eliminate downtime, and that downtime comes in three flavors:
- planned downtime, say time spent doing upgrades or generational migrations
- unplanned downtime, like a site failure or other disaster
- performance variability / failure, when multiple workloads are consolidated and potentially impact one another’s performance
Pure’s already shipped a wide range of reliability features, ranging from NDU-everything, performance through failure and upgrades via our dual-controller design, asynchronous replication for multi-site DR, and always-on QoS to protect against performance variability during consolidation. But there’s been one feature we didn’t have: the ability to synchronously replicate between two sites at metro distances, and this prevented us from serving the most availability-sensitive workloads. Until now.
Synchronous replication was first introduced in 1994 by EMC:

Incidentally, it was their first paid software title, and marked the beginning of the storage business model of paid software features, a business model that Pure’s had a leadership role in abolishing with our Evergreen approach, including all-inclusive software and continuous included innovation.
Several vendors offer synchronous replication and stretch cluster solutions, but if there’s a mainstay of these solutions its cost and complexity.
Implementing traditional stretch clustering is generally a multi-day affair, requires wading through 100s of pages of manuals, can include extra software licenses, gateways, and 3rd-site witness setup, and very often requires vendor professional services…the net: it often costs $100,000+ to successfully implement a traditional stretch cluster.
When Pure started planning our offering in this space, we focused on three areas to innovate:
- Deliver the highest functionality. Typically vendors will start by implementing a simple synchronous replication, and then eventually add support for a true stretched cluster or three data center solution. We decided to aim for the top in our first release, delivering a true active/active stretched cluster, that’s fully-integrated with our asynchronous replication to add a third site. True A/A is not only most reliable, it’s the simplest solution to setup and manage over time.
- Drop-dead simple and fully-integrated. We pushed hard on simplicity throughout – not only making setup a snap, but pioneering the idea of delivering a Pure-hosted Pure1® Cloud Mediator, the first ever SaaS-based replication mediator. And of course, no add-on appliances.
- Free and all-inclusive. Today the use of synchronous replication is limited by the cost, and we believe many more applications could benefit from the additional resiliency it brings…so we included it at no additional cost in our base offering. EVERYONE can use it. If your vendor still charges you for this feature, or requires you to buy an “advanced” software package to get it, it’s time to ask why.
So with this back-drop, let’s dive into Purity ActiveCluster!

We endeavored to make the setup and configuration of ActiveCluster possible without the need to learn a whole new management paradigm. We wanted administrators that manage a FlashArray to simply keep managing the array in the same way they were used to, regardless of whether or not the array is participating in an ActiveCluster. To that end all administrative tasks such as creating volumes, creating snapshots, creating clones, managing asynchronous replication, and managing snapshot offload to NFS and the cloud, is all done the same way regardless of whether or not you are managing volumes on a single array or managing volumes in ActiveCluster. We only introduced one new command, the purepod command, in our management model to enable the configuration of ActiveCluster.
Configuring ActiveCluster can be done in 4 easy steps. 3 of which are the same commands any FlashArray administrator is already familiar with.
Step1: Connect the Two FlashArrays
Connecting two arrays is for ActiveCluster is done in the same way that we have done for asynchronous replication. Why make it different? All we did was introduce a new connection type “Sync Replication” as seen here in this example from the GUI.
Step2: Create and Stretch a Pod
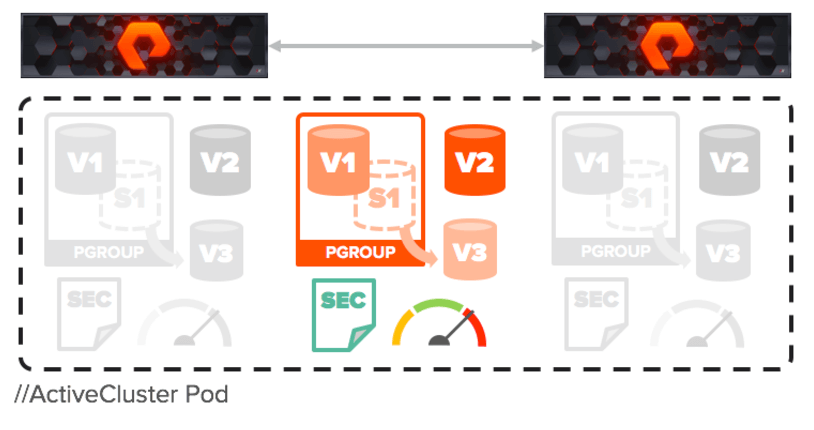
The purepod command is used to create and stretch a pod. What’s a pod? A pod is a management object. Pods enable management simplicity in an active/active environment. A pod defines a set of objects that can synchronously exist on two arrays simultaneously as though there is only one stretched instance of each object. This allows the objects in the pod to be managed as one entity rather than two, but from either array.

Pods can contain volumes, snapshots, clones, protection groups (for snapshot scheduling and asynchronous replication) and other configuration information such as which volumes are connected to which hosts, and performance statistics and security audit log information. The pod acts as a consistency group, ensuring that multiple volumes within the same pod remain write order consistent. Pods are required for ActiveCluster.
Create a pod on arrayA called pod1:
|
1 |
arrayA> purepod create pod1 |
Stretch that pod to arrayB making it a synchronously replicated ActiveCluster pod:
|
1 |
arrayA> purepod add —array arrayB pod1 |
At this point any volumes, protection groups, snapshots or volume clones created in pod1 will be synchronously created on both arrayA and arrayB at the same time. Next create a volume.
Step3: Create a volume
|
1 |
From arrayA or arrayB> purevol create —size 1T pod1::vol1 |
Any FlashArray administrator will notice that this is the same volume creation command they are already familiar with. All we did was prepend the pod name to the volume name and separate them with :: this means that any scripts or REST calls that manage objects on the FlashArray work in the same way, by simply using the full volume name of pod1::vol1. The pod is simply exposed as an addition to the volume name.
Of course you can also move existing volumes into a pod (which is 100% non-disruptive) and then stretch that pod between two FlashArrays. When configuring existing volumes for ActiveCluster, our asynchronous replication technology is used in the background to perform the initial baseline copy of data on between the two arrays. Our asynchronous replication engine is data reduction aware, meaning we maintain compression and data deduplication as we transfer data from arrayA to arrayB.
Step4: Connect Hosts
ActiveCluster is a truly active/active solution at the volume level. Hosts can be connected to and do reads and writes into the same volume on both arrays.
Creating and connecting hosts:
|
1 2 |
> purehost create —preferred–array arrayA —wwnlist WWNs or —iqnlist IQNs hostA > purehost connect —vol pod1::vol1 hostA |
That’s it!!!!! ActiveCluster is up and running and hostA can access pod1::vol1 simultaneously on either array.
Optimizing Performance in Active/Active Environments
Those familiar with creating hosts on a FlashArray may notice the –preferred-array option in the purehost create command above. The preferred array setting is a setting that helps to ensure hosts connected to volumes in stretched pods get the best possible performance.
Most active/active environments are deployed in what is known as a uniform access model. When deployed in this way, a host has access to the same volume through both the local array (the array in the same site) and the remote array (the array in the other site).
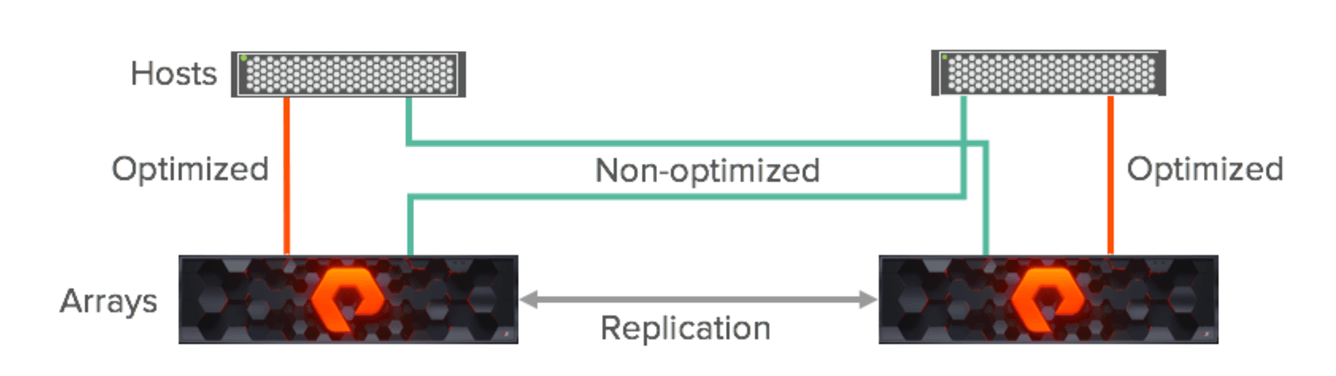
The image above shows the logical paths that exist between the hosts and arrays, and the replication connection between the two arrays in a uniform access model. Because a uniform storage access model allows all hosts, regardless of site location, to access both arrays there will be paths with different latency characteristics. Paths from hosts to the local array (optimized paths) will have lower latency; paths from each local host to the remote array (non-optimized paths) will have higher latency.
ActiveCluster uses the preferred array setting to ensure that hosts have the best possible performance by exposing optimized paths to hosts that prefer that array and non-optimized paths to hosts that do not prefer that array. Hosts will then distribute IOs across optimized paths according to the host’s path selection policy, either round robin (RR) or least queue depth (LQD). The host will not use the non-optimized paths for front-end IO to the array unless the optimized paths are not available. This ensures that writes from the host only pay for one round trip to be synchronously replicated between arrays and that reads are always services by the local path without having to make a trip to the remote site. However, this still allows for the host to simply access data on the non-optimized paths, directly from the remote array, should the local array become unavailable.
Transparent Failover Without User Intervention
The concept of a storage failover does not apply to ActiveCluster in the traditional sense. ActiveCluster is designed to be truly active/active with no notion of volumes being active on one array but passive on the other. Either array can maintain I/O service to synchronously replicated volumes.
Failover occurs within standard host I/O timeouts similar to the way failover occurs between two controllers in one array during non-disruptive hardware or software upgrades.
ActiveCluster is designed to provide maximum availability across symmetric active/active storage arrays while preventing a split brain condition from occurring. Split brain is where two arrays might serve I/O to the same volume, without keeping the data in sync between the two arrays. Split brain is not possible with ActiveCluster.
Any active/active synchronous replication solution designed to provide continuous availability across two different sites requires a component referred to as a witness or voter to mediate failovers while preventing split brain. ActiveCluster includes a simple to use, lightweight, and automatic way for applications to transparently failover, or simply move, between sites in the event of a failure without user intervention: The Pure1 Cloud Mediator.
The Pure1 Cloud Mediator is responsible for ensuring that only one array is allowed to stay active for each pod when there is a loss of communication between the arrays.
The Pure1 Cloud Mediator
Any failover mediator must be located in a 3rd site that is in a separate failure domain from either site where the arrays are located. Each array site must have independent network connectivity to the mediator such that a single network outage does not prevent both arrays from accessing the mediator. A mediator should also be a very lightweight and easy to administer component of the solution. The Pure Storage solution provides this automatically by utilizing an integrated cloud based mediator. The Pure1 Cloud Mediator provides two main functions:
- Prevent a split brain condition from occurring where both arrays are independently allowing access to data without synchronization between arrays.
- Determine which array will continue to service IO to synchronously replicated volumes in the event of a replication link outage.
The Pure1 Cloud Mediator has the following advantages over a typical voter or witness component:
- SaaS operational benefits – As with any SaaS solution the operational maintenance complexity is removed: nothing to install onsite, no hardware or software to maintain, nothing to configure and support for HA, no security patch updates, etc.
- Automatically a 3rd site – The Pure1 Cloud Mediator is inherently in a separate failure domain from either of the two arrays.
- Automatic configuration – Arrays configured for ActiveCluster will automatically connect to and use the Pure1 Cloud Mediator.
- No mis-configuration – With automatic and default configuration there is no risk that the mediator could be incorrectly configured.
- No human intervention – A significant number of issues in active/active synchronous replication solutions, particularly those related to accidental split brain, are related to human error. An automated non-human mediator eliminates operator error from the equation.
- Passive mediation – Continuous access to the mediator is not required for normal operations. The arrays will monitor the availability of the mediator, however if the arrays lose connection to the mediator they will continue to synchronously replicate and serve data as long as the replication link is active.
Failover mediation for ActiveCluster can also be provided using an on-premises mediator distributed as an OVF file and deployed as a VM. Failover behaviors are exactly the same as if using the Pure1 Cloud Mediator, the on-premises mediator simply replaces the role of the Pure1 Cloud Mediator during failover events.
How Transparent Failover Occurs
In the event that the arrays can no longer communicate with each other over the replication interconnect, both arrays will briefly pause I/O and reach out to the mediator to determine which array can stay active for each sync replicated pod. The first array to reach the mediator is allowed to keep its synchronously replicated pods online. The second array to reach the mediator must stop servicing I/O to its synchronously replicated volumes, in order to prevent split brain. The entire operation occurs within standard host I/O timeouts to ensure that applications experience no more than a pause and resume of I/O.
Deployments using a uniform storage access configuration essentially have failover-less maintainance of operations. In the event of an array failure, or a replication link failure causing one array to stop I/O service, the hosts experience only the loss of some storage paths but continue using other paths to the available array. There is no storage failover process for the storage administrator to execute and your workload simply keeps on running.
Purity ActiveCluster – It’s all About Simplicity
Hopefully this post has given you a sense for how deep the concept of simplicity runs in ActiveCluster. We hope this simplicity helps reduce errors, and also encourage those of you who may have been hesitant to upgrade to a stretch cluster to do so. In true Pure fashion – ActiveCluster democratizes metro stretch clustering at the speed of flash for all!
And to all of those out there who continue to pay $100,000s of Dollars / Euros / Pounds / Yen for stretch clustering instances – it’s time to have a conversation with your vendor about a better way!