Welcome to the third blog post in our four-part series, where we take a look at what makes the combination of Portworx® and Pure Storage so awesome. If you’re a virtualization or enterprise storage ninja and getting bombarded with requests or questions from a Kubernetes platform or application architecture team, then this series is for you!
In Part 2: The Helmsman Arrives!, we covered how containerization and Kubernetes came about and how that changed the way your application and developer teams consume infrastructure. In this blog post, we’ll cover how Portworx can provide the operational excellence that your platform consumers are looking for and how enterprise features you’ve been accustomed to providing can be deployed for Kubernetes and modern architectures.
Bringing Proven Enterprise Table Stakes to Kubernetes
We closed Part 2 with a list of some of the challenges that you and the consumers of your infrastructure might face when providing enterprise storage features to Kubernetes infrastructures. I also posed some questions to you on how you might solve some of these challenges—and how you and your consumers might feel if table-stakes enterprise features were unavailable for use. Now, let’s dig in and investigate how the Portworx platform can help you resolve the challenges around bringing enterprise features to application developers and platform admins—and we’ll draw some parallels between VMware and Portworx+Kubernetes to link those neural paths in your brain!
Portworx Portfolio Basics: Your Kubernetes Data Platform Toolbox
The entire Portworx portfolio consists of three distinct products:
- Portworx Enterprise: A cloud-native, software-defined storage solution for Kubernetes
- Portworx Backup: A Kubernetes-aware data protection suite
- Portworx Data Services: A database-platform-as-a-service (DBPaaS) for self-service deployment of common modern data services
Portworx Enterprise
When I run into someone VMware-literate who asks me what Portworx is, I often respond with the answer that the fundamental parallel is that Portworx Enterprise is to Kubernetes, as vSAN is to VMware, but with additional benefits. At its core, Portworx Enterprise takes any backing storage device—an enterprise array LUN, a cloud platform disk like EBS or Azure Disk, or local storage from a hyper-converged server—and creates a storage pool across Kubernetes worker nodes which can then be used to provision persistent volumes for containers.
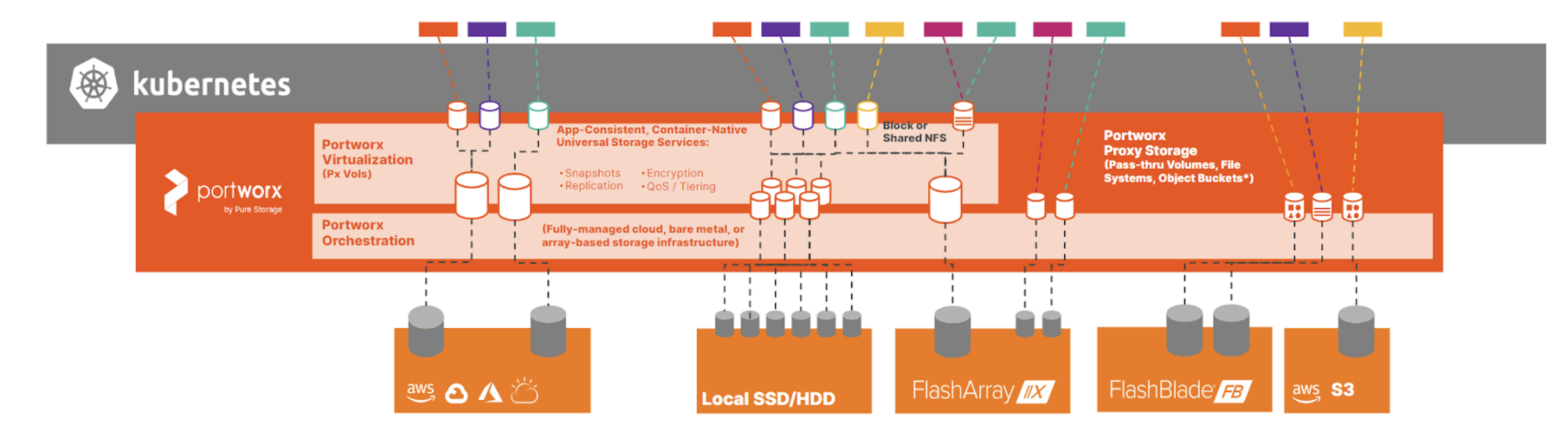
Figure 1
Portworx Enterprise supports two distinct deployment models: disaggregated or hyperconverged. The hyperconverged deployment model you should be familiar with from the early days of vSAN—each node that is contributing storage to the cluster also runs workloads—and if you need to scale nodes in the cluster, each node must contribute storage. The disaggregated deployment model allows you to separate out compute nodes from nodes that contribute storage to the storage cluster—very similar to HCI Mesh or disaggregated vSAN, which was introduced in vSphere 7.0U1. This allows you to scale out or scale up depending on your individual compute and storage needs.
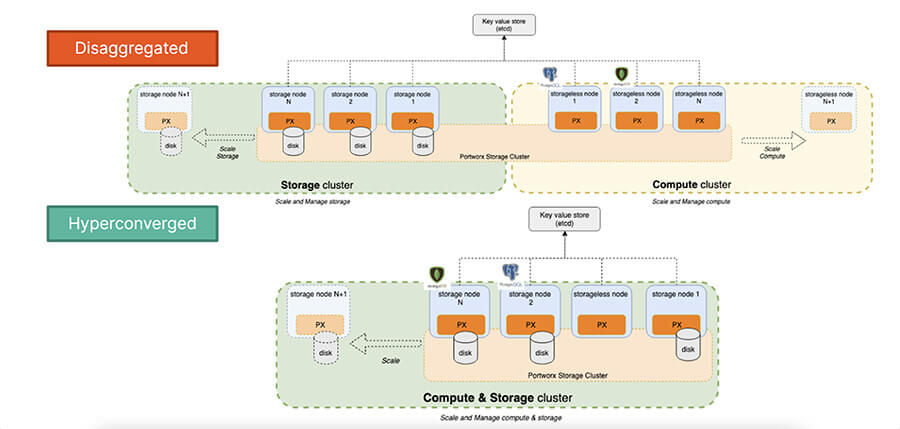
Figure 2
Portworx Backup
Portworx Backup is a Kubernetes-aware data protection solution. It provides the ability to back up not only your persistent volume data but also any Kubernetes objects that are associated with your application. It allows for application-consistent backups of your applications by supporting pre/post rules, provides capabilities for 3-2-1 backup compliance and ransomware protection, enables multi-tenancy using robust RBAC roles, and is available for self-managed installation or in a SaaS version (backup-as-a-service). Just like products such as Veeam brought VMware awareness to data protection, Portworx Backup brings Kubernetes awareness for your data protection needs!
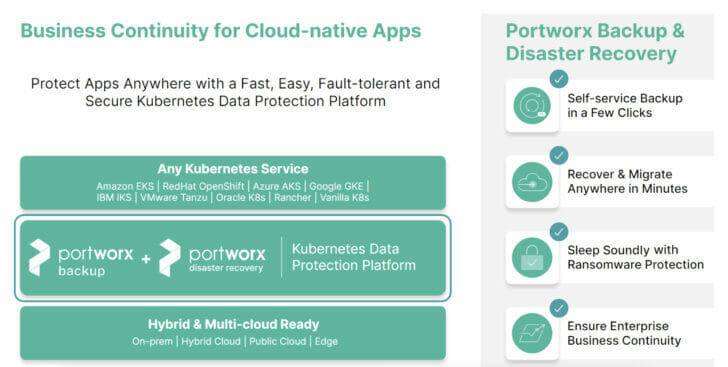
Figure 3
Portworx Data Services
Portworx Data Services (PDS) allows developers to deploy modern data services in minutes, either from our robust UI hosted as a SaaS offering or via API. PDS offers curated database images that are security-hardened, deploys data services with best practices for each service baked in, and allows for managed upgrades of data services—creating a low-touch and low-effort way for developers to get what they really need—an endpoint and authentication information so they can start coding immediately. This is similar to the VMware Marketplace, but instead of being limited to running on vSphere and Tanzu, you can deploy these applications on any Kubernetes cluster, anywhere!
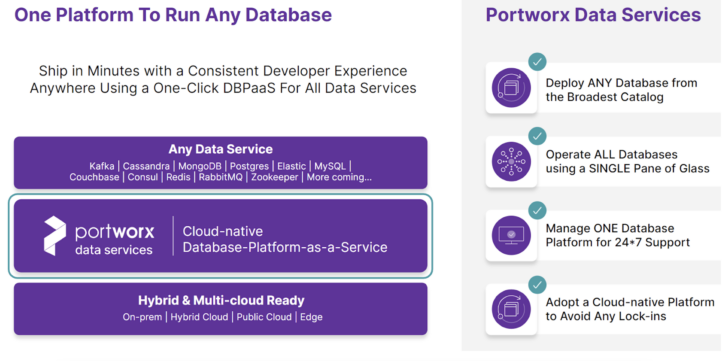
Figure 4
Providing Enterprise Features with the Portworx Platform
Now that you have a basic understanding of the Portworx platform, let’s discuss the enterprise features and benefits it can bring you and your infrastructure consumers, and the challenges those features and benefits can address. At times, we’ll refer back to what we’ve discussed in Part 1 and Part 2, through a VMware lens.
Automated Storage Provisioning – Challenge: Storage Infrastructure
Portworx Enterprise supports dynamic provisioning of backing storage devices to use in its storage pools with our Cloud Drive feature. If you’re running on vSphere, EKS, AKS, GKE, IBM Cloud, OKE, or Pure FlashArray™, Portworx can use API calls to the control plane for those providers to automatically provision backing storage for the Portworx storage pool—no manual disk provisioning needed! This is a great feature to remove friction between the traditional storage admin or cloud practitioner to accelerate provisioning times for a Portworx Enterprise storage cluster.

Figure 5
Storage Pooling and High Availability – Challenges: Storage Infrastructure, Application Availability
Remember in the Application Availability section of Part 2 when I asked you how vSAN could help with storage availability and how vSAN handles node failures? If you answered with something along the lines of vSAN FTT, you were right—we just call it replication factor in Portworx!
As we’ve already covered above, Portworx Enterprise creates one or more storage pools to use in the storage cluster depending on the type and size of disks used in each node. Think of these as similar to vSAN disk groups from a VMware perspective. When Portworx initializes a drive for use in a storage pool, a benchmark is run to classify the performance of the drive, and the drive is then tagged with a low/medium/high identifier based on the IOPS and throughput capabilities of the disk. Portworx supports a maximum of 32 storage pools in a Portworx storage cluster.
We discussed earlier that PersistentVolumes (PVs, or disks for a container) are provisioned from Portworx storage pools when a PersistentVolumeClaim (PVC, or request for a volume) is created—think of this as provisioning a VMDK from a vSAN datastore. Resiliency for the PersistentVolume is determined by the replication factor defined in the StorageClass referenced when requesting the PersistentVolumeClaim (remember those terms from the Developer Agility section in Part 2?)—think of replication factor as the equivalent of Failures to Tolerate (FTT) in a vSAN storage policy. Portworx supports a maximum replication factor of three—the table below shows the equivalence between vSAN FTT and Portworx replication factors.
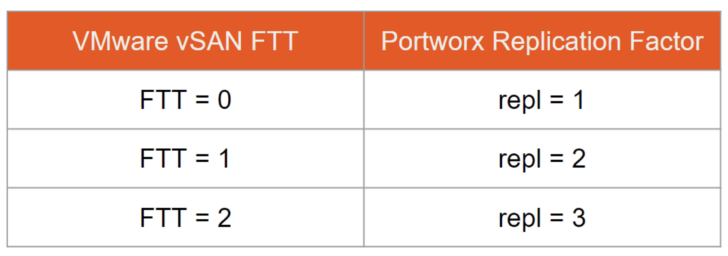
Figure 6
As you can see, a Portworx replication factor of one provides no resiliency against a node failure. If a persistent volume is hosted on a Kubernetes node that fails, there are no surviving replicas to service the container that mounts the volume. A replication factor of three means there are three replicas backing the persistent volume—and the cluster could tolerate the failure of two nodes failing in the cluster before data becomes unavailable to the container using the volume.
Dynamic Capability-based Volume Provisioning – Challenges: Application Availability, Storage Infrastructure, Developer Agility
If you know vVols, then you know about Storage Policy Based Management (SPBM) and understand capability-based volume provisioning. This also means you already understand the basics around StorageClasses in Kubernetes! Within a StorageClass, we define a few items within the StorageClass YAML to define how we tell Kubernetes what type of volume to create:
- Provisioner: This tells Kubernetes what volume plugin to use to provision the volume based on the CSI driver you want to use, such as Portworx.
- ReclaimPolicy: You should see this set to either Retain or Delete in a StorageClass. Retain means that the underlying PersistentVolume (disk, or PV) is retained when the PersistentVolumeClaim used to create the PV is deleted. If set to Delete, the underlying PV is deleted when the PVC used to create the PV is deleted.
- VolumeBindingMode: You should see this set to either Immediate or WaitForFirstConsumer in a StorageClass. Immediate indicates that the PV should be immediately provisioned once the PVC is created, regardless of if a pod is ready to use the volume or not. WaitForFirstConsumer indicates that Kubernetes will wait to provision the PV until it receives a request from a pod that references the PVC.
- AllowVolumeExpansion: This can be set as a boolean to either True or False if the volume plugin (CSI driver) supports expansion of the PV.
- Parameters: This is where the goodness comes in for defining the capabilities of the volume plugin (CSI driver) being used. For example, we can set repl parameters here for Portworx, which will define how many replicas of the resultant PV will be created once the PVC is created. You can see the full list of parameters and associated capabilities supported by Portworx here.
As you can see from the descriptions above, dynamic provisioning of PVs in Kubernetes is very similar to SPBM in VMware. Below is a simple example comparing the dynamic PV provisioning process compared to ordering food in a restaurant:
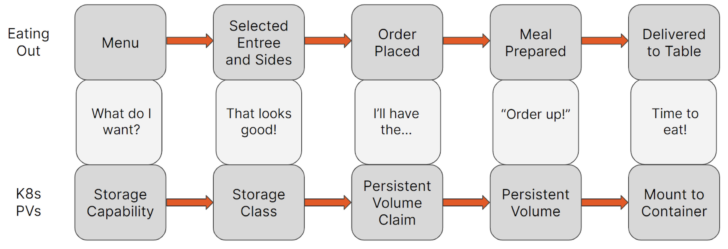
Figure 7
Defining StorageClass parameters allows you to pre-configure the types of volumes that developers can dynamically provision for their applications that require persistent storage. You might recall me asking in the Developer Agility section of Part 2 if you were able to easily provide developers with the ability to provision specific storage capabilities by themselves before SPBM—now you know why I asked and how we can improve the developer experience and improve their agility and efficiency!
Intelligent Placement and Data Locality – Challenges: Developer Agility, Application Availability, Performance
While vSAN provides data locality, sometimes more granular and intelligent placement of a volume within the storage cluster is needed. Storage Orchestration Runtime for Kubernetes (STORK) implements a Kubernetes scheduler extender to ensure data locality and storage health monitoring via filter requests, prioritize requests, and error condition handling. Let’s take a look at each of these.
Filter Requests
A filter request filters out nodes that do not have the storage driver running or that may be in an error state. Kubernetes does not have this information natively—and without STORK, may try to schedule a pod where storage is unavailable—leading to failed scheduling and increased time to attach a volume.
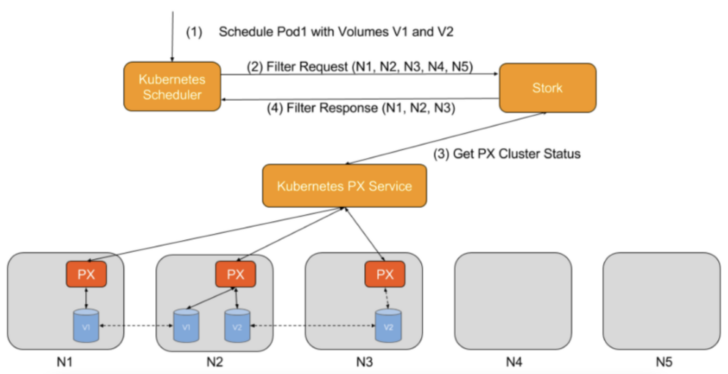
Figure 8
Prioritize Requests
A prioritize request checks which PVCs are going to be in use by the pod, then queries the storage driver to determine the best node placement for the pod. To accomplish this, a weighted ranking is performed across all nodes identified during the filter request, and then the best node is passed to the Kubernetes scheduler.
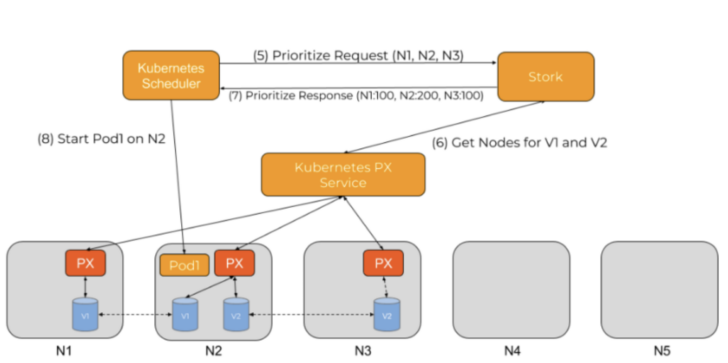
Figure 9
Error Condition Handling
STORK monitors storage health by checking with the storage driver to see if Portworx is healthy on all nodes. If a node is unhealthy or goes down unexpectedly and a pod needs to be rescheduled, a reschedule request is sent to the Kubernetes scheduler to identify a node where the pod’s storage is available so that the pod may come back online.
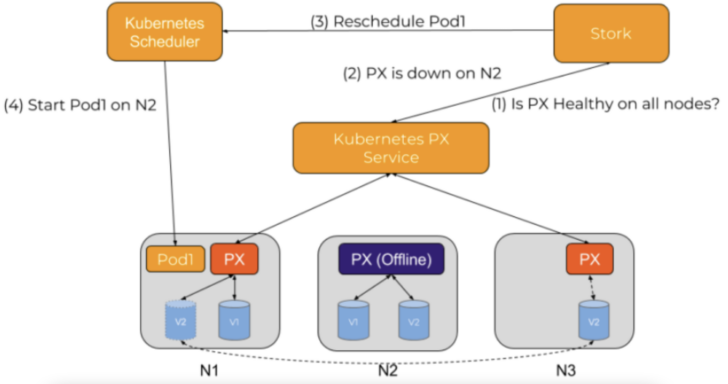
Figure 10
Volume Placement Strategies
Now that we’ve covered STORK and how it extends the native Kubernetes scheduler to be storage-aware, let’s discuss another great feature within Portworx Enterprise that allows granular placement of volumes—Volume Placement Strategies (VPS).
VPS allows you to force data locality for volumes that need to be co-resident with their respective pods using affinity rules. It can also force volume separation in order to ensure volumes are running on separate failure domains, or running on separate hosts to ensure different I/O profiles for specific volumes are not conflicting. VPS uses four distinct rule types in conjunction with labels in Kubernetes to intelligently place volumes across nodes, racks, or availability zones (AZs) in the Portworx storage cluster: replicaAffinity, replicaAntiAffinity, volumeAffinity, and volumeAntiAffinity.
As you can see, Portworx allows for a much more granular and controlled placement of volumes in your Kubernetes cluster than the automated placement available in VMware vSAN. This is due to the fact that Kubernetes clusters allow for granular definition of topology for nodes that comprise a Kubernetes cluster, so you have much more flexibility to meet failure domain requirements based upon the topology of your cluster.
Automated Capacity Management and Thin Provisioning – Challenges: Capacity Management, Application Availability
You might remember in the Capacity Management section of Part 2 when I asked if it would be useful if you had the capability to set policies on VMDKs in VMware to automatically grow a VMDK and expand the underlying filesystem as a function of VMFS or vSAN datastores. Well, in Kubernetes with Portworx Enterprise and Autopilot, you can do this for your developers and platform infrastructure consumers!
VMware has long allowed thin provisioning of disks to ensure that you’re only consuming the amount of space on a datastore equal to the space consumed by the actual data written to the VMDK. Portworx enables thin provisioning for Kubernetes persistent storage, allowing for the same type of overcommit of storage that VMware does.
But sometimes thin provisioning is not enough. How many times have you been woken up from a monitoring system, or contacted by an application owner stating their virtual machine is down and the application is not functioning, only to find out a critical virtual machine has run out of disk space?
Portworx Autopilot is a rule-based engine that allows you to perform actions based on monitoring metrics, for example, resizing a PV in use by a pod when it reaches a certain threshold. The real beauty about a scenario like this in Kubernetes when using Portworx is that this can all be done automatically without taking the application down—including resizing of the underlying XFS or EXT4 filesystem within the container! This ensures that you can right-size your PVs and not over-provision them and only have to consume and pay for the amount of storage that you need.
Application and Volume Migration – Challenge: Data and Application Portability
VMware vMotion, Storage vMotion, and OVFs gave us the capability to easily move virtual machines and their associated VMDKs between clusters due to the abstraction layer that VMFS provides. We discussed the challenge of portability in Part 2 and the fact that unless you have a consistent storage layer across multiple Kubernetes clusters, this can be a multi-step and onerous process.
With Portworx Enterprise in conjunction with STORK, migrating stateful applications and their data is a breeze! These migration capabilities allow you to do things like lift/shift migrations, blue-green testing commonly used by modern application teams, or promoting an entire application from dev to QA without having to redeploy the entire application and restore data from a backup.
Security and Encryption – Challenge: Security, Encryption, and RBAC
As we discussed in the Security, Encryption, and RBAC section in Part 2, having the capability to extend security concepts from Kubernetes to the storage layer gives us the benefit of enabling secure multi-tenant access to storage within a Kubernetes cluster.
Providing different access levels based on a “need-to-know” or “need-to-use” basis is necessary even for storage operations, and enables multi-tenancy. Portworx enables security on a storage cluster using JSON Web Tokens (JWT) to provide granular access control using RBAC roles.
Once security is enabled on a Portworx storage cluster, you can encrypt volumes individually using a cluster-wide secret, or you can provide a per-volume secret for even finer-grained encryption. Portworx encrypts volumes with AES-256 ciphers, utilizing the dm-crypt kernel module and libgcrypt library.
Remember in the Security, Encryption, and RBAC section of Part 2 when I asked you if you would feel comfortable if every tenant in your private VMware cloud had unencrypted access to another tenant’s VMDKs? When running Portworx on Kubernetes, you don’t have to worry about multi-tenant storage security issues!
Controlling IOPS and Throughput – Challenges: Performance, Resource Utilization
Kubernetes allows you to control CPU and memory noisy neighbor situations using resource limits and requests, similar to how you control resource utilization in VMware by assigning specific vCPU and memory allocations. However, since storage is treated separately in Kubernetes, there are no native primitives available to control IOPS and throughput at the storage layer.
Portworx Application I/O Control gives you the capability to throttle storage IOPS and bandwidth for PVs, similar to Storage I/O Control (SIOC) in VMware environments. This prevents noisy neighbor situations and ensures that you can have predictable performance for all containers that may be sharing a single host or storage pool with regard to IOPS and throughput of the underlying storage. Definitions for IOPS and throughput can be configured at the StorageClass layer, or on a per-volume basis for even more granularity and control.
Maximizing Storage Performance – Challenge: Performance
Again, you might recall in the Performance section of Part 2, I asked if you would couple highly performant CPU and memory with low-performance storage for applications that require high performance in a VMware environment. For the sake of the consumers that utilize your infrastructure, I hope you said no!
Portworx provides the best cloud-native storage performance across all I/O profiles to ensure that you can provide the required performance to any workload that requires persistent storage in Kubernetes. In addition, we have a feature called PX-Fast which allows you to achieve near bare metal performance when using NVMe drives.
PX-Fast reduces the transitions from kernel space to user space to the bare minimum, ensuring maximum performance and utilization of your high-performance NVMe disks. Think of the performance gains you saw when going from VMDKs to vVols in VMware, and you’ll have an idea of how great this can be for performance-hungry applications!
Control Plane Footprint – Challenge: Resource Utilization
We spoke about the importance of control plane footprint in the Resource Utilization section of Part 2, and I asked you to imagine what workload impacts would be if ESXi CPU and memory increased exponentially with the number of virtual machines you deployed onto it. You wouldn’t be very happy, nor would your management—this defeats the purpose of consolidated workloads that VMware and Kubernetes give us!
Portworx has a consistent footprint for its control plane, regardless of the number of volumes provisioned within your Kubernetes cluster. This means you get predictable capacity for your workloads that matter—your applications. Other cloud-native storage solutions experience severe bloat of control plane resources as the number of volumes provisioned and managed increase—leaving less capacity to run your business applications.
Data Protection and Offsite Backups – Challenge: Data Protection
We spoke about using the right tool for the job for data protection of VMware environments and reminisced on taking tapes to the local bank safe deposit box in Parts 1 and 2 of this blog series. We discussed the importance of ensuring your data protection solution “speaks the language” of the infrastructure you’re needing to protect. You don’t use bare metal solutions for virtualized environments, and you shouldn’t use virtualization solutions for Kubernetes environments.
Portworx Backup provides a data protection solution that allows you to back up and restore Kubernetes applications and their persistent data on any Kubernetes cluster running on any platform! Features like namespace awareness, 3-2-1 backup compliance, ransomware protection through immutable backups, backup sharing, and a comprehensive set of RBAC roles give you the type of features you’ve become accustomed to in VMware environments.
Asynchronous Replication – Challenges: Disaster Recovery, Application Availability
These last two features are a couple of my favorites to discuss with customers, and I think you’ll see major value here too. Like VMware Site Recovery Manager (SRM), Portworx Async DR allows you to provide application and storage replication between any site on the globe.
For example, you may need to replicate your Kubernetes applications between data centers on different continents or public clouds in different regions. Async DR gives you the capability to provide an RPO as low as 15 minutes, providing applications with resiliency to failure needed to meet low-RPO requirements.
With Async DR, each site hosts a single Kubernetes cluster with dedicated and distinct Portworx storage clusters installed on each.
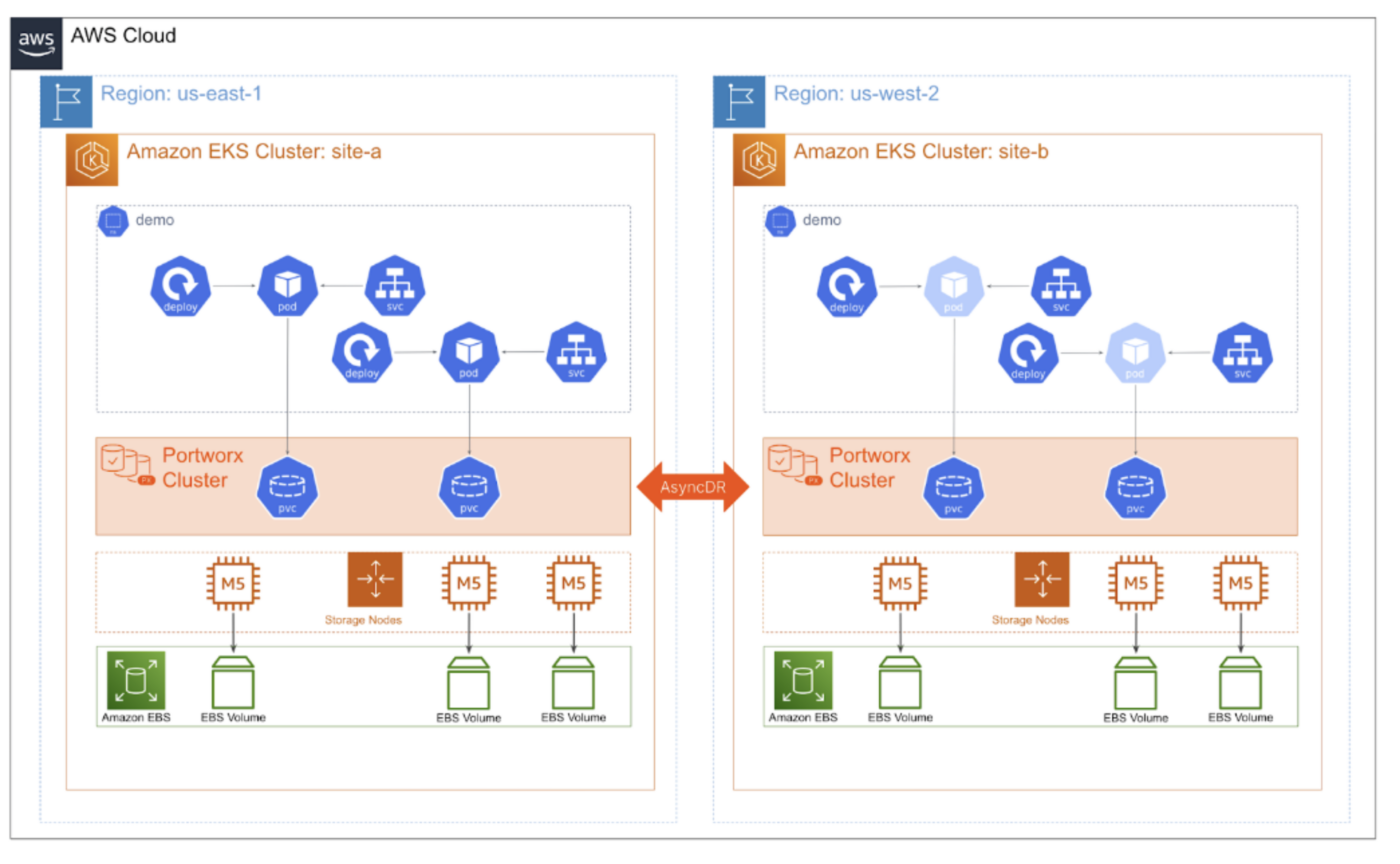
Figure 11
Synchronous Replication – Challenges: Disaster Recovery, Application Availability
In the Disaster Recovery section of Part 2, we spoke about true disaster recovery not being possible unless you control the storage layer and how zero RPO solutions were impossible across disparate platforms running Kubernetes without a consistent storage layer. Portworx Sync DR gives you similar functionality that VMware Metro Storage Cluster (VMSC) provides in VMware, allowing you to protect your Kubernetes applications between metropolitan data centers or availability zones within a region in the public cloud.
Sync DR gives you the ability to provide a zero RPO solution to your platform and application teams running Kubernetes applications. You can even combine Sync DR with an Async DR leg and create ultra-resilient 3DC configurations for maximum availability! You can use Sync DR for your absolute mission-critical applications, where your application can’t afford to miss a single transaction.
Sync DR has similar requirements as VMSC in that the two connected sites have no more than 10ms of network latency between them. It requires a dedicated Kubernetes cluster at each site just like Async DR, but instead of separate Portworx storage clusters, we configure Portworx as a stretched storage cluster that spans both Kubernetes clusters.
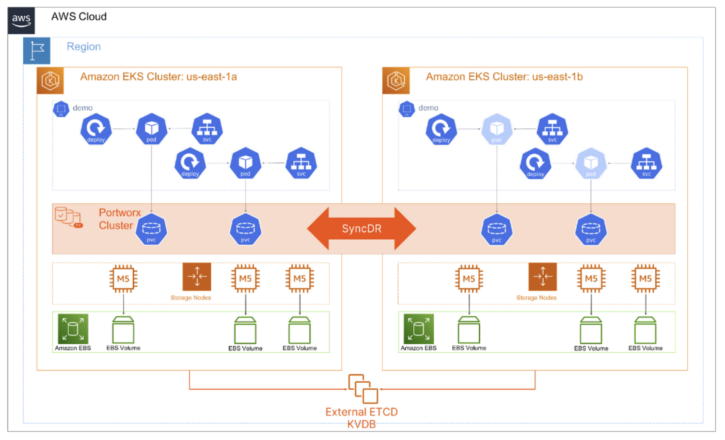
Figure 12
To summarize, let’s take a quick look at all of this information in a table to see how common features and benefits map from VMware infrastructure to Portworx and Kubernetes:
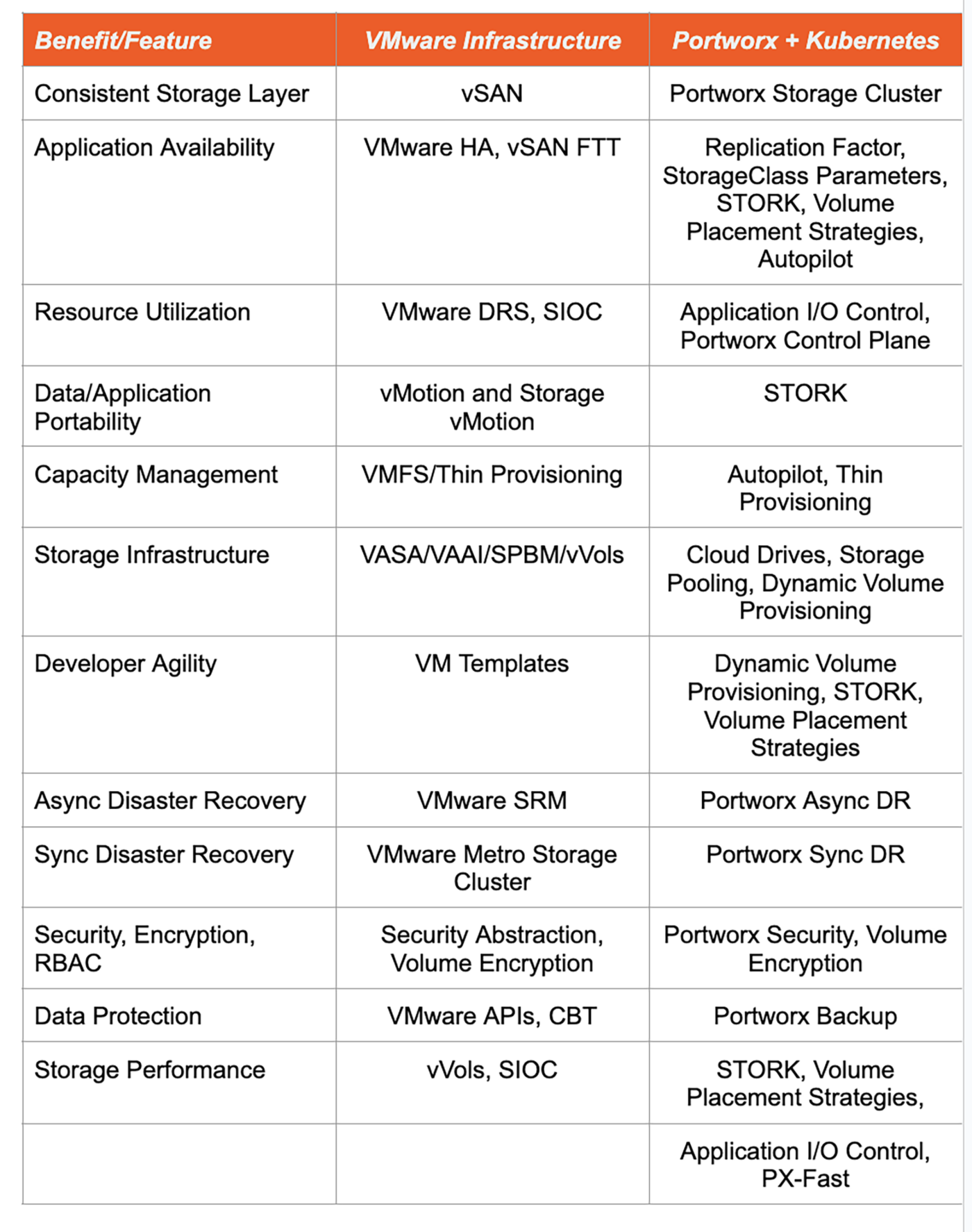
Figure 13
What’s Next?
That was a lot of information to consume and link the parallels in your mind! We’ve covered several of the enterprise features in VMware environments and how Portworx can bring many of the same benefits in a Kubernetes environment—I hope your neurons are firing!
Be sure to check out Part 1, where we went through an overview of all of the goodness that virtualization and enterprise storage has given us over the years and covered all of the operational excellence that you’ve been able to provide to the consumers in your organization.
And stay tuned for Part 4, where we’ll wrap up and discuss how Portworx+Pure can be an absolute game-changer for you and your organization. We’ll talk about how the combination of Portworx and Pure Storage can bring simplicity and delight to your organization. It shouldn’t matter whether you need infrastructure for virtualized or containerized applications—or if you need to run on premises, in the public cloud, or in hybrid or multi-cloud architectures—operational excellence should be available for it all!

Written By: