In our introductory blog yesterday, we talked about how the cloud era of applications is demanding an evolution to the all-flash array recipe, and we set-out a new vision for how to construct an AFA for the future. We shipped our first cloud-era AFA last year, FlashBlade™, and it’s fundamentally changing what is possible for accelerating big data (think modern analytics, software development, scientific computing, and large-scale file and object stores). Today – we’re completing the picture by announcing FlashArray//X – the first mainstream all-NVMe FlashArray. In this 5-part blog series – we’ll tell you everything you need to know about the future of flash for the cloud era:
- Part 1: A New Flash Recipe for the Cloud Era
- Part 2: FlashArray//X – Making NVMe Mainstream [this blog]
- Part 3: DirectFlash™ – Enabling Software and Flash to Speak Directly
- Part 4: Transforming to NVMe the Evergreen Way
- Part 5: A Customer’s Perspective – How MacStadium Uses NVMe
We’ve Seen This Movie Before
The year was 2009. Flash had already transformed your iPhone, yet your storage array still looked like a ton of bricks. Flash companies started to explode into the enterprise scene – Violin, FusionIO, Texas Memory Systems, etc. Flash was 10X faster, 10X denser, and unfortunately 10x more expensive…so each of these companies made the ‘race car’ of storage – a super-fast, super-expensive, and less-than-reliable but “revolutionary” flash storage device. Meanwhile – legacy storage vendors looked at flash and couldn’t see how disruptive it would be, first dismissing it and then merely adding it as a tier or cache.
By now you know how this story goes – Pure’s founders realized everyone had failed to recognize the mainstream potential for flash and founded Pure – coupling flash with purpose-built software for efficiency and reliability to create the all-flash array. This recipe has been often imitated (though never replicated!), and has lead to a transformation of the storage industry that frankly surprised even us. The key to this recipe was purpose-built innovation and mainstream thinking – do the software engineering to make the most of flash and make adoption simple – thus re-igniting the storage market.
So fast-forward to today, and we see the same movie playing itself out all over again. This time the technology break-through is NVMe, a new protocol for communicating with flash that provides the low-latency and parallelism that promises to take the potential of flash to new heights. The problem, in the words of a major storage incumbent, is that NVMe-based storage is “expensive, exotic, and unnecessary”. And once again, we see two camps: a set of new startups who are building purpose-built NVMe flash solutions that are expensive, high on performance and low (or non-existent) on software…the ‘race car’ recipe again. And we see legacy storage vendors who once again are trying to use NVMe as a cache, talk about it as niche, delay its adoption, all while they try to figure out how to retrofit it or buy into it. There’s no better example of this failed recipe than EMC’s saga with DSSD, an all-NVMe storage appliance that was all performance and no features, and carried a 10X effective price point over all-flash arrays. EMC just two weeks ago killed the product due to lack of market demand for such a niche strategy, and decided to retrofit the technology to their other products.
Well, Pure has executed a different plan:
- We’ve taken NVMe and purpose-built our AFA to make the most of it;
- We’ve done so in a way that doesn’t leave the software behind, enabling true enterprise-class resiliency and features;
- We’ve co-innovated in software and hardware, enabling new levels of performance and efficiency;
- We’ve made NVMe mainstream and affordable, enabling every customer to take advantage of NVMe for their performance-sensitive workloads and enable a new class of cloud-era workloads;
- And we’ve done it all in an EvergreenTM fashion, enabling our current FlashArray customers to simply upgrade and take advantage of NVMe.
And…we’ve DONE IT TODAY.
Introducing FlashArray//X – The First Mainstream 100% NVMe All-Flash Array

Welcome to the next generation of FlashArray – FlashArray//X.
When we first set out to design the FlashArray//M, Pure’s flagship product, we knew the transition to NVMe was coming – so we enabled it right in from the beginning. The FlashArray chassis was built to accommodate both SAS and PCIe/NVMe connectivity throughout the mid-plane from day 1, and the FlashArray has been using NVMe to communicate to our dual-ported custom-designed NV-RAM devices from day 1 – before the NVMe specification was even finalized!
Last year, we issued the industry’s first NVMe guarantee – and we promised every FlashArray customer a non-disruptive upgrade path to NVMe from the SAS systems they purchased…today we reveal how we are delivering on that promise.
So this is pretty simple – just get some NVMe drives, add them to the system, and we’re done…right? Not even close. Mainstream NVMe adoption has two significant challenges today:
- NVMe SSDs are expensive. Today, dual-ported NVMe SSDs carry about a 2X premium over their dual-ported SAS counterparts (which are themselves much more expensive than the consumer SATA flash that Pure uses). One major vendor has said that its mainstream adoption is “a couple of years away” due to prices. If we want mainstream adoption, we’ve got to solve the price barrier. (And let’s remember – we’re in the middle of a flash supply shortage – meaning that high-end enterprise NVMe SSDs aren’t going to be in the discount bin anytime soon).
- NVMe’s parallelism requires different software to get the advantage. You can’t simply just plug NVMe drives in a legacy disk array OR even an all-flash array and expect magic to happen.
To exploit the potential benefits of NVMe – you’ve got to innovate end-to-end from software to flash.

So today we’re announcing not one, but three new pieces of technology:
- FlashArray//X70 Controllers: a new controller that speaks NVMe natively into the FlashArray chassis’ midplane;
- DirectFlashTM Module: the world’s first software-defined flash module – a new Pure-designed NVMe flash module which delivers affordable NVMe flash via an innovative architecture that enables our system-level software to speak directly to flash;
- DirectFlash Software: the software brains of the DirectFlash architecture, a new software module within the Purity Operating Environment that takes the software functions that would normally run inside each SSD (flash management, wear leveling, garbage collection) and implements them once in a global software layer for better efficiency, performance, and reliability, and ensures that the system software doesn’t work at odds with the SSD software.
While the NVMe protocol is important, it’s just a small part of the innovation we are delivering with DirectFlash – our software is what truly makes DirectFlash special. And while DirectFlash is new to FlashArray, it’s not new to Pure. We first implemented the DirectFlash architecture last year in FlashBlade, and we now bring to FlashArray. DirectFlash is totally different from what anyone else in the industry is doing – and it’s core to what makes FlashArray//X possible. Read more about how your AFA likely still has a ton of disk technology inside it, why we built DirectFlash, and how it works in Part 3 of this blog series.
In addition to these three new technologies, there are two other critical capabilities of //X that are important to understand:
- //X is Evergreen. Just like everything at Pure – it was important to us to implement NVMe in a way that not only everyone could afford, but everyone could adopt now or in the future. //X is an Evergreen upgrade from FlashArray//M, and upgrade scenarios will let customers choose whether they want to consolidate to 100% NVMe flash, or just add NVMe flash to their existing systems. This is such an important concept that we dedicated Part 4 of this blog series to explain it in detail, as well as how all of our Evergreen programs work with FlashArray//X.
- //X is NVMeF-Ready. The first step is to make NVMe flash accessible to all, with the logical next step being to speed its connectivity to hosts with NVMeF over fast RDMA Ethernet or Fibre Channel. The NVMe spec is about 4 years old now, but the NVMeF spec is just a few months old. We’re working hard with industry partners to get NVMeF ready for mainstream in //X, and we expect to make it available as a simple IO card addition early in 2018 (or sooner for our beta customers and partners). Want to see NVMeF in action on //X? Come visit us at Pure//Accelerate in San Francisco in June!
We Don’t Leave the Software Behind
From the first day of Pure’s existence, we’ve been a software-first mindset company, and when we went to the drawing-board to create //X, it was never a question to us that it should be powered by Purity. //X runs the exact same Purity Operating Environment software that Pure customers have known since day 1, with it’s capabilities now extended for NVMe with the DirectFlash Software inside.
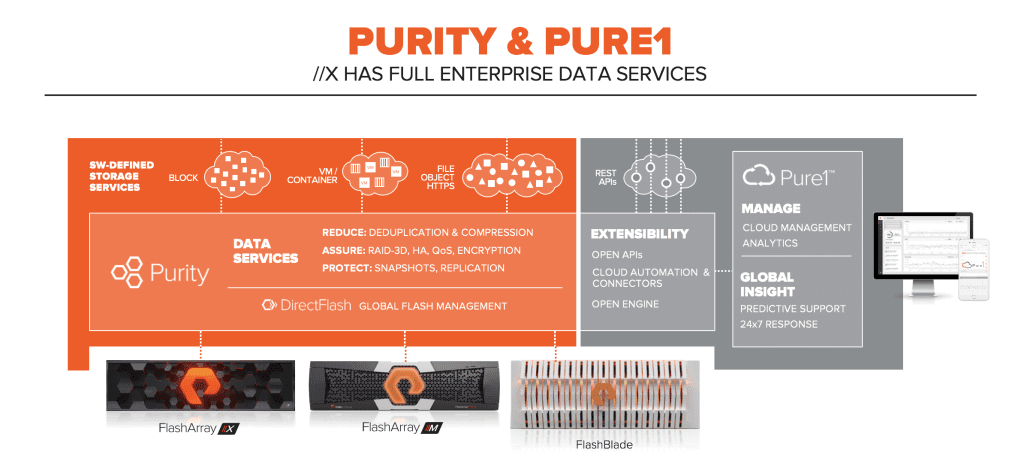
This means that customers will enjoy the same deduplication and compression in Purity//Reduce, the RAID-HA, HA, QoS, and encryption features in Purity//Assure, and the snapshot and replication capabilities of Purity//Protect in FlashArray//X. //X is also managed by Pure1®, the same cloud-based management and support technology, which re-defines simplicity in management and leverages advanced analytics and machine learning technologies to deliver predictive support (which, thanks to DirectFlash, can now be extended down to the flash block level inside the DirectFlash Module).
So How Fast is //X?
Put simply, FlashArray//X unlocks the performance necessary for us to drive the next decade of performance advancement in FlashArray. FlashArray//X is faster in three dimensions: lower latency, higher bandwidth, and higher performance density.

Before we talk performance – I’d like to explain the “performance marketing” philosophy at Pure Storage. In the flash industry we’ve grown tired of typical vendor shenanigans of picking idealized and unrealistic block sizes (512-byte or 4K), and running “hero” benchmarks that show their devices capable of Millions of IOPs and latency “as low as” 100 µs. These ‘benchmarketing’ attempts typically turn off the advanced data services (like data reduction, snapshots and replication), ignore array fullness and failure scenarios, and forget the fact that all IO is mixed in block size, mixed in read/write, and NOT ideal. This is what caused us, three years ago, to stop publishing 4K benchmarks, and move to a 32K average IO size in our marketing.
So as tempting as it might be – we’re not going to tell you that you should buy FlashArray//X because it can do Millions of IOPs. Instead, we’ve done a wide variety of testing both in our labs and with our //X beta customers that tries as best we can to simulate real-world mixed IO size environments that most closely match the “average” customer environment we see from our call-home data (but of course – “average” is meaningless – because the only person who has an IO profile like you is you). We arm our field teams with a detailed performance database and they can give you the best estimates of //X performance for your specific application environment.
What we see, generically, across this range of literally 1,000s of tests, is that //X is:
- Up to 50% lower latency than //M for similar workloads in real-world scenarios. Imagine every database transaction your applications do coming back 50% faster? Latency is the most important dimension of the //X advantage.
- Up to 2X higher bandwidth than //M for similar workloads in real-world scenarios. Especially if your application is heavily write-focused, //X delivers more data throughput.
- Up to 4X better performance density than //M. One of the untold secrets of the AFA industry is that big SSDs are slower per-TB. (If your vendor offers 15.3 TB SSDs, for example, ask them the performance difference between deploying 15TB SSDs vs. 15x1TB SSDs instead. The answer may surprise you.). In fact in FlashArray//M, we deploy two SSDs in each Flash Module to reduce the impact of this very performance bottleneck, and so if you want the maximum performance, you typically need to deploy at least 44 Flash Modules (88 SSDs) into the system to get enough parallelism. With FlashArray//X, the maximum performance can be achieved with just 10 DirectFlash modules. Said differently – DirectFlash unlocks ultra-dense flash module usage with no performance penalty.

As exciting as benchmarks are – nothing speaks to performance results like real customers. In Part 5 of this blog series – I’d invite you to hear from Jason Michaud at MacStadium who shares his experiences with FlashArray//M and //X as he delivers IaaS and hosting services to software developers globally.
So How Big is //X?
Err…well it’s big. Yet small. Or small but big on the inside. You get the point. With the new 18.3 TB DirectFlash Modules, //X scales to 1PB effective capacity in just 3U. This assumes average 5-to-1 data reduction rate that is typical across our install base. See our live data reduction ticker here. Note that our data reduction rates don’t include efficiency technologies like thin provisioning. If we did, our average would be 11:1 (be sure to ask your vendor what they are including in their data reduction rates). Customers using snapshots gain even greater space efficiencies.
This performance density, coupled with our Evergreen model, is all about taking advantage of the fast rate of improvement of flash, which just isn’t stopping:

Just look at how buying a PB of flash from Pure has gone from six racks to just 3U in the span of only five years. And //X’s big-but-small nature enables some pretty exciting new use cases:

//X’s performance density enables it to be deployed in really small variants for single-application acceleration. The smallest //X has just 22TB of raw flash, yet can deliver the maximum performance, for say making SAP or Oracle scream. Looking for an Exadata alternative?
Our web-scale cloud and SaaS customers have been particularly excited about “top of rack” //X deployments. Most large cloud environments have racks and racks of servers, each with a DAS flash or disk deployment inside each server. What if, using //X plus fast Ethernet (iSCSI today, NVMeF tomorrow) you could deploy a 3U ToR //X deployment and get all the advantages of shared storage for your DAS application? Similar performance, with better economics, reliability, scale, and serviceability. And finally – //X is an amazing consolidation platform. If you think about your storage density in rack terms – a full rack of //X can deliver up to 15 PBs of effective flash capacity and over 100 GB/s of bandwidth.
Is //M Going Away?
Of course not. FlashArray//X represents a new higher-performance offering in the FlashArray family, but //M will continue to be both sold and innovated.
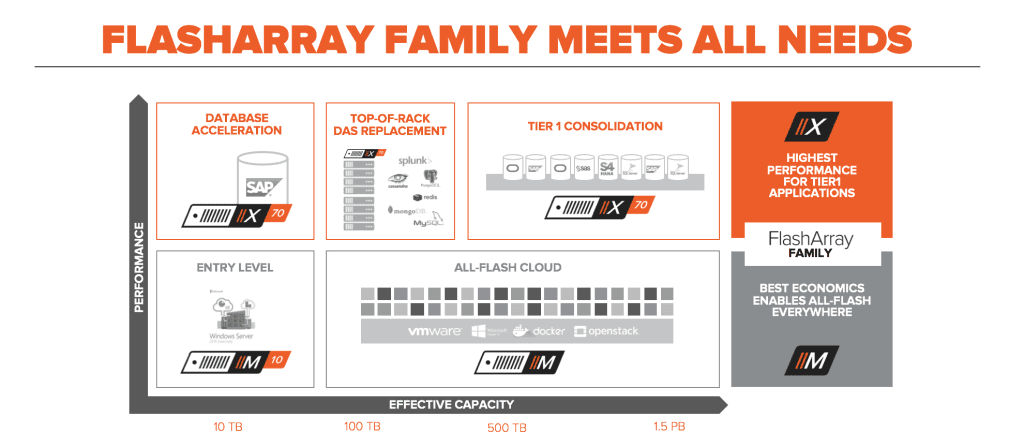
This enables the FlashArray family to meet a wide variety of block storage needs in the data center. //M10 enables point flash deployments, //M20-//M70 are ideal for the most economic all-flash consolidation, and //X now represents a higher-performance tier for mission-critical databases, top of rack flash deployments, and Tier 1 application consolidation. And of course, with our Evergreen model, you can start anywhere in this picture and upgrade non-disruptively to expand capacity or performance elastically without downtime or wasted investment. We cover this topic in much more depth in Part 4 of this blog series on our Evergreen advantage.
Using //X as the Foundation of Your Cloud
Let’s finish by popping-up a level. Together, FlashArray//X and FlashBlade offer a complete solution to meet the needs of cloud-era applications, with FlashBlade optimized for the highest capacity and scale workloads, and //X optimized for the lowest-latency workloads:

It’s an exciting time to be a storage vendor, as this new cloud era is forcing us to expand our definition of storage workloads and use cases. We’ve long used the “pyramid” to describe the wide range of structure (block) and unstructured (file & object) use cases in the storage market, but the cloud era is expanding the scale and performance needs of the market as we prepare for cloud era file, block, and object stores:
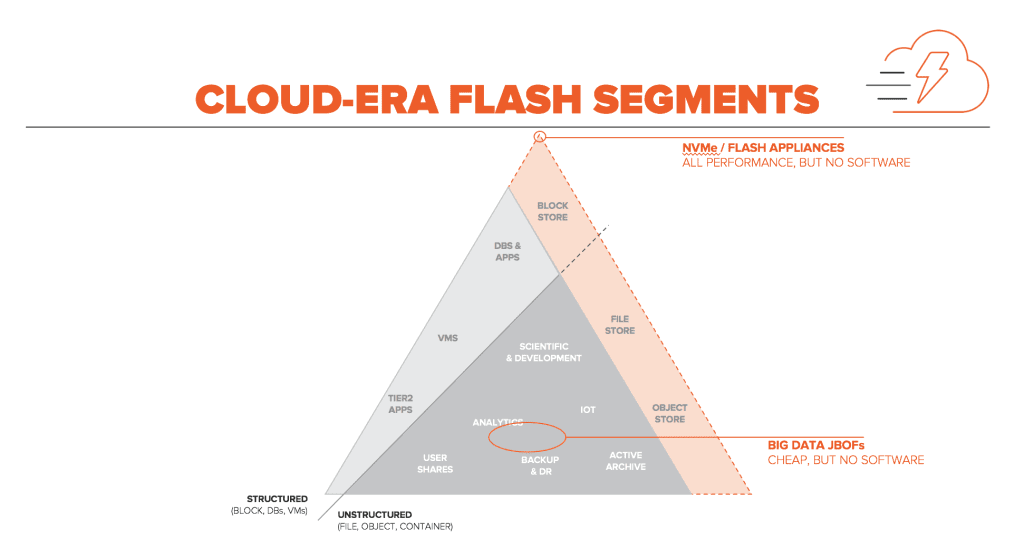
We know that Pure isn’t alone in trying to address these new cloud-era needs. In fact, we see two other segments of vendors building solutions for this space:
First, there are a new crop of NVMe-focused startups, who are either taking appliance or SDS-focused approaches to NVMe. Like the first go-round, these startups are all going for the ultra-high performance niche, and focusing on performance over software or reliability. We believe, like the first time around, that this is ultimately a niche market.
Second, there are a few vendors creating big data JBOFs – big tubs of flash that are relatively less expensive, but have no storage services. Again – all flash but no software just isn’t interesting.
If you’d like to read IDC’s take on cloud-era flash and these segments, you can download the Tech Spotlight whitepaper from IDC’s storage analyst Eric Bergner.
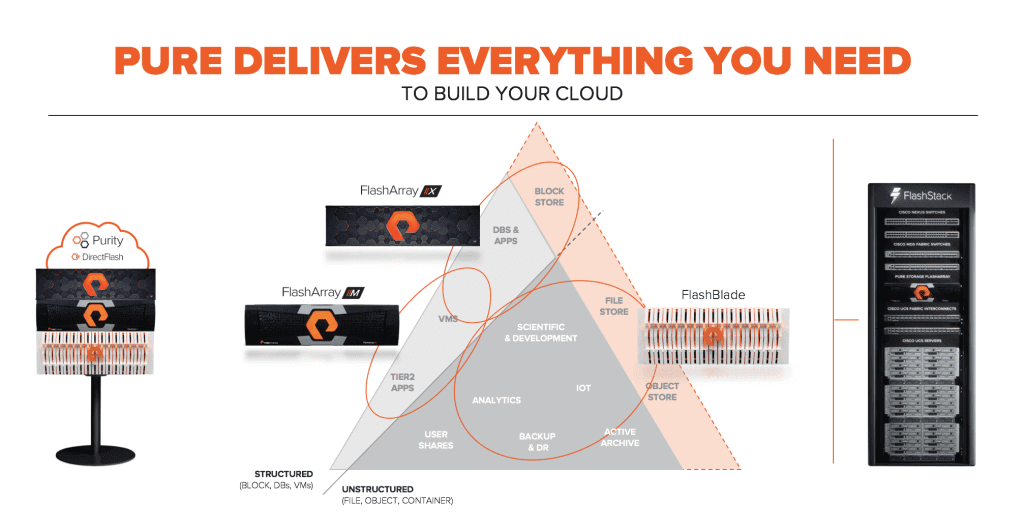
At Pure – we believe our Data Platform for the Cloud Era is all you need:
- FlashArray//M for the most economical consolidation to enable all-flash everywhere
- FlashArray//X for the highest-performance Tier1 databases, application consolidation, and cloud-era block stores
- And FlashBlade for large-scale unstructured data like analytics, IoT, simulation and design, software development, and cloud-era file and object stores
As flash evolves, we think the difference between true end-to-end purpose-built innovative solutions for the cloud era vs. retrofit legacy solutions has never been clearer:

FlashArray//X with NVMe is Ready for Mainstream Adoption Now!
We’re excited to announce today that FlashArray//X is available to order. After a quarter-long beta program, we’re opening-up FlashArray//X to everyone via our Directed Availability (DA) release.
At Pure, we introduce new products by first shipping a DA release, and then shipping a General Availability (GA) release roughly a quarter later. DA and GA are both production-ready products that can be purchased, run in production, and fully-supported by our team. In the DA phase, Pure is involved in every deployment so that we can better understand use cases and customer results. GA is expected in early 2H 2017.
We’re also phasing-in capacities, where at DA the 2.2 TB and 9.1 TB DirectFlash Modules, with the 18.3 TB module being available at GA. In DA, we’ll only be supporting new //X installs, and upgrades from FA-400 and //M to //X will be supported at GA.
If you are in the market for an AFA in 2017, we’d suggest you ask your vendors some tough questions on the path to NVMe:
- When will you ship NVMe as the primary storage in your AFA (not just a cache / NV-RAM)?
- What will the cost of NVMe-connected flash be compared to SAS flash?
- Is the AFA I’m buying upgradable to NVMe? If so, how, and how much will it cost? What happens to the investments I’ve made in SAS flash?
- How have you optimized your software for the parallelism and performance of NVMe?
FlashArray//X powered by 100% NVMe is here. It’s now. It’s affordable. We can’t wait to see what you do with it!