
Apache Spark is a powerful tool for parallel processing of many data types. But for users with datasets with high file counts, there is one notable exception to the parallelism: the enumeration of datasets. This enumeration happens when a dataset is first loaded from persistent storage; if that enumeration is painfully slow, then it can easily become the slowest part of an analytics job. When that happens, it’s time to look at ways to optimize!
RapidFile Toolkit Overview
RapidFile Toolkit is a suite of replacements for standard linux filesystem utilities:
- ls -> pls
- find -> pfind
- du -> pdu
- chown -> pchown
- chmod -> pchmod
- rm -> prm
- cp -> pcopy
RapidFile Toolkit is installed via a provided rpm or deb file and requires zero configuration; just use the tools on an NFS mount as you made their original counterparts and they will automagically parallelize operations. RapidFile Toolkit works even if the mount is volume-mounted in a Docker container.
I will focus here on a common bottleneck in Spark workflows by using ‘pls’ as a drop-in replacement for the stalwart linux tool ‘ls’.
Why Spark and RapidFile Toolkit
Use Spark and RapidFile Toolkit to parallelize all parts of the workflow and scale-out. For most workflows, Spark is an excellent tool to achieve parallelization of work, but there is an exception in the very first phase of a Spark job: dataset enumeration. Enumeration of the files that comprise a dataset (e.g., loading a dataframe) happens in the Spark Driver and in serial code paths.
The spirit of Spark is to build analytics by leveraging operations (map, groupBy, et al) that can be automatically parallelized. Consider the scenario of a dataset made up of one million small log files; Spark is an excellent tool to perform scalable analysis of those log files. But Spark leverages non-parallel code to actually “discover” those log files. RapidFile Toolkit brings full parallelism to that step, enabling the enumeration to happen as much as 100x faster, all by sending many requests in parallel to the remote filesystem.
To illustrate with a simple test on a FlashBlade NFS server, I measured the time taken to enumerate 920k files in a single directory. The performance difference is even larger with nested directory structures.
| STANDARD LINUX UTILITIES | RAPIDFILE TOOLKIT | |
| ‘ls’ on flat directory (920k files) | 120s | 29s |
| ‘find’ on nested dirs (9k dirs, 93k files) | 335s | 9s |
The server itself is able to enumerate the dataset faster if more requests are sent, so it is the default client tools that limit performance.
With RapidFile Toolkit installed on the Spark driver node, integration is straightforward through the language’s shell tools, e.g., subprocess in PySpark. In the examples below, RapidFile Toolkit is installed into the Spark Docker image.
Example 1: Building RDD From Many Files
This first example PySpark notebook demonstrates basic usage of RapidFile Toolkit with Spark by creating a higher performance replacement of the standard Spark read.text() call.
Complete notebook here.
Most Spark datasets are made up of many individual files, e.g. one file per partition, which helps provide parallelism when reading and writing to any storage system. For a text dataset, the default way to load the data into Spark is by creating an RDD as follows:
my_rdd = spark.read.text(“/path/dataset/”)
Note that the above command is not pointing to an individual file but rather a directory. The set of files in that directory together make up the dataset.
To build this dataset, the Spark driver program walks the directory to find all individual files. This step happens on the driver and is not parallelized: the code path is serialized and confined to one node.
Processing log files is a common use-case where there can be millions of individual files that make up the set of logs. When the above command needs to enumerate millions of files, this can take a long time (minutes to hours) because the process is serialized. As a result, this first phase of the job dominates the overall run time.
The following two Python functions utilize RapidFile Toolkit to parallelize this process. RapidFile Toolkit pls is invoked on the driver node through a subprocess call, resulting in an array of filenames. I then use the standard PySpark function parallelize() to convert that array into an RDD. The final piece of this is a flatMap() function that converts each filename to that file’s contents via standard read() and splitlines() calls.
def readContents(f):
with open(f, “rb”) as fd:
return fd.read().splitlines()
def pureReadText(path):
result = subprocess.check_output([“pls”, path])
lrdd = sc.parallelize(result.decode(‘utf-8’).splitlines(), 2400)
lrdd = lrdd.filter(lambda x: os.path.isfile(x))
return lrdd.flatMap(readContents)
Note that spark.read.text() accepts a list of path-like objects. Directly passing the output of RapidFile Toolkit to spark.read.text() still results in a single-threaded traversal so this approach still has the same serialization bottleneck.
The functions above can then be used as a replacement for the default read() function as follows:
my_rdd = pureReadText(“/path/dataset/”)
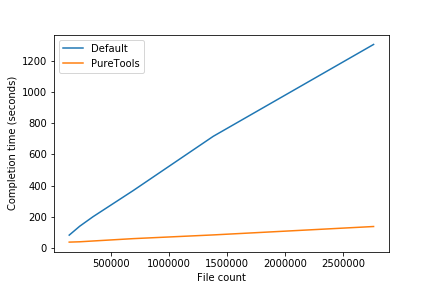
To demonstrate the difference in performance, I ran an experiment that increased file counts and compared the default approach with the RapidFile Toolkit-optimized code above.
The configuration for my experiments is a 24 node Spark cluster, each node with 40 cores and 128GB of RAM. Each test measures the time to completion of the job, i.e., lower is better, running on all 960 available executors. The data set for this experiment is a 300GB Wikipedia text dump that is split into a variable number of files. The actual data reads from the FlashBlade take ~30s for all experiments.
For the smallest experiment with 140k files, the total time for the RapidFile Toolkit code is ~38s, the first 8s for listing files and the remaining 30s for reading the data. As the number of files increases, reading the data remains roughly the same length but enumerating the dataset takes longer and longer.
The default approach is noticeably slower even at the smallest test file count (140k files) and the gaps grows to 10x as the number of files increases to 2.8M.
Another disadvantage of using the standard read() functions to build a dataset is that the number of resulting partitions is often very large, resulting in unnecessary IO during shuffle operations. This in turn requires the addition of an extra coalesce() operation to keep the dataset properly-sized.
Finally, this simple Spark job can also be made to aggregate small files into a reduced number of larger files simply by saving the constructed RDD:
pureReadText(“/path/dataset/”).saveAsTextFile(“/path/dataset_merge”)
Example 2: Spark Rsync (PTSpark)
The second example of using the RapidFile Toolkit builds an rsync/distcp “clone” PTSpark using Spark, capable of handling directories with large numbers of files. Focusing on RapidFile Toolkit usage, I make the assumption here that both source and destination are NFS mounts.
Complete notebook here.
To start, this example leverages a feature within RapidFile Toolkit that is not in the standard linux tools: the ability to output directory listings in JSON format. The data is the same as though using “ls -l” but it is returned with a schema that is easier to work with using PySpark dataframes functionality.
Below is an example of the JSON output. This is easily converted to a dataframe in Spark, with the schema automatically inferred and is therefore much less error-prone that text parsing and manually extracting columns. Using the “ — json” feature of pls to give us a richer dataset to work with:
> pls --json foo/
{“dirid”: 58546795221231697, “fileid”: 13510798965073559, “mode”: 400, “nlink”: 1, “uid”: “root”, “gid”: “root”, “size”: 1024, “atime”: 1536963627, “mtime”: 1535662945, “ctime”: 1535662945, “path”: “\/foo\/key”}
The rsync functionality needs to compare the source and destination directories and copy only the new or changed files from the source. Always in search of concurrency, I use the following pattern to retrieve the source and destination directory contents in parallel.
p1 = subprocess.Popen([“pls”, “-a”, “--json”, srcdir], stdout = subprocess.PIPE, stderr = subprocess.PIPE)
p2 = subprocess.Popen([“pls”, “-a”, “--json”, dstdir], stdout = subprocess.PIPE, stderr = subprocess.PIPE)
(result1, error1) = p1.communicate()
(result2, error2) = p2.communicate()
Next, I use dataframes to represent the entries in the source and destination directories, allowing me to do a join on the two tables and determine what copies/deletes need to be done. Creating the dataframes from JSON is straightforward:
# Convert listings to dataframes to parallelize the checks and copies.
srcfiles = spark.read.json(sc.parallelize(src_raw.splitlines()))
dstfiles = spark.read.json(sc.parallelize(dst_raw.splitlines()))
The result of using the JSON representation is a dataframe and schema that makes working with the file listing very easy.
> srcfiles.printSchema()
root
| — atime: long (nullable = true)
| — ctime: long (nullable = true)
| — dirid: long (nullable = true)
| — fileid: long (nullable = true)
| — gid: string (nullable = true)
| — mode: long (nullable = true)
| — mtime: long (nullable = true)
| — nlink: long (nullable = true)
| — path: string (nullable = true)
| — size: long (nullable = true)
| — uid: string (nullable = true)
In order to join the tables, I then do two things: 1) rename the schema on the destination table so that the source and destination columns can be distinguished and 2) create a name column containing just the filename. It is with the filename column that I can then join the two tables.
# Rename all columns in destination table to have a prefix,
# distinguishes src and dst in joined table.
dstfiles = dstfiles.rdd.toDF([“dst_” + n for n in \
dstfiles.schema.names])
# Add a column in each table for “filename” for join key.
basename_udf = UserDefinedFunction(lambda p: os.path.basename(p),
StringType())
srcfiles = srcfiles.withColumn(‘filename’,
basename_udf(srcfiles.path))
dstfiles = dstfiles.withColumn(‘filename’,
basename_udf(dstfiles.dst_path))
The tables are joined based on the newly created column. The result is a joined table that contains information about all files and is an easy dataset to work with to make rsync choices: copy, delete, or no action.
# Outer join of both tables to pick files in either or both places.
joinedfiles = srcfiles.join(dstfiles, ‘filename’, ‘outer’)
Finally, foreach() invokes the copy for each file entry in the joined table.
# Invoke parallel copies.
joinedfiles.foreach(copier)
When using foreach(), it is recommended to make your operations idempotent as they may sometimes be repeated depending on Spark worker scheduling.
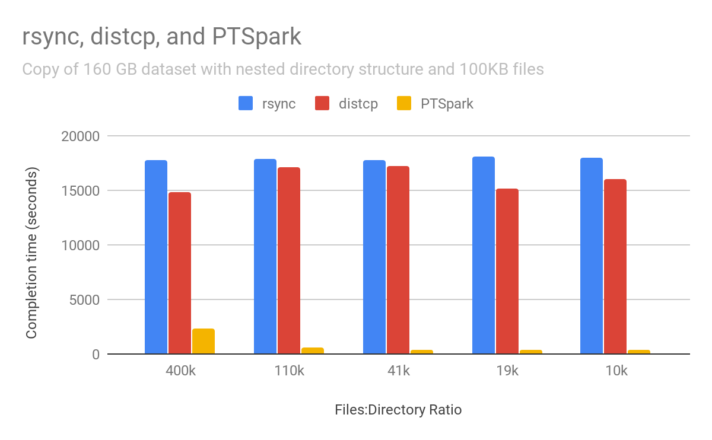
The performance of the above code was tested by copying a dataset consisting of 1.6M files, each of which is 100KB. The level of directory nesting varied in order to show the impact of the ability to parallelize the file copies.
To contrast the parallelism in PTSpark, I compare against the traditional tree-copy tools rsync and distcp. Standard rsync is the most widely used tool, but is single-threaded. Distcp is part of Hadoop and leverage MapReduce to parallelize the copies, but is still single threaded in the directory enumeration step. Both rsync and distcp enumerate files in a traditional single-threaded directory walk, but we expect distcp to be faster because it speeds up the file copies. PTSpark similarly parallelizes the copies but also parallelizes the file enumeration step, resulting in significant performance gains.
For nested directories, PTSpark is over 40x faster than distcp and rsync. PTSpark is faster with more directory nesting because that allows more parallelization in the write path. When all Spark tasks write to the same directory, all updates are serialized on the directory inode, reducing concurrency.
To better understand the performance of PTSpark, I next break down the time for the first file enumeration phase (using RapidFile Toolkit) and the second copy phase. The following graph shows that as the ratio of files per directory decreases, the ability to parallelize the copies increases. This copy phase of PTSpark can take full advantage of parallelism from the workers.
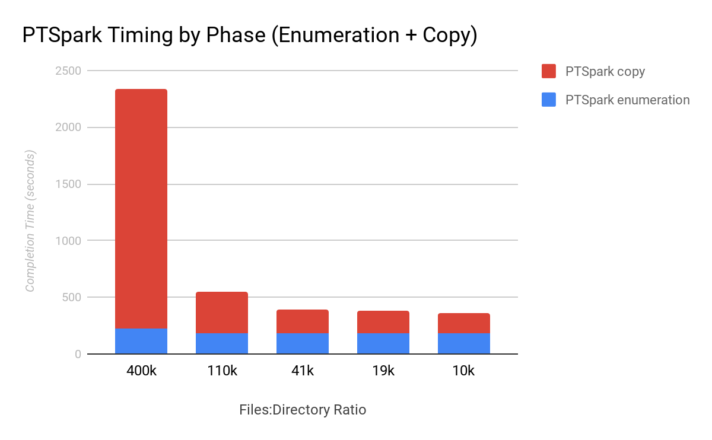
The enumeration phase takes approximately the same amount of time for different directory nesting, indicating RapidFile Toolkit is able to fully parallelize the traversal in flat and nested hierarchies.
Summary
For Spark workflows with large numbers of files, RapidFile Toolkit fills in the missing parallelism in the crucial enumeration phase of loading datasets and working with them. With small changes to the workflow to introduce RapidFile Toolkit instead of the default directory listing code paths, overall job runtimes can decrease by orders of magnitude as file counts grow to the millions.




