


An effective AI process simplifies the work of developers and data scientists and minimizes all bottlenecks within the flow of data from sources to accurate outcomes. Do you find yourself wishing that data sets loaded and copied faster? That you didn’t have to think about where to put your code or Docker images? How about adding hassle-free persistent storage for your Kubernetes services?
Experienced data scientists have come to appreciate that if the storage underneath AI projects is good, then you don’t have to waste time thinking about those kinds of issues.
Here are six ways better storage can help solve data science problems—some obvious, others not.
1. You can ensure random read processes don’t become bottlenecks
Training models are the clearest interaction between developers and storage. As training jobs read data sets again and again, they’re driving a constant random read workload. GPUs process data quickly, so you want your data to be accessible from storage that performs well and scales predictably. To achieve this, you’ll need to optimize non-sequential (random) read throughput from your storage. Fast shared storage can accomplish this effectively and also eliminates copy steps without depending on caching for good performance.
2. You can make the most of your iterative training processes
Storage built to handle fast, sustained read throughputs, inclusive of multiple formats and classes, is advantageous to processing iterative training processes.
Before training starts, it’s important to examine the contents of the data set. Look at the format and the content distribution. Data sets frequently need to be wrangled. For example, take a scenario where the data contains major class imbalance. It might take a series of experiments to ensure that classes are detected properly. These investigations could range from label merging, undersampling, or adjusting focal loss. But those projects add to the read throughput burden on storage.
However, data is often not-clean and requires several reading parses before a decision can be made around which part(s) of the data can be used for training. And even when the data is “clean”, data scientists still often have to adjust training data sets and include or exclude specific data points as they iterate toward a final model. You need to plan for these extensive re-reads of the entire data set.
3. Be able to process all file sizes and formats
Data sets include a mixed bag of “types” of data including millions of small metadata bounding boxes, annotations, tags, etc as well as files and objects of varying sizes. If your storage is optimized only for large file reads, it could perform poorly for AI workloads, which tend to involve many different types of files.
The ideal data storage platform handles billions of small objects and metadata, as well as delivers high throughput for large objects.
4. You can stop worrying about creating additional data sets
When data scientists have the storage space to build more deep learning-friendly versions of data sets, it exponentially improves their time to results.
While academic projects in AI focus mainly on GPU work, real-world deployments must also consider the data-loading work (input pipeline). Real-world data is often larger than academic data. For example:
- ResNet-50’s input size is 224 x 224 pixels.
- The majority of ImageNet files are smaller than 500 x 500 pixels.
while, real world data such as,
- A digital pathology image can be 100,000 x 60,000 pixels.
It’s often impractical to resize images on the fly. It takes too long and requires more time on the GPU server’s CPU. Many teams choose to permanently save “chipped” versions of the data set to reuse as the new training data set.
5. You can stop worrying about overwhelming write throughput
While reads from storage dominate storage traffic by volume, writes can also overwhelm storage if there are many concurrent projects. During a training job, most scripts write out a checkpoint of the model file back to storage. Better data storage can help you handle many developers writing their model files simultaneously. It can scale and perform predictably as the number of jobs or checkpoints increases.
6. You can eliminate metadata bottlenecks

Figure 1. Listing all the files in the data set takes time
Training jobs randomize the order in which they process data so that models are more resilient and stable for predicting all classes. Before randomizing the file order, the training job lists all items in the data set so it’s aware of all files that need to be shuffled.
Many deep learning (DL) data sets are structured as directories with a large number of subdirectories. Files from each subdirectory are listed (often via ls as part of os.walk) before shuffling. When data sets contain millions of items, listing every file can take anywhere from several minutes to twenty or more.
That step has to happen at the start of every single training job, which is repetitive and wastes time.
Storage can help solve this problem in two ways:
- Commands like ls are executed serially by default. If storage supports a parallel version of ls, it can improve listing files by up to 100x and greatly reduce the time needed for shuffling at the start of each job by removing hidden metadata bottlenecks.
- Alternatively, developers may consider saving out a manifest of the data set’s contents, especially for static data sets. That single file could provide the information needed to shuffle the data set (i.e., read it in a random order) without walking the whole file tree at the start of each training job.
Support Your Entire AI Pipeline With a Data Platform that’s architected for AI workloads
Without team-wide planning, data scientists tend to work with environments that are scattered and unofficial. If IT teams have a centralized dev platform for their data scientists, it’s much easier to keep dev work secure and backed up, minimize data set duplication, and onboard new users.
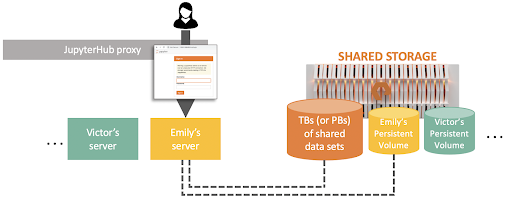
Figure 2: Example of centralized IDEs for data scientists using JupyterHub inside a Kubernetes cluster.
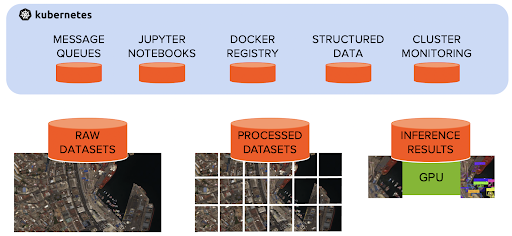
Put all those data flavors together on a consolidated storage server to simplify AI infrastructure management. Ideally, that central data platform would also support data from other pieces of the platform, including Docker images and monitoring/logging tools with high-performance data storage.
Once a model is ready for production, it needs to be hosted somewhere. It needs monitoring and a way to set up pipelines that continuously retrain the model with new data. Incoming data needs a place to land, and inference results need to be preserved and shared.
Storage that supports the entire pipeline can minimize data copy time and enable cross-pipeline monitoring, alerts, and security.
The Takeaway
Building deep-learning models is a journey that drives a wide range of I/O patterns on the underlying storage. At first glance, it seems storage should be optimized for random-access read throughput of large files, but a holistic view of the development process shows that this is only part of the story. The workloads will also tax storage performance for small files, metadata, and writes.
When there’s a tool and business process that you depend on all the time, it’s worth investing in a reliable, high-quality version of it. If you’ll be doing deep learning at scale, see if you can simplify both developer and IT team processes by using a fast, versatile storage solution that meets all of the diverse AI needs.
Pure Storage will be at several North American AI events this
November 2022. Visit us at:
AI Summit – Austin Nov 2nd – 3rd, 2022
ODSC West – San Francisco – Nov 1st – 3rd, 2022
Super Computing Conference – Dallas – Nov 13th – 18th
![]()



