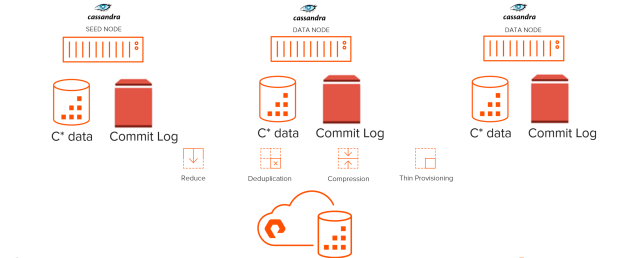
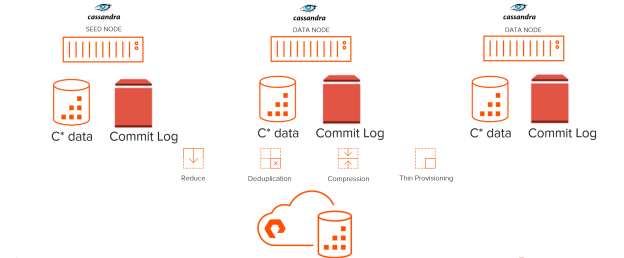
Modern databases like Apache Cassandra significantly benefit from a management and efficiency standpoint, by deploying on Cloud Block Store on AWS. Cassandra operations such as node replacement, backups, and cluster copies are very tedious and time consuming to perform. These operations can be greatly accelerated by leveraging the native data services provided by Cloud Block Store.
In this blog, I am going to recommend the optimal methodology of deploying Apache Cassandra on Pure Storage Cloud Block Store without any performance penalties. I will also demonstrate the benefits of Cloud Block Store which will aid Cassandra administrators to manage and operate Cassandra clusters easily and efficiently.
Pure Storage Cloud Block Store delivers industrial-strength cloud reliability for mission-critical applications, with non-disruptive upgrades, high-availability (HA) across availability zones, and provides “always-on AES-256” data-at-rest encryption. It is architected for performance and reliability by bundling together the highest performing and highest durability public cloud resources, combined with a highly available dual controller architecture. Pure Cloud Block Store’s high data reduction rates, with always-on thin provisioning, deduplication, and compression, ensure capacity is consumed efficiently.
Recommended Architecture
In order to deploy the Apache Cassandra database on Pure Storage Cloud Block Store, we recommend the following hybrid architecture:
For Cassandra data, use Cloud Block Store volumes. The Cassandra data files, which make up 99% of the total capacity usage, can reside on Cloud Block Store volumes. Using Purity’s advanced compression and deduplication, Cloud Block Store can help reduce the total data footprint. This will also allow administrators to leverage Cloud Block Store snapshots.
To ensure sub-millisecond write latency, it is recommended to use EBS IO1 volume for Cassandra commit logs. EBS IO1 is a small footprint (only) for log files and with IO1 customers can get a prescribed number of IOPS and low latency.
Performance testing
We have tested and compared our hybrid architecture (commit logs on IO1 + Data files on CBS) with t native IO1 for both commit logs and data files. In our setup, we deployed a three-node Cassandra cluster running cassandra-stress benchmark.
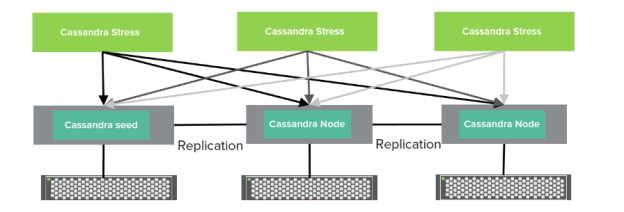
Each cluster consisted of three nodes, one seed node used for bootstrapping the gossip process and two peer nodes.
- In the hybrid setup, the data volume and the commit logs were mounted using Cloud Block Store volumes and EBS IO1 with xfs file system, respectively.
Specifications of each node for the Cassandra cluster are:
OS: Centos 7.6
Host to Cloud Block Store Connectivity protocol: iSCSI
Apache Cassandra version: 3.11.3
EC2 Instance type: m5.12xlarge
Storage: Cloud Block Store, EBS(IO1)
- In the native IO1 setup, a similar cluster was built with three nodes with both Cassandra data and commit logs on IO1.
Specifications of each node for the Cassandra cluster are:
OS: Centos 7.6
Apache Cassandra version: 3.11.3
EC2 Instance type: m5.12xlarge
Storage: EBS(IO1)
The Cassandra stress generator tool was used to generate load on the three-node cluster. The keyspace used by Cassandra-stress has a replication set to 3. The testing consisted of only writes (updates). The keyspace used by Cassandra-stress was configured with durable writes. When durable writes parameter is set true for each write IO, the Cassandra node first writes the data to an on-disk append-only structure called commitlog and then it writes the data to an in-memory structure called memtable. When the memtable is full or reaches a certain size, it is flushed to an on-disk immutable structure called SSTable. Three Cassandra-stress instances were running in parallel against three Cassandra nodes as shown above. In order to saturate the cluster, each Cassandra-stress instance is connecting to the other three nodes to generate the load. The CQL (Cassandra Query Language) generates an update statement for writes which have identical performance characteristics as insert statements in Cassandra. Cassandra database compression was enabled.
Keyspace information used by Cassandra-stress is provided below:
CREATE KEYSPACE keyspace1 WITH replication = {‘class’: ‘SimpleStrategy’, ‘replication_factor’: ‘3’} AND durable_writes = true;
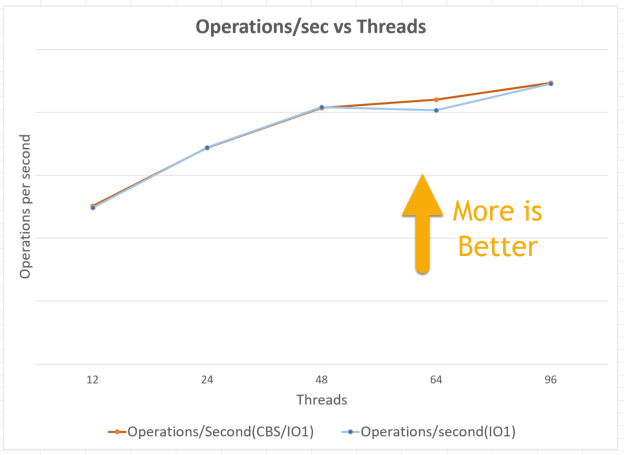
The chart below shows operations/sec vs threads. Results are shown for both tests, hybrid (CBS+IO1) and native IO1. This test consists of 100% write operations using Cassandra stress. As seen below, the performance of C* deployed on hybrid CBS+IO1 is at-par or better than C* deployed on native IO1 completely as the number of threads was increased.
The next chart shows the performance difference in terms of latency of commit logs in ms vs threads. This test also consists of 100% write operations using Cassandra stress. As seen below, the performance of C* deployed on hybrid CBS+IO1 is at-par with C* deployed on native IO1 as the number of threads was increased.

As seen from above, the Cassandra cluster deployed on Cloud Block Store and IO1 combination has the same performance characteristics as the C* deployed solely on IO1. In addition to it Cloud Block will have all the other value propositions mentioned below.
Summary: Cassandra on Cloud Block Store
Deploying a Cassandra cluster on a combination of Cloud Block Store and native IO1 volumes can provide the perfect cost-effective solution without any differences in performance. Since 99% of the Cassandra data resides in Cloud Block Store, the data reduction minimizes the AWS footprint by a good margin consequently reducing EBS costs while providing resilient enterprise-level storage. Additionally, Cloud Block Store snapshots can be leveraged to remove the tedious operations such as backups, failed node replacement, and adding cluster copies. We highly recommend this approach and would like you to try Cloud Block Store for your Apache Cassandra deployments on AWS.



