
Early last year Pure Storage® launched DirectFlash® Fabric, extending the NVMe protocol from the array to the servers using NVMe/RoCE as the initial fabric transport. Until recently, native NVMe-oF support has been limited to Linux distributions. That changed in April when VMware announced the release of vSphere 7.0 with NVMe-oF support for Fibre Channel (FC) and RDMA over Converged Ethernet (RoCE).
Many users who are interested in modernizing their storage area networks (SAN) to use the NVMe end-to-end have been stalled by OS support. The inclusion of NVMe-oF support by VMware marks an important milestone on the road to widespread adoption of the technology.
You may be thinking, why even consider NVMe-oF? Performance and overall data center density optimization are primary factors.
Many Pure Storage users leverage FlashArray™ devices in their VMware environments and a large percentage utilize iSCSI for connectivity. With NVMe/RoCE support, FlashArray and vSphere 7.0 provide customers with alternative transport for Ethernet connectivity.
NVMe/RoCE provides a more efficient and streamlined stack and allows vSphere hosts to communicate with the FlashArray using native NVMe commands.

I thought it might be useful to provide some baseline testing around the two protocols to highlight the benefits of NVMe/RoCE compared to iSCSI.
Testing Setup
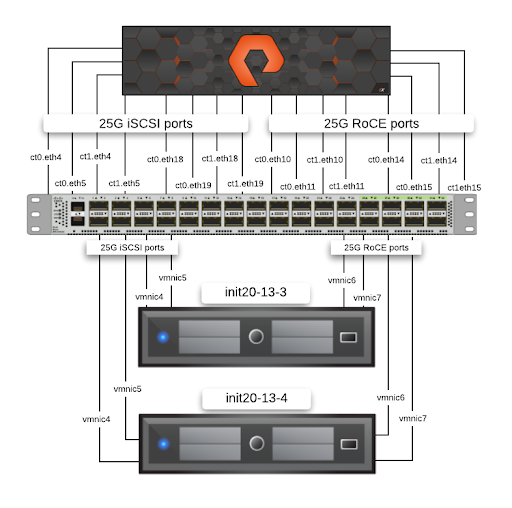
To start, I set up a testbed that had both iSCSI and NVMe/RoCE connectivity between a vSphere 7.0 host and FlashArray by using a host that has dual E5-2670 processors and 256GB of memory. The host also has two Mellanox ConnectX-5 adapters (MCX512A-ACAT) connected at 25Gb/s to an upstream switch. One of the adapters provided two ports for iSCSI while the other provided two ports for NVMe/RoCE.
I connected the FlashArray//X device to the same switch using 2x25Gb/s LOM ports and 2x25Gb/s adapter ports per controller for iSCSI (total of 8x25Gb/s) and two 2x25Gb/s RoCE adapters per controller for NVMe/RoCE (total of 8x25Gb/s).
Typically, we recommend a pair of network switches for HA-redundancy purposes, but because the testing didn’t include failover scenarios, the testbed uses a single 100Gb/s switch with breakout cables running at 25Gb/s.
The next step was to test performance for VMs using iSCSI vs. NVMe/RoCE datastores. Let’s start with the premise that there’s more than one way to peel an orange.
In my initial testing, I created a Linux VM with a single iSCSI-connected datastore and another with a single RoCE-connected datastore formatted with ext2. After that, I ran through some basic FIO testing and recorded the results.
While this wasn’t a horrible methodology and showed good results, it didn’t put the setup under much stress. It’s a bit like taking a Corvette on a test drive in a parking lot.
After some discussion with the VMware engineering team, we landed on a Linux VM setup that included a datastore for the OS and then eight separate raw datastores that would represent the test drives. We distributed the drives across four controllers and duplicated the setup for RoCE and iSCSI.

While there are probably many other possible scenarios, these tests put enough stress on the host and the array to demonstrate the efficiencies of NVMe/RoCE without inflating the results.
Modifications
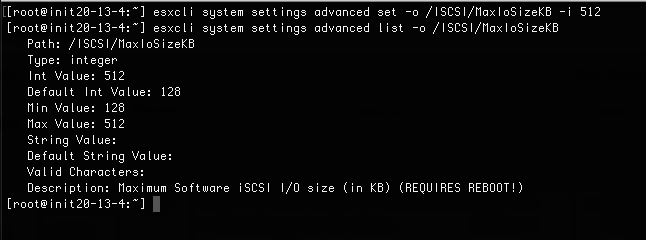
The first thing I noticed was that I couldn’t get any of the iSCSI tests to run over a 64K-packet size, so I changed the maximum packet size and referred to the “Web Guide: FlashArray VMware Best Practices” for other iSCSI recommendations.
|
1 2 |
esxcli system settings advanced set –o /ISCSI/MaxIoSizeKB –i 512 esxcli system settings advanced list –o /ISCSI/MaxIoSizeKB |
I also noticed that I seemed to be hitting a wall with iSCSI performance that was much lower than expected compared to the RoCE performance. This was because I was only testing a single initiator and was limited by the number of iSCSI connections to the array. To improve this, I added additional iSCSI sessions via esxcli.
|
1 |
esxcli iscsi session list |

|
1 2 |
esxcli iscsi session add –A vmhba64 –s 00023d000001 –n iqn.2010–06.com.purestorage:flasharray.2f46039d01061921 |

Results
The first set of tests provided a baseline for performance expectations. These tests compared the results of a VM with an iSCSI-connected datastore to that of an identical VM with a RoCE-connected datastore across various block sizes with only a single thread. These tests show the scenario where the performance isn’t impeded by additional latency added by the vSphere host or the array.
Baseline Testing
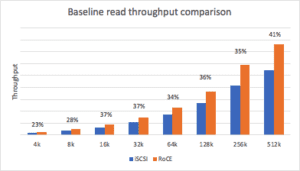
The baseline read throughput distribution is a range of 23-41% more throughput for NVMe/RoCE compared to iSCSI with larger block size providing the higher benefit.
The baseline read latency distribution for NVMe/RoCE is a range of 71-81% of the latency compared to iSCSI with the larger block sizes providing the higher benefit. The reduced latency of the more efficient NVMe/RoCE stack provides a higher throughput benefit.

The baseline write throughput distribution is a range of 5-31% more throughput for NVMe/RoCE compared to iSCSI with the midrange block sizes providing the higher benefit.
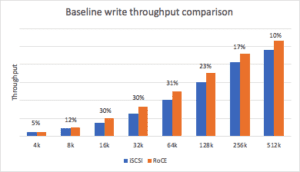
The baseline write latency distribution of NVMe/RoCE is a range of 76-95% of the latency compared to iSCSI with the midrange block sizes providing the higher benefit. Once again, the reduced latency of the more efficient NVMe/RoCE stack provides the higher throughput benefit.
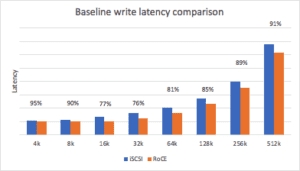
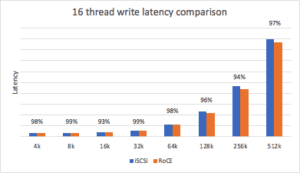
The baseline is interesting in the sense that it shows an expected range, assuming everything is equal, but what about a system under load? To get a sense of how each transport performed over load, the number of threads was tested at various levels until we started seeing diminishing returns of performance due to the increased latency caused by the additional threads. For this setup, the optimal thread count was 32 for reads and 16 for writes.
Load Testing
The read throughput distribution under load for NVMe/RoCE is a range of 1-105% more throughput compared to iSCSI. Block sizes above 32K had a range from 78-105% more throughput using NVMe/RoCE.
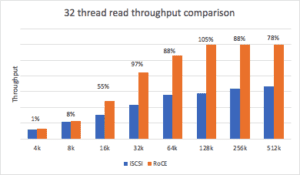
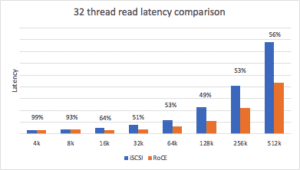
The read latency distribution for NVMe/RoCE under load is a range from 51-99% of the latency compared to iSCSI. Like the read throughput, block sizes above 32K demonstrate the most improvements, ranging from 49-56% of the latency compared to iSCSI.
An interesting data point about the read throughput and latency differences is that under load, the efficiency of the NVMe/RoCE protocol shows remarkable improvements vs. the single-thread operation. This is because the iSCSI latency is higher because of the software overhead on the host and the array. This increased latency in turn reduces the throughput for iSCSI.
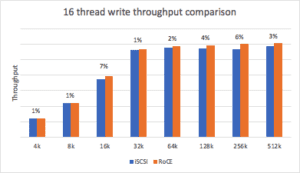
The write throughput distribution under load is a range of 1-7% more throughput. Block sizes above 8K show slightly better performance. Note that the maximum throughput curve stabilizes at around 32K block size, indicating that we have hit a threshold in this setup.
The write latency distribution under load of NVMe/RoCE is a range of 94-99% of the latency compared to iSCSI.
The write throughput and latency improvements demonstrated under load, while still present, are not as significant as seen in reads, indicating that the software inefficiencies for iSCSI may not have as much impact on the latency at scale. However, more analysis would be needed to determine the true nature of the thresholds being hit in the setup.
Conclusion
This is the first release of NVMe-oF for vSphere, which means it’s likely more of a functional release than a feature and performance-optimized release. I suspect that we may see enhanced performance in future releases, but even with this release, there’s clear evidence that NVMe/RoCE performance is significantly better than that of iSCSI, especially for read-intensive workloads.
At this point, you should begin testing NVMe-oF with vSphere 7.0 and identifying workloads that may benefit from the enhanced performance. Performance-critical database workloads, including OLTP and OLAP, are a great place to start. Cloud-native apps, which have typically been run on DAS for performance optimization, can run on shared storage and be virtualized with all of the benefits and enterprise features that come with VMware and Pure Storage. One of the compelling reasons for enabling NVMe/RoCE with vSphere 7.0 and FlashArray//X is that Ethernet users can still utilize iSCSI where there may be feature gaps with NVMe/RoCE since Pure supports both protocols at the same time on the same array.
Looking Ahead
If you’re looking to start testing NVMe/RoCE, there’s an important element to consider: NVMe/RoCE requires a lossless Ethernet network. You can accomplish this using IEEE 802.3x pause, IEEE 802.1Qbb Per-priority flow control (PFC), or RFC 3168 explicit congestion notification (ECN). Stay tuned for my next post, in which I’ll discuss some network-standard design considerations and best practices when deploying NVMe/RoCE with vSphere 7.0.



