


On April 26, Pure Storage announced the general availability of the first truly Unified Block and File Platform. This introduces three new areas of innovation:
- Native block and file: FlashArray™ introduces native block and file architecture built on a single global storage pool, simplifying management and treating both services as equal citizens—the first truly Unified Block and File Platform in the market.
- NFS datastore: This VMware-certified NFS datastore solution integrates directly into the VMware ecosystem for automation and expands the much-desired workload consolidation in the file market.
- VM-aware management: This new management paradigm provides workload granular management for virtualized applications based on NFS datastores.
The foundation of the FlashArray unified block and file approach is a radically different architecture that increases flexibility and removes any need to pre-plan your deployment. This enables the ability to configure and consume resources dynamically without having to consider potential impact in advance. Resources are considered global and eliminate multiple levels of abstraction typically seen in multi-protocol arrays. This is a modern approach to unified block and file, dramatically simplifying how workloads are consolidated.
Legacy Vendors Fail to Deliver the Promise of Unified Storage
Legacy vendors have made many promises about their “unified” block and file storage. These included consolidating block and file workloads onto fewer storage systems, achieving greater utilization (reducing CAPEX), and simplifying operations and management overhead with fewer storage endpoints (reducing OPEX).
However, legacy storage vendors approached this by taking existing storage architectures built for one type of storage service (block or file) and layering—or bolting on—a second set of storage delivery protocols. This creates a storage house of cards.
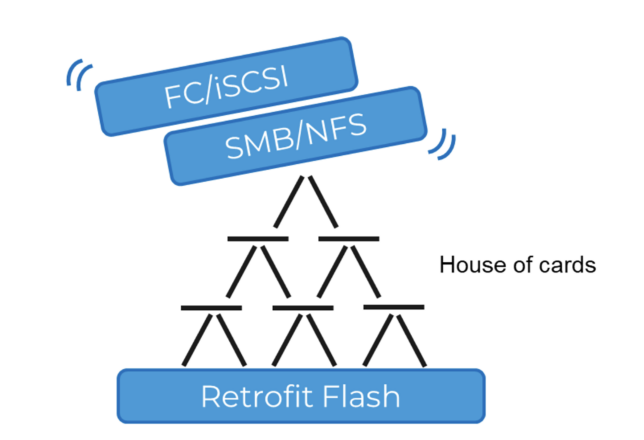
Figure 1: Legacy multi-protocol has become a house of cards.
At face value, these multi-protocol systems may claim to support the consolidation of multiple architectures, but this fails to capture the OPEX savings touted as the ultimate value. Adding more complexity leaves customers with no choice but to stick with dedicated block or file storage for most of their workloads.
The Trouble with Layering Storage Services
The challenge with legacy multi-protocol starts with an architecture built for one type of storage service, with additional storage services bolted on top. Consider LUNs implemented on top of a file system. When vendors do this, they value one storage service (file) over another (block). Exposing multiple layers of abstraction needed to accommodate multi-protocol also means that management is required at all those levels. This makes the management stack inconsistent and complex—sometimes referred to as asymmetric management. Changing anything in a multi-layered stack often triggers limitations and requires compromises across services, as they can’t be operated independently. The architecture fundamentally lacks flexibility.
In most cases, this results in scale limitations, inefficient capacity utilization, or the need to copy/move workloads to other volumes. This mandates careful and continuous planning, the root of the failure to realize the OPEX potential of a unified system.

Figure 2: A files-first architecture, retrofitted for blocks and VMs.
Bolting on storage services creates additional scale limits. Take the architecture in Figure 2 as an example. Disk or flash (first layer) is grouped into a set of RAID groups (second layer) and then storage pools (third layer) which have their own limitations. Storage pools are then broken up into smaller volumes (fourth layer) which have historically had a size limit (i.e., 100TB). Finally, shares and LUNs can be created (fifth layer), and data can be stored.
This multi-layer architecture is inherently complex, and with management spread across the layers, the complexity is multiplied. The areas that create the biggest headache are the legacy size limits of the storage constructs, the pools, and volumes. When planning data placement, these scale limits require significant long-term planning to avoid share, LUN, or VM growth that exceeds the capacity of the volume.
Truly Unified Starts with a Global Pool of Storage
To be truly unified, block and file must be native services deployed from a single global storage pool. FlashArray File Services was built from the ground up for an all-flash storage platform and as a first-class citizen alongside block protocols. Every FlashArray has a self-managed single global storage pool that is shared with both block and file protocols, removing the complexity and rigidness inherent to legacy multi-protocol solutions. This gives customers the simplicity and flexibility to easily scale and grow their file data without the need for extensive pre-planning or post-production risks.
This non-layered approach enables file data to take full advantage of all the data efficiencies of FlashArray, such as global deduplication, data-at-rest encryption, non-disruptive hardware and software upgrades, and Evergreen®.
FlashArray File Services replaces the cumbersome legacy control of data at the file system level with directory-level controls and monitoring to enable customers to manage file workloads/applications more directly. Directory-level management combined with policy-driven configurations allows customers to manage files at any scale, and policies with symmetrical operations oversee all management functions. Once you learn one policy, you’ve learned them all.
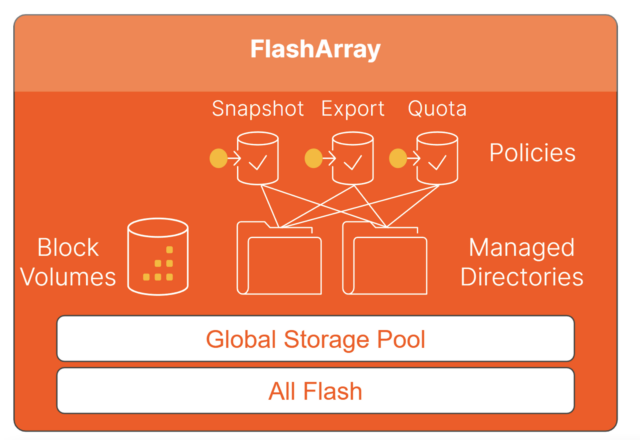
Figure 3: Unified block and file architecture.
Managed directories can have independent or shared snapshots, export, and quota policies. They also allow storage administrators to review both space and performance metrics per directory. Each directory is thin provisioned and lives on the same global pool of storage, and block volumes can grow to the same size as all usable space on the array if needed.
Ditch the Bloat with a New Approach to NFS Datastores
Customers also need a new way to address snapshot bloat. Some of the largest VM implementations in the world utilize NFS datastores. As they scale, they suffer from heavy misuse of storage resources because snapshot policies have limited understanding of underlying NFS datastores. This limits automation with configuration and management, file system sizes, and data protection to the datastore level only.
Today, Pure also is announcing support for VMware NFS datastores on FlashArray. Pure has integrated NFS datastore management into its industry-leading vSphere Plugin. Customers can now deploy an NFS datastore with zero-touch to the array. VM snapshots and restore have also been integrated into the plugin to allow administrators to quickly and easily utilize VM-level native snapshots, massively reducing the capacity needed compared to datastore-level snapshots clogging up legacy systems.
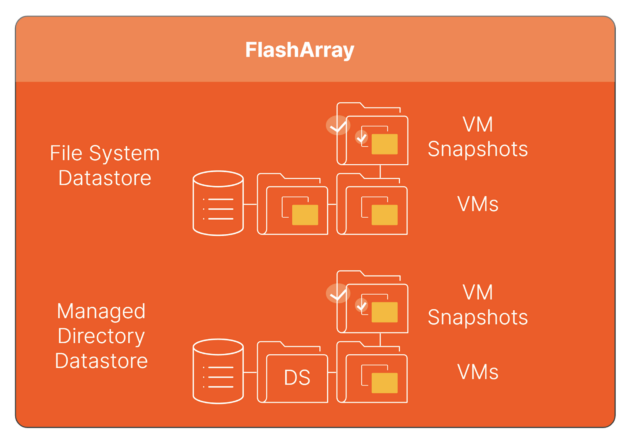
Figure 4: Vmware NFS datastores on FlashArray.
Customers are no longer forced to take snapshots at the datastore level and can now configure VM-granular snapshot schedules and retention (datastore snapshots are still available if desired but not required). Datastores are also not restricted to file systems and can be created at any managed directory for up to eight levels deep in a file system.
VM-aware Storage: The Industry’s First Way to Give Deeper Visibility at the Granularity of the Virtual Machine
NFS datastores support also enabled us to bring the same level of granular management and control we have with block to file. No longer is the file system a black box. VM-aware NFS datastores allow deeper visibility at the granularity of the virtual machine. This is all thanks to managed directories. By applying a new policy to a datastore directory called AutoMD, each VM created in that datastore automatically becomes a managed directory visible to FlashArray.
Administrators can now natively manage VMs on FlashArray, including VM-level statistics, snapshots, quotas, and policies. This is achieved by mapping VMs and managed directories on a one-to-one basis automatically when the VM is created. With VM-aware statistics, you can drill into any managed directory and understand what’s going on. VM-aware quotas enable you to provide granular control to every VM, regardless of location, and VM-aware snapshots let you set granular data protection policies per VM. This granularity gives you more flexibility without losing simplicity.
Truly Unified Ultimately Means Lower TCO
FlashArray File Services brings truly unified block and file to the market, solving the need to support multiple dedicated storage or complex multi-protocol systems. This delivers expected CAPEX savings through consolidation and data efficiency, and the real promise of OPEX savings with a flat architecture, native services from a global storage pool, and granular-level automation to simplify management.
In a recent economic value study conducted by the Enterprise Strategy Group (ESG), the FlashArray unified platform was shown to reduce management effort by 62%, resulting in a 58% reduction in TCO. With savings like that, isn’t it time to move to truly unified?
Learn more about how a truly unified block and file platform can help you.
Free Test Drive
Try FlashArray
Explore our unified block and file storage platform.

The Clear Choice
Learn more about the first truly unified block and file platform.



