


As engineers, we all know the value of good testing. And we all want fast, deterministic tests. But how can you, as an engineer, architect your code to be testable?
Something that attracted me to Pure Storage®—and that I often talk with candidates about—is the sense of ownership that Pure developers feel about their code. Customer experience isn’t just the realm of product management. All of us—from engineers to account executives—consider it.
Part of this means robustness, including thorough tests, even before we hand our software images off to the System Test team. Tests shouldn’t be an afterthought—they should be part of the development process as an inherent element of how we architect code.
So, how do we do that? Maybe more interestingly, how do we do it without sacrificing developer velocity?
I’ll walk you through an example of a distributed system integration test and point out principles that can be applied elsewhere. This test runs in between 7 and 30 seconds, but almost all runs take fewer than 15 seconds. Because it can run on any Linux machine, most people invoke it remotely from their laptop. No fancy simulators or hardware required!
(As a comparison benchmark on speed, a similar end-to-end test using simulated hardware takes more than 20 minutes.)
What Do We Test?
I work on the FlashBlade® product, a distributed file and object storage system that scales out using blades—between 7 and 150—for performance and capacity.
We store various pieces of information in an open-source distributed database called etcd. And we’re certainly not the only ones: etcd is used extensively in distributed systems (underpins Kubernetes, for instance). A small subset of blades in a FlashBlade can be used to form an etcd cluster. As blades on the FlashBlade change, the nodes running etcd must also change. An etcd manager process orchestrates these changes, monitors etcd health, coordinates etcd binary upgrades, and more. This manager communicates with the blades via gRPC, instructing them to store an etcd configuration file and to start and stop the etcd process as needed.
How the Test Works
I’ll take you through a test of etcd management on FlashBlade, including the etcd manager process, code running on the blades, and how etcd clusters are formed and reformed.
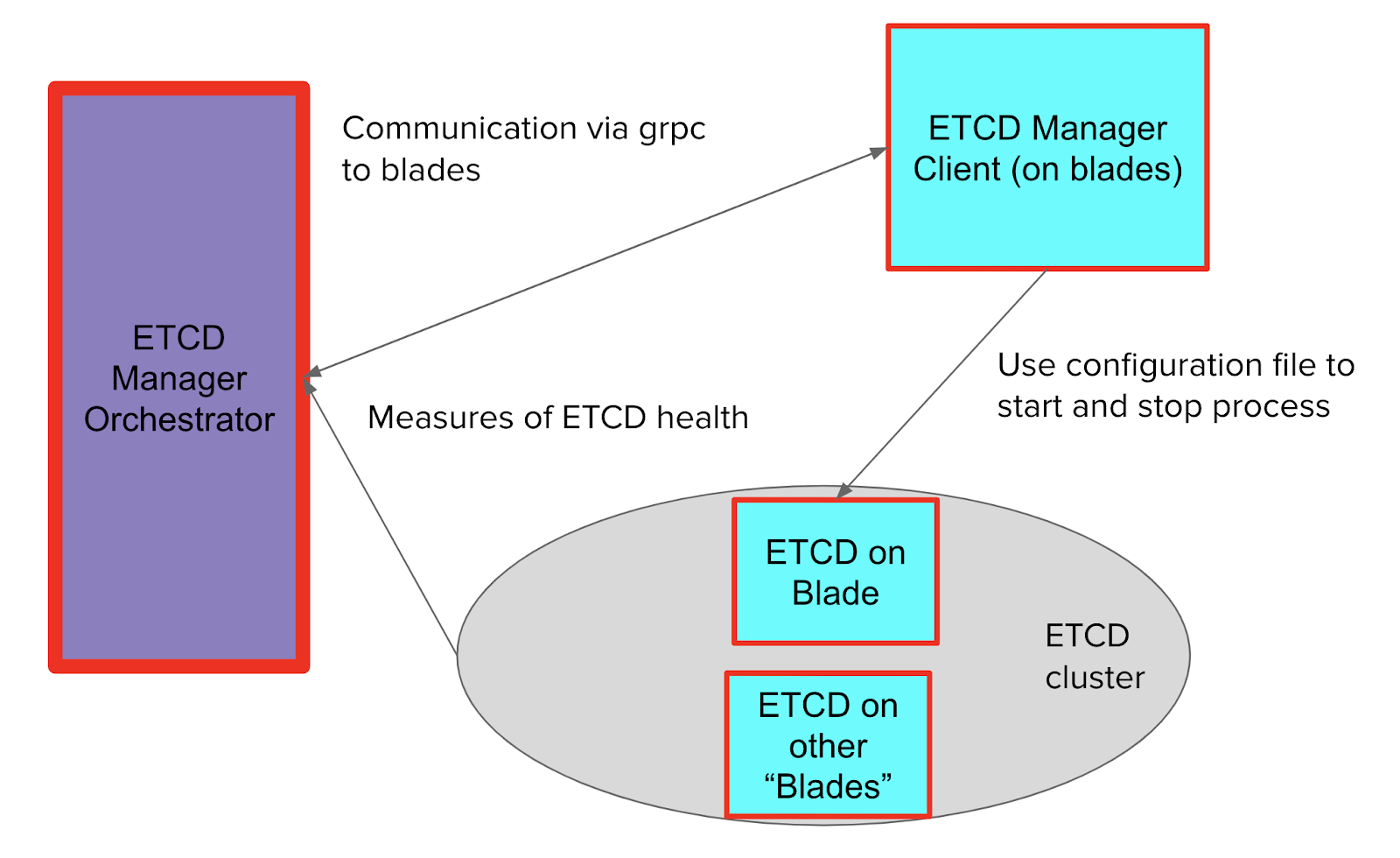
Figure 1: Communication process between etcd manager, blades, and etcd cluster.
The test involves several software and hardware processes communicating over the network, some of which come and go. It also underpins our system: Without etcd, FlashBlade will not work. How do we test this quickly without sacrificing thoroughness?
Let’s zoom out from the problem for a moment and talk about testing. This may be obvious to some people, but it’s always good to level set.
Tests often fall into three buckets: unit, integration, and end-to-end. People have different definitions for these. Here are mine:
- Unit tests test a single function or API
- Integration tests are:
- Not localized to one component, and/or
- For a workflow rather than just a part of a workflow, and/or
- For crossing seams between layers
- End-to-end tests test the entirety of a feature
In this post, I’m focusing on integration tests that do not require real hardware, simulated hardware, or spinning up containers. This isn’t a requirement for an integration test, but it’s a nice property to have for deterministic testing and developer velocity.
Why Integration Tests?
Let’s compare the three types of tests:
- Unit tests
-
- Pros: Great for verifying a single process, API, etc., at a high level of detail. Fast and can run nearly anywhere.
- Cons: Not great for testing multiple component interactions or catching unknown unknowns.
-
- Integration tests:
-
-
- Pros: Fast and can run anywhere. Can get at subtle interactions and situations that are hard to capture in unit and end-to-end tests.
- Cons: Not an end-to-end test. There will still be mocked components and pieces that are hard to test in integration tests.
-
- End-to-end tests:
-
-
- Pros: Can verify an entire product, process, etc.; works end-to-end.
- Cons: Expensive and often slow. Can be hard to debug or identify the “real issue.” Sometimes hard to get at subtle “few component interactions,” especially for internal components.
-
How did we do it? Using dependency injection.
Using Dependency Injection
From Wikipedia: Dependency injection is a technique in which an object receives other objects that it depends on. These other objects are called dependencies… Instead of the client specifying which service it will use, the injector tells the client what service to use. The “injection” refers to the passing of a dependency (a service) into the object (a client) that would use it.
Essentially, dependency injection (DI) means you’re using “Object A” to provide the dependencies of “Object B.” It means transferring the task of creating an object to “something else” at a higher layer, often ultimately a main or test function. (For those who are Spring Boot familiar, Dependency Injection does not always mean “@autowired,” although that is one way of doing it.)
Some Examples
Standard Method:
In my code:
Now, any test that wants to test the use of object in someFunction has to wait five years. This is not very testable code.
Using DI:
someFunction() looks exactly the same as in our previous example. However, when we go to test this code, we can write something like this:
Since we can inject a clock, we can inject a NoSleepClock, which, rather than sleep for five years, will “skip” sleeps in execution (Yes, sleeping five years is a bit of a campy example.)
Let’s walk through another example.
Standard Method:
In production, this makes complete sense. We spin up a new SomethingService on our FlashBlade, which has a server listening on a default port. Maybe each blade has a SomethingService listening on the same default port.
What happens when we test this? Since our port is locked up, we can’t spin up multiple SomethingServices without containers or real/simulated hardware. Consider instead:
Using DI:
This way, testing a single VM could have multiple instances of SomethingService with different gRPC servers. Since the port is injected, we don’t have to use a default port. We can instead use multiple ports on the same machine.
DI provides:
- Modularized code
- Easy mockability
- Separation of “business logic” and “environment”
- Interrogation of assumptions made by a function or object
Recognizing Dependencies
Could it be a tunable? Then, it might be a dependency. Is it part of an object constructor? Does the function initialize it?
- Commonly: Config, Time, Network, Filesystem
Limitations and Alternatives:
Keep in mind that DI is not a silver bullet. It can lead to:
- Unnecessary complexity:
- Otherwise unneeded interfaces, boilerplate
- Opaque code
- Codebase learning curve
- Shoving dependencies up the stack can lead to sprawling main functions
Some alternatives to consider: python magic mocks; locator patterns, which describe how to register and locate services; “test modes” with different business logic; and formal verification.
Back to etcd Manager
On FlashBlade, etcd manager automates the management of etcd on the blades with the primary goal of maintaining a healthy online cluster. It migrates the cluster between blades, coordinates binary upgrades, and does a few other things.
The manager runs on the leader fabric module. Our test spins up one etcd manager and assumes it’s the leader. The manager communicates via gRPC to the blades, and each blade stores a “cluster_conf.json” file with the desired etcd configuration.
How does our integration test for the etcd manager work?
First:
- Test sets up N “mock blades” capable of running etcd and serving RPCs.
- Test sets up one mock manager capable of communicating via gRPCrpc.
- Test tells etcd manager: “N-1 is your desired size.”
Then:
- etcd manager creates a stable, healthy cluster of size N-1.
- The test verifies this has happened.
Next:
- Test “takes down” a mock blade.
Finally:
- Test validates etcd manager, adds the Nth blade, and the cluster continues to be stable and healthy.
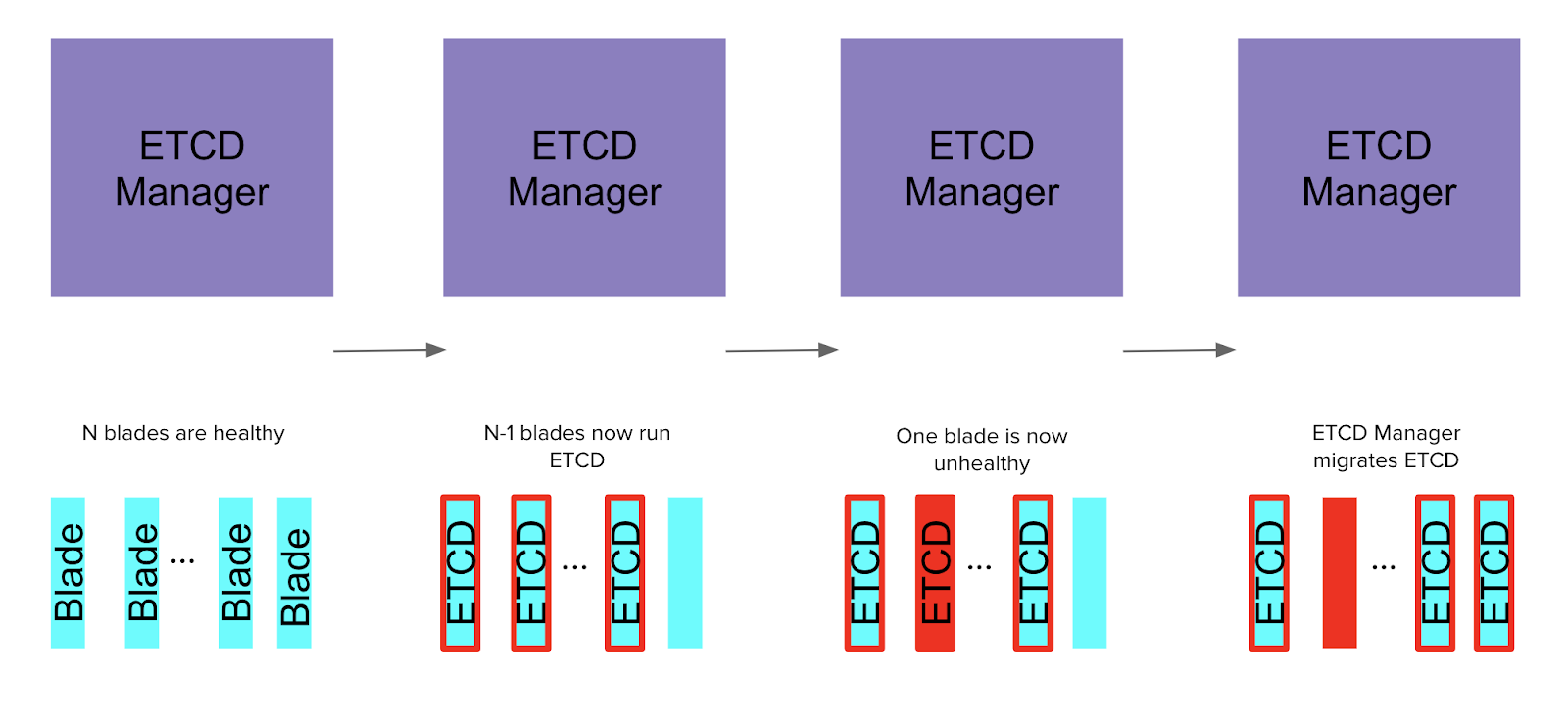
Figure 2: Integration test with the etcd manager.
Let’s walk through each part of this.
The test sets up N “mock blades” and one mock-manager:
- Mock components use a real gRPC server
- Ports are injected as a dependency → mockable
- Mock blades run a real instance of the etcd process
- Communication between blade and etcd is injected as a dependency → mockable
- etcd ports and other configuration are injected → mockable
- Command line interface to read configuration is injected → mockable
- Process management layer is injected → mockable
- Test tells etcd manager: “N-1 is your desired size”
- “Target size” for an etcd cluster is injected to the etcd manager
- Test “takes down” a mock blade
- Cross component communication is injected → disrupting communication mimics taking down a blade
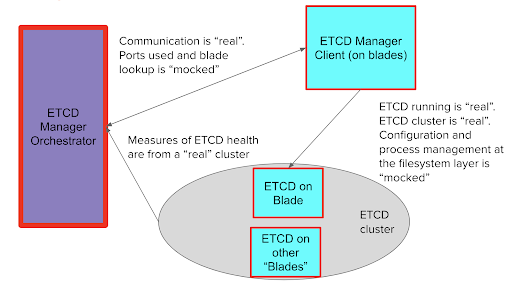
Figure 3: Test process using the etcd manager and a mock-manager.
I’ll also call out that the process of writing our test greatly improved our code. I don’t have a change or bug count, but we fixed several issues and streamlined the code from writing it. Hopefully, you can benefit from what we learned and do the same.
Thanks to my teammates, especially Kevin Chau and Tyler Power, for their help with this blog post.

Simple Scalability
cale capacity and performance easily with the industry’s most advanced unified file and object solution.



