


This article originally appeared on Medium.com. It has been republished with permission from the author.
In this post, I look at what it takes to list all keys in a single bucket with 67 billion objects and build a simple list benchmark program in Golang. This parallelized program is able to list keys at a rate of 430k per second using a small FlashBlade as the S3 backend.
67 billion objects may sound like an unreasonably high number. It is always possible to build applications to create fewer objects by coalescing and aggregating data. But sometimes re-architecting an application after being deployed in production for years of organic growth is challenging. The easier option is to simply grow the object count as the application grows with the confidence that things will continue to work.
Increasing numbers of objects impacts the runtime of a LIST operation most as it needs to traverse large ranges of objects in lexicographical order. Applications often avoid listing large numbers of objects, but even in these cases, listings can be useful for ad hoc debugging and space reporting.
Object stores have been built to be far more scalable than traditional filesystems. Scaling to massive numbers of objects requires a scale-out storage backend like FlashBlade as well as concurrent client applications. Listing 67 billion objects is a client-side challenge, i.e., how to get the concurrency and performance in the application to get the most out of the FlashBlade. The rest of this article examines the importance of concurrency to dramatically speed up the listing operation by leveraging a uniform distribution of key prefixes in my test bucket.
In the rest of this post, I first check that listing objects scales linearly as bucket size grows in order to build confidence in extrapolating time estimates. Second, I develop parallelized list benchmarks in Python and Golang, measuring their relative performance on a small bucket. And finally, I run the parallelized list benchmarks on the full bucket.
How to Build this Dataset
As part of a test application, the data consists of 67 billion small objects with an average size of six bytes. The application uses randomly generated strings as keys and tracks the keys separately, effectively using the FlashBlade S3 backend as a key value store.
For this particular size of FlashBlade, the dataset creation proceeds at up to 21k objects created per second, all while keeping the PUT latency under 4ms, as shown in the screenshot below.
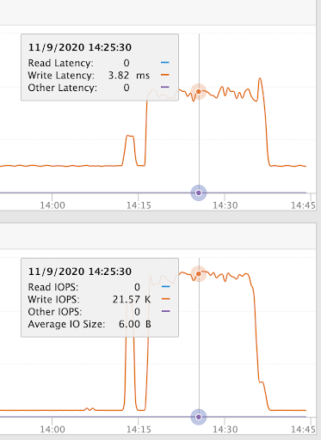
To create this size of dataset, we would need to write continuously at this rate for ~40 days. In reality, the data was created at a lower rate over a year-long period. The PUT operations average 1k per second and have latency averaging 1.02ms, which is the same latency as when PUTing objects in an empty bucket.
Note that just creating this many objects is very expensive with request-based billing. For AWS S3 standard tier, there is a cost of $0.005 per 1000 PUTs, meaning that it would cost $335k just to create the dataset and then another $27k to read the entire dataset once ($0.0004 per 1000 GETs). These per-request charges add on to the standard capacity charges ($/TB/mo). With FlashBlade, you only pay for the capacity used and do not have these per-request fees, making it far cheaper even if ONLY considering the cost of PUT operations.
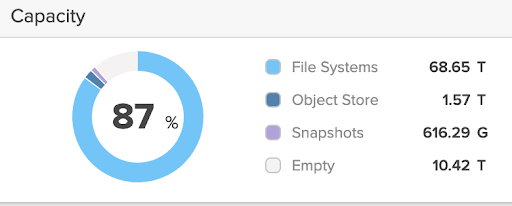
This FlashBlade is primarily used for a variety of software development needs such as test automation and debugging. The system has been running production workloads for four+ years at over 80% capacity, almost all of which (~70 TB) is used by filesystem data.
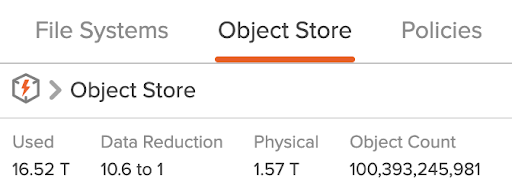
The specific bucket I list here is the largest bucket on this FlashBlade, though the total number of objects is 100 billion.
The rest of this post charts the steps I took to list all objects in my large bucket with 67 billion objects.
Linear Scaling of Lists at Small Scales
First, I will use S5cmd to verify that the FlashBlade handles LIST operations with linear scalability at small scales in order to extrapolate the time to list the full bucket. If LIST times do not scale linearly as the bucket grows in size, there is little hope of ever listing the large bucket! S5cmd is a performant and concurrent golang-based S3 client which can be easily connected to a non-AWS object store like FlashBlade.
All standard S3 clients like s5cmd and most custom applications execute a LIST operation serially. The application requests each subsequent page of keys, normally 1000 keys, per request using a continuation token to inform the server where it left off. The server may be able to parallelize some work, but by default the client only issues one request at a time.
For this test, I measured the response time of “s5cmd list” as the number of objects in a bucket increases. As shown in the graph, the response time scales linearly, with 100 million objects the largest tested in this initial experiment.
The test can be done by pointing the endpoint-url to a FlashBlade data VIP:
s5cmd --endpoint-url https://10.62.116.100 ls s3://mybucket/* | wc -l
The graph below shows results up to 100 million objects.
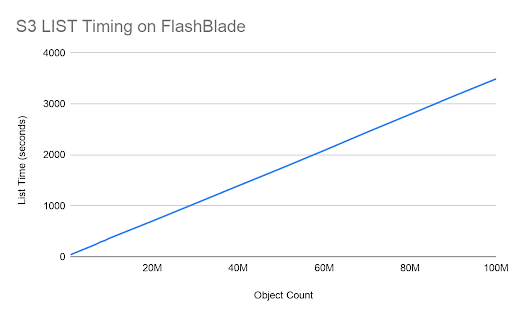
List timing increases linearly with bucket size as hoped. Listing 100M objects took nearly 1 hour. Assuming both the client and server continue scaling linearly, it would take approximately 28 days to list all 67 billion keys in the large bucket. But the FlashBlade was mostly idle in the above tests, suggesting that it can handle more requests in parallel.
Parallelized Client Code
Instead of relying on serial listing, in many cases it is possible to perform list operations in parallel. The key requirement is that the work can be divided, for example by key prefix.
In the case of this dataset, the keys are randomly generated strings, meaning that one way to parallelize the list operation is to concurrently list keys with prefix ‘a’, ‘b’, ‘c’, et al.
This method will not work as well with datasets that have keys used like a filesystem folder structure.
I created two versions of a benchmark list program, first in Python and then again in Go once it was clear that python itself became the bottleneck. The benchmark itself does nothing but count keys, but can easily be improved to perform useful functions, for example space reporting by object age or key suffix.
Python
The full source code for my python list benchmark can be found here.
The Python code leverages S3 paginators to simplify the process of listing large numbers of keys. To parallelize the code, I use asyncio and ProcessPoolExecutor to concurrently list each key prefix in range [a-z]. Generally, parallel programming in Python is challenging because of CPU bottlenecks on the Python global interpreter lock (GIL), but IO-bound workloads like this can still benefit from concurrency.
Listing all keys starting with a prefix looks like this:
s3 = boto3.client('s3', use_ssl=False,
endpoint_url='https://' + FB_DATAVIP)
kwargs = {'Bucket' : bucketname, 'Prefix': prefix}
paginator = s3.get_paginator("list_objects_v2")
count = 0
for page in paginator.paginate(**kwargs):
… work…
Golang
The full source code for the golang list benchmark can be found here.
Based on evidence that the Python program was the bottleneck, I rewrote the same benchmark in Golang, a compiled and natively-concurrent language. This was only my second small Golang program, so presumably can be further improved by a more experienced developer.
Create an S3 connection to FlashBlade as follows, using the data VIP for the Endpoint, which I have clumsily hard-coded:
s3Config := &aws.Config{
Endpoint: aws.String("https://10.62.116.100"),
Region: aws.String("us-east-1"),
DisableSSL: aws.Bool(true),
S3ForcePathStyle: aws.Bool(true),
}
sess := session.Must(session.NewSession(s3Config))
svc := s3.New(sess)
You then list keys starting with a prefix as follows:
count := 0
err := svc.ListObjectsPages(&s3.ListObjectsInput{
Bucket: bucketname,
Prefix: &pfix,
}, func(p *s3.ListObjectsOutput, _ bool) (shouldContinue bool) {
count += len(p.Contents)
return true
})
Finally, I use a simple channel and go routines to execute the listings in parallel.
Comparing Implementations, Small Scale
Before testing on the full bucket with 67 billion objects, I ran validation tests on a much smaller bucket with 2 million objects to validate that a parallelized client will indeed result in faster listings. The client for all tests is a single server with 40-cores (Xeon E5–2660 v3 @ 2.60GHz) and 192GB of memory.
Both Python and Golang parallel implementations were approximately 24x faster than the serial versions, suggesting that this consistent speedup comes from better leveraging the server’s 40 CPU cores. The graph below illustrates the 24x speedups from parallelizing the list process, as well as the 3.3x speedup of Golang relative to Python.
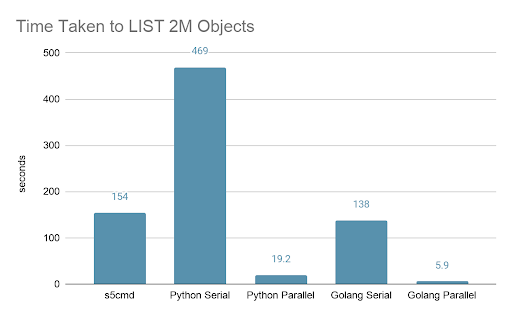
S5cmd is included in the chart and is directly comparable to the Golang serial benchmark; though s5cmd can issue operations in parallel, it will list keys serially by default.
Listing 67 Billion Objects
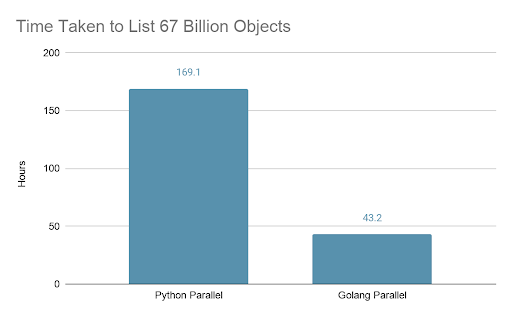
Finally, the moment of truth. I ran the parallelized Python and Golang list benchmarks on the full bucket with 67 billion objects. The Python version took 169 hours (~7 days) and the Golang version took 43 hours.
Python parallel runtime
$ time ./s3-rapid-list.py mybucket
66880635288
real 10148m6.915s
user 299745m42.624s
sys 6062m19.940s
Golang parallel runtime
$ time ./run-go.sh mybucket
Count 66880635288
real 2593m2.901s
user 0m13.712s
sys 0m0.940s
Based on the results on a smaller bucket, the Golang version was 3.25x faster than Python and this performance difference grew to 3.93x faster on the larger bucket. In fact, the 430k keys/sec list speed of the parallel Golang benchmark is significantly higher than the measured speed of 340k keys/sec on the smaller bucket. This suggests that six seconds to list the 2 million objects includes a large fraction of overhead, e.g. TCP connection establishment.
I also tested parallelizing the Golang version across multiple nodes, but did not get any speed improvement, suggesting that the single server version is able to saturate this small 15-blade FlashBlade.
1. Enhanced Object Storage Capabilities:
- Purity//FB 4.4.2 Enhancements: In July 2024, Pure Storage released Purity//FB 4.4.2, introducing significant improvements to object storage functionalities. Key features include:
- Active-Active Object Replication: Simplifies deployment and enhances data availability by allowing simultaneous data access across multiple locations.Object Expiry and Bucket Deletion: Facilitates efficient space recovery by enabling automated management of object lifecycles.
2. Best Practices for Optimizing Object Listing Performance:
- Parallelization Strategies: To efficiently list a vast number of objects, implement parallel processing by dividing the key namespace and assigning segments to multiple concurrent tasks. This approach reduces overall listing time and maximizes resource utilization.
- Prefix Design: Design object keys with appropriate prefixes to facilitate efficient querying and retrieval. A well-structured prefix schema can significantly enhance listing performance.
- Use of Byte-Range Fetches: When dealing with large objects, utilize byte-range fetches to retrieve only the necessary portions of data. This method reduces data transfer overhead and improves application performance.
3. Leveraging AWS S3 Features:
- S3 Select: Utilize S3 Select to retrieve specific data subsets from objects, reducing the amount of data transferred and accelerating query performance.
- Lifecycle Policies: Implement lifecycle policies to manage object transitions between storage classes and automate deletions, optimizing storage costs and performance.
Conclusion
By adopting these updated practices and leveraging the latest features in Pure Storage’s Purity//FB 4.4.2, organizations can enhance the efficiency and performance of large-scale object listings, ensuring scalable and effective data management.
Understanding bottlenecks in applications often requires finding points of serialization and adding concurrency. Moving from Python to a compiled and natively-concurrent language like Golang brings two key advantages: better CPU utilization and ease of writing parallel code.
No special tuning or settings on the FlashBlade were needed for these tests, but the benchmarking did not go completely smoothly. After the first run of the parallelized python script, we noticed periodic latency increases that pointed to optimization opportunities in the internals of the FlashBlade metadata management systems.
The FlashBlade supports storing and accessing 100s of billions of objects in practice, and will be much more cost-efficient at this scale than per-request object stores like AWS. Applications and client tools need to be carefully thought through to take advantage of that extreme scalability. Building concurrency for all operations, including GETs, PUTs, DELETEs, and LISTs, enables applications to use the full performance of FlashBlade.

How Storage Plays a Role in Optimizing Database Environments




