


How easy is it to access your AI infrastructure? Pure Storage has partnered with Lablup to make on-premises AI accessible and fast.
Lablup’s Backend.AI is an open-source computing resource orchestrator designed for AI/ML that makes AI easier to access for data scientists. By adding Pure Storage® FlashBlade®, the Backend.AI architecture delivers data as a service with simplicity and speed.
Let’s say that your company buys several new powerful GPU servers. You and your fellow data scientists are excited because you don’t have to wait for your training jobs to complete on your laptop anymore. You want to use the GPUs immediately, but it might not be that simple.
Your IT team may ask you a few questions before you can access the GPUs, such as:
- How many CPU and GPU resources do you need?
- What’s the estimated start and finish time?
- Do you need shared storage and how big should it be?
- How big are your data sets and how are you going to upload them?
And this may happen every time anyone on the team wants to use the GPUs.
Making AI accessible has never been easy. AI is such a broad range of technologies. It’s far beyond just writing some Python code to train machine learning models. Building and operating an end-to-end AI infrastructure and system isn’t easy, even for big enterprises.
As described in this paper on hidden technical debt, the infrastructure required to support real-world ML systems is vast and complex. The ML code is only a small part of the system as you can see in the diagram below.
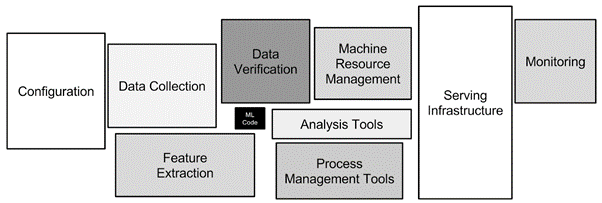
Figure 1: The infrastructure required to support ML systems. Source: Hidden Technical Debt in Machine Learning Systems
For now, let’s just focus on the small box—the ML code part. It’s still very different from traditional software development because we use GPUs or TPUs for model training. GPUs and TPUs are expensive. They require additional setup of drivers and libraries.
How do you share and schedule GPUs for your team? I’ve heard that people use third-party tools, scripts built in-house, or even a spreadsheet, which is obviously not that “intelligent.”
Making AI Accessible
A lot of companies start adopting AI by hiring data scientists and equipping them with laptops with one GPU card. This may be OK at first, but once the team starts working on larger data sets and models, they’ll need more GPUs. And more GPU servers will be needed in the data center or cloud.
This is where the infrastructure challenges start. Not every company is good at managing GPU resources. Backend.AI is trying to solve this problem by making GPUs, or computing resources in general, easy to access and share among data scientists. It handles the complexity of managing and sharing GPUs so that the data scientists can focus on building better models. It abstracts GPU resources across many servers as a computing pool, which can be allocated to different computing sessions on demand from a simple UI.
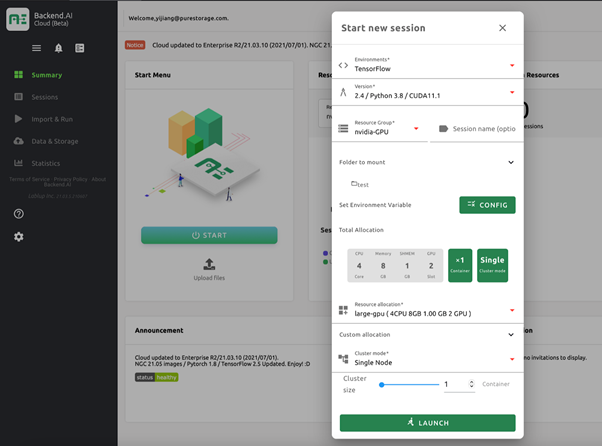
Figure 2: Starting a new session on Backend.AI.
A new session can run on a single GPU, multiple GPUs, or even a portion of a GPU, which is useful for small model training and inference. With a couple of clicks, you can launch a GPU-enabled session with your favorite ML frameworks from your browser without having to install anything. No GPU driver, no libraries, and no frameworks.
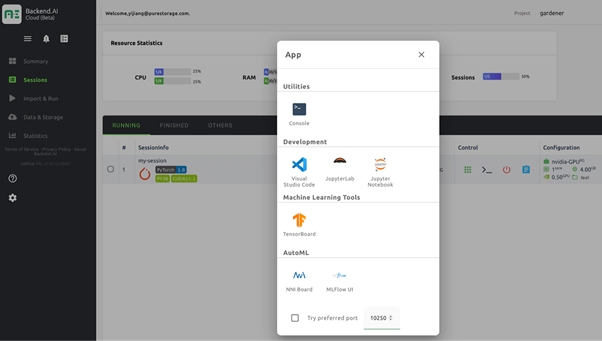
Figure 3: One-click launch of various tools from Backend.AI.
Backend.AI also supports launching commonly used ML tools from the browser. I use Jupyter a lot. I click the button to start a JupyterLab instance. From there, I can start writing my ML code immediately.
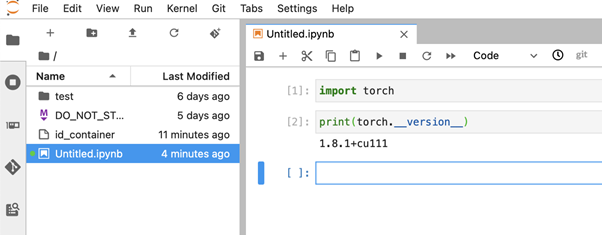
Figure 4: Launching a JupyterLab instance in Backend.AI.
You can also start a terminal within the session with one click. The CLI, running in the browser, gives you flexibility and more control over the session.
Figure 5: Web-based CLI from Backend.AI.
Since your session environment is isolated from those of your teammates, you don’t need to worry about conflicting sessions or resource competition. Once the training job is done, you can save your model and shut down the session. Then, the GPU resources will return to the pool.
Backend.AI makes AI accessible. You don’t need to install anything or ask the IT team for a GPU environment. You can just click and go whether you have a single GPU or multiple GPUs. Backend.AI offers GPU resource consumption as a service—something every data scientist can benefit from.
How Does Backend.AI Work?
At a high level, Backend.AI works like many server-client systems. Clients are the SDKs and libraries that initiate requests to the server-side components. Most of the magic happens at the server, but for the client side, it integrates with Visual Studio Code (VS Code). I use VS Code for almost everything, including coding and taking notes. Being able to write and debug my models and scale to many GPUs in a single VS Code environment is very convenient and powerful.
There are multiple components on the server side, including the Manager with API Gateway for routing API requests, Agent for executing requests and running containers, and Kernels for running commands/code in various programming languages and configurations.

Figure 6: Example Backend.AI architecture.
Does this architecture look familiar? When I first saw it, I wondered what the difference was between Backend.AI and the Docker + NGC + Kubernetes stack. There are several key differentiators. Backend.AI:
- Doesn’t require Compared to Kubernetes-based solutions (which are still difficult for many companies), Backend.AI simplifies access to the cluster.
- Is optimized for running HPC and AI workloads. Better container-level isolation and virtualization of multitenant workloads on high-end/high-density nodes make it easier to maximize GPU utilization. In contrast, Kubernetes is more focused on running microservices with a herd of small-sized nodes and keeping up the desired deployment states.
- Offers better performance because of the HPC/AI-optimized design such as topology-aware resource assignment.
- Comes with fractional GPU scaling to extract the last drop of GPU performance by allocating dedicated fractions of GPUs to individual containers, without modifying existing CUDA programs and libraries.
- Provides native integration with storage filesystems, which enables higher I/O and data management performance using filesystem/storage-specific acceleration features.
- Supports using Kubernetes clusters as a back-end computing node (currently in the beta state).
Storage Integration
An AI system is data plus code (models). Backend.AI supports seamless integration with various network-attached storage (NAS) products. Backend.AI includes a storage proxy component that provisions the volume from NAS and presents it as a virtual folder (vfolder) to a session. While NAS is typically slower than direct-attached SSDs in the GPU server, we need vfolder because it’s persistent across sessions. As a result, we don’t lose data when shutting down the session.
Pure FlashBlade NFS is the recommended NAS for on-premises Backend.AI. With FlashBlade NFS integration, you can leverage the fast performance of all-flash storage and the Rapidfile Toolkit to supercharge your AI workloads. In addition, FlashBlade I/O stats, CPU/GPU utilization, and other stats are also available on the Backend.AI UI. This makes it easy to understand system stats at a single glance.

Figure 7: FlashBlade integration and monitoring on Backend.AI.
For many data scientists, storage might be the least exciting thing in the AI/ML stack, but it’s a critical part. Having simple, reliable, and fast NAS in the stack is essential. FlashBlade:
- Is easy to use and manage
- Is designed with high resiliency and protection
- Delivers high throughput with consistent low latency and linear scalability
I don’t like to compare the Gbps different NAS products deliver because it’s often just a marketing message. For AI/ML workloads, the NAS needs to be at least as fast as the GPUs can process the data because otherwise, the expensive GPUs will be doing nothing but waiting for data to come in. NAS delivering 80Gbps doesn’t make sense if your GPUs can only process 4Gbps in the training job. Although, you do need 4Gbps from the NAS to saturate the GPUs.
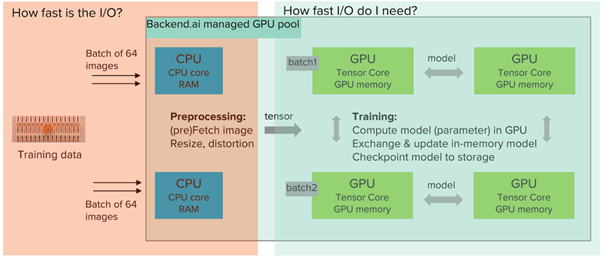
Figure 8: Typical data path in machine learning.
Once the NAS can deliver the minimum required throughput, it’s the simplicity, resilience, and functionality that matter.
An ML data set could have millions of files. What do you do the first time you decompress the data set? Most likely, you change permissions or collect file statistics. You run some Linux commands like chmod or find. It could take many minutes or even hours to finish not because the NAS is slow but because of the way these Linux commands work. Because they operate the files one by one in sequence, it can take a long time to operate millions of files.
Accelerate File Operations with Rapidfile Toolkit
Rapidfile Toolkit is a software package provided by Pure to accelerate common Linux file operations by up to 30x. Once installed, it provides a set of “p-commands” for its Linux counterparts, for example, pfind and pls for find and ls, respectively. The p-commands improve traditional Linux commands by operating files in parallel. So instead of changing permissions one file at a time, it sends many requests in multiple threads to the NAS, changing multiple files permissions at once.
In a test with 1.2 million files stored on FlashBlade NFS, we found that Rapidfile Toolkit was around 30 times faster than its Linux counterpart for the most common commands.

Figure 9: Rapidfile Toolkit vs. traditional Linux commands in time taken to operate 1.2M files.
Summary: Lablup and Pure Storage
AI is gaining traction and expectations are high. Yet companies and governments are still struggling to build their AI infrastructure. Managing and sharing GPU resources and data is one of the first challenges that needs to be addressed. Lablup Inc.’s Backend.AI enables consumption of GPU as a service. Pure Storage FlashBlade delivers data as a service with simplicity and speed. Together, they make AI accessible and can help you achieve your AI initiatives.
![]()



