



So you do find yourself wondering, did it actually reclaim anything? Besides looking at the array and seeing space reclaimed, how can I see from ESXi if my space was reclaimed?
Making sure it is enabled
Well first there are two settings that matter.
First is your VMFS-6 datastore configured for automatic UNMAP?
This can be seen in the GUI:

Or set through the CLI (or API/PowerCLI etc):
|
1 |
esxcli storage vmfs reclaim config set –l <datastore name> –p <none|low> |
The options for this are only none or low today. Yes the CLI reports medium and high, but the are disabled in the code, setting it to those will do nothing differently then “low”.
The next thing is, is your host(s) enabled to participate in automatic UNMAP?
The way automatic UNMAP works is that all ESXi 6.5 hosts that see the VMFS-6 datastore participate in the UNMAP process. They have crawlers that will run UNMAP to the various datastores intermittently. They will issue it to the dead space and dead space only. Once one host has issued UNMAP to certain regions on a datastore, no other host will then redundantly issue UNMAP to those locations unless it is written to again and then made dead again (by deleting or moving the data).
By default, all hosts are enabled to participate. But a host can be disabled from participating in automatic UNMAP. This setting is rather hidden, so frankly, do not disable this unless through the direction of VMware support.
It can be found in the CLI (or API):
/vmfs3/EnableVMFS6Unmap
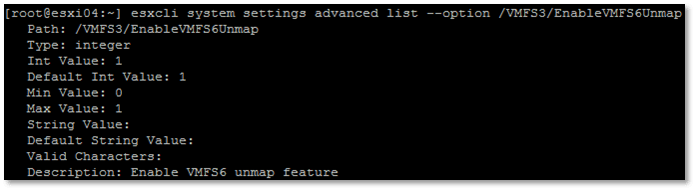
If this is set to 1, that host is set to participate in automatic UNMAP.
Monitoring Automatic UNMAP
So how do you see if it has run UNMAP? Well the traditional method has always been esxtop. SSH into the ESXi host, type “esxtop” then enter and then type “u” then “f” then select VAAI statistics with “o”.
On the far right, you will see delete stats, aka UNMAP:
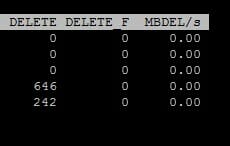
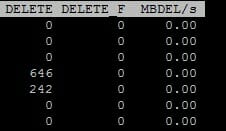
DELETE is a counter for UNMAP commands issued to that device, from that host since the last reboot. DELETE_F is a counter for failed UNMAP commands issued to that device, from that host since the last reboot. Note that this isn’t like how many times someone ran the UNMAP command. It is literally a count of UNMAP I/Os. A single UNMAP operation could include thousands of UNMAP commands.
The last column is not a counter, but instead a indicator of the throughput of any UNMAP operations going on right now from that host to that device. So if no UNMAP operations are running right now, it will be zero.
So we have known about this for years, what changes with async automatic UNMAP?
Well this reports on ALL UNMAPs to that device, whether manual or automatic. There is another counter that lists just automatic UNMAP commands issued.
It is with a tool in ESXi called vsish.
***Before moving on, do not make environmental changes with vsish unless directed by VMware support as noted by William Lam here. Querying information like below is fine though.
SSH into your ESXi host and type “vsish” and then enter.
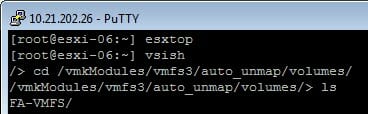
If you CD into /vmkModules/vmfs3/auto_unmap/volumes/ you can then type “ls” to see the volumes.
This will show you all of the VMFS-6 datastores which that specific host has at least one powered-on VM on. If that host does not have any powered-on VMs on that datastore, that datastore will not be listed here.
In other words, this list here is the selection of datastores which that ESXi host is currently monitoring to run asynchronous automatic UNMAP.
Okay cool. Now if you run a get on the properties of that datastore, you will see some information. The command is
|
1 |
get /vmkModules/vmfs3/auto_unmap/volumes/<datastore name>/properties |
So enter in your datastore name and run it.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
/vmkModules/vmfs3/auto_unmap/volumes/> <strong>get /vmkModules/vmfs3/auto_unmap/volumes/FA–VMFS/properties</strong> Volume specific unmap information { Volume Name :FA–VMFS FS Major Version :24 Metadata Alignment :4096 Allocation Unit/Blocksize :1048576 Unmap granularity in File :1048576 <strong> Volume: Unmap IOs :646</strong> Volume: Unmapped blocks :41078 Volume: Num wait cycles :0 Volume: Num from scanning :878 Volume: Num from heap pool :61 Volume: Total num cycles :8513 } |
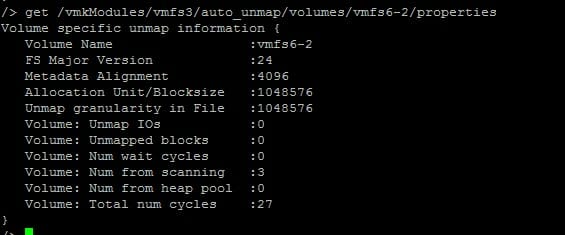
There is one important metric to note here. “Unmap I/Os”. This tells you how many UNMAP I/Os this host has sent to this datastore since that host was last rebooted.
VSISH vs. ESXTOP
So how are these two different. Let’s run a test.
First I have a new datastore and both vsish and esxtop report zero UNMAPs.
ESXTOP shows zero (it is the bottom row)
VSISH shows zero:
Now I kick off a process that will initiate an automatic UNMAP operation (using the process in this post)
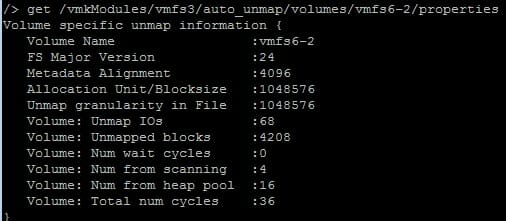
After a few minutes both esxtop and vsish report the same values (68 UNMAPS).
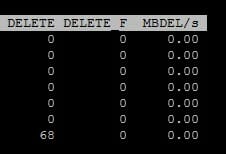
So what if I run a manual UNMAP?

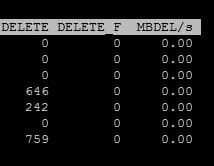
Well esxtop shows a ton more UNMAPs. This makes sense as it blindly issues UNMAP to the entire free capacity of the datastore, not just small segments like automatic UNMAP does.
VSISH is unchanged at 68:
So for a true count of automatic UNMAPs being issued to a datastore from a given host, vsish is the way to go.
Caveats
Okay so this all very interesting but there are two very important caveats:
- Both vsish and esxtop counters are reset upon ESXi reboot
- Vsish counters are reset if the datastore goes unmonitored. So if you had a running VM on a datastore it would be monitored and UNMAPPED by that host. But if you power that off or move it to another host and it was the last VM on that host for that datastore, that datastore becomes unmonitored by that host and the counters reset to 0.
So I think the point is, really for the source of truth, look at your array to see if space is being reclaimed. Resort to these counters on your various hosts only if needed. In general, just check these counters to see if they are indeed issuing UNMAP, if they are all zero something is up.
Written By:
ESXi Host Configuration
Learn the recommended configuration of ESXi hosts for use with the Pure Storage FlashArray.



