SAP HANA® column tables have a property called Paged Attribute. With this property, the loading behavior of the table changes and it can be loaded page by page. If Paged attribute property is activated on a table, SAP HANA does not have to load all of the data into memory when queried. It will only load the data that is in the area in which the query is searching. The new partitions in a table are handled according to the loading behavior of the partitions currently in this table. Here in such scenario the read performance of storage really matters.
Unloading of column tables happens quite a lot and it can slow down queries drastically. But not on Pure Storage FlashArray//X. In this blog, I am going to show how can really performant storage like Pure Storage FlashArray//X can improve the load/unloading of pages of column tables.
Pure Storage FlashArray//X is an enterprise-class, all-NVMe & NVMe-oF flash storage array. Pure Storage FlashArray//X is certified (Tailored Datacenter Integration (TDI)) by SAP as an enterprise storage solution for the SAP HANA platform. FlashArray//X is next-generation all-flash storage. Designed for the cloud era, //X delivers the highest performance and enterprise reliability for Tier 1 applications.
In order to test the query performance of SAP HANA column tables with Paged Attribute:
- I have created a column table with range partitioning and of table width 500 Bytes.
- This table was delta merged before unloading from memory
- The load into memory and unload from memory (manually) was used for testing.
- This table was scaled from 75 million records to 450 million records.
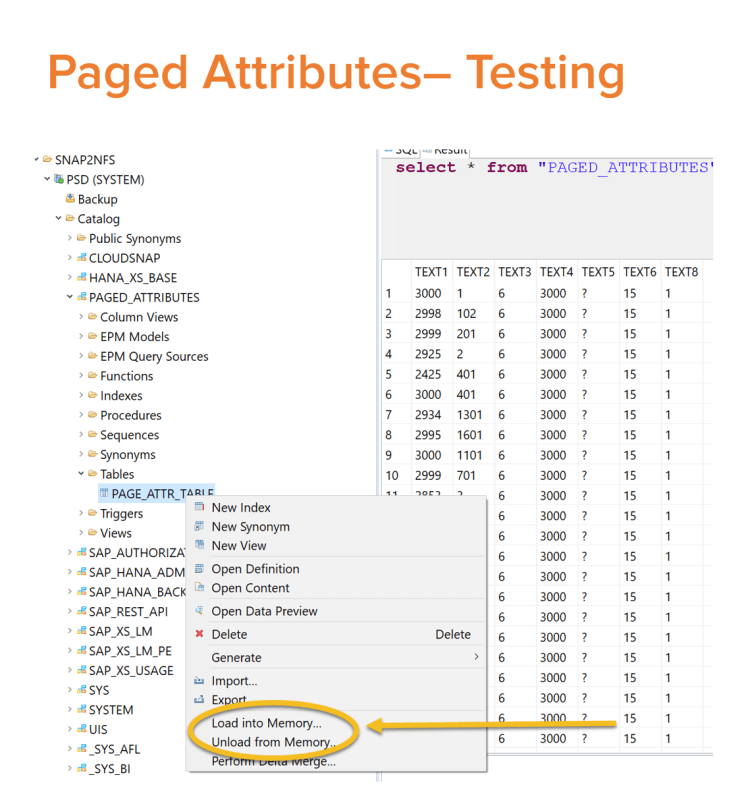
Firstly the table was loaded with data and “select * from table” query was run after the table was delta merged. Its runtime was noted when all the data of this column table was present in memory and compared it with the runtime of the same query when the data was completely offloaded from the memory. This is how I simulated it for the entire partitioned table loading and unloading rather than its pages.
Here are the results of the query runtimes when all the column data is present in memory and not being present in memory.
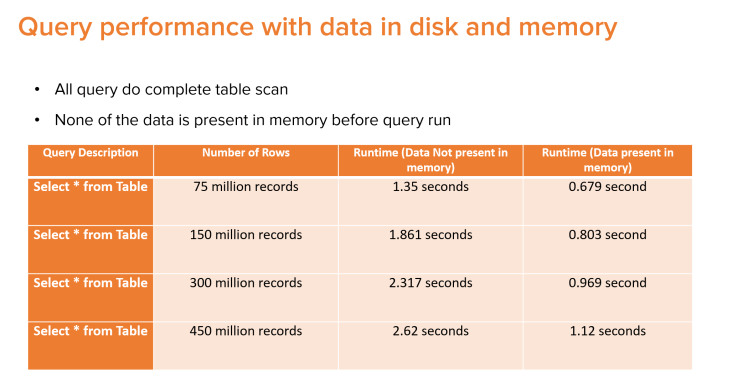
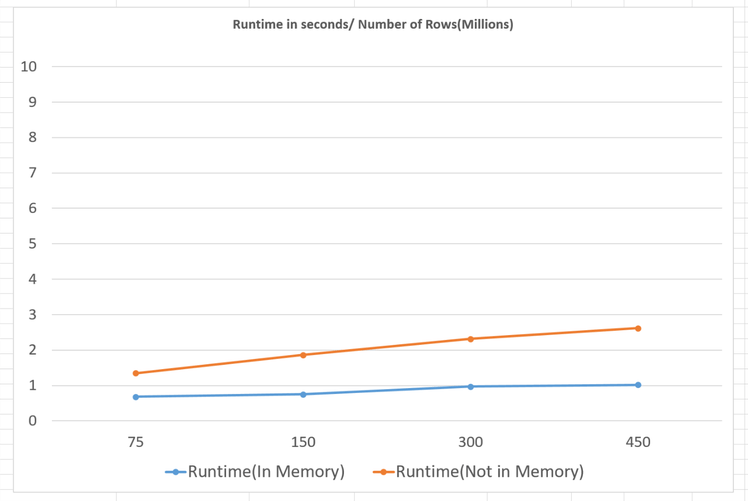
The results show that the runtime of queries of column table data not present in memory is slightly slower than the runtime of queries of column table data present in memory. This shows FlashArray//X read performance is so good, query runtimes are slowed by an average of only 1.17 seconds even when all the data is getting loaded from the persistence layer, as the number of records was increased from 75 million records to 450 million records!
Summary: The loading of SAP HANA tables is so fast on FlashArray//X that end-users will not even notice such a marginal query runtime performance when column data has been unloaded. This shows the superior read performance of FlashArray//X and what a difference it will have to your SAP HANA systems.



