
Storage capacity reporting seems like a pretty straight forward topic. How much storage am I using? But when you introduce the concept of multiple levels of thin provisioning AND data reduction into it, all usage is not equal (does it compress well? does it dedupe well? is it zeroes?). Learn more in the second part of our series on VMware storage capacity.
This multi-part series will break it down in the following sections:
- VMFS and thin virtual disks
- VMFS and thick virtual disks
- Thoughts on VMFS Capacity Reporting
- VVols and capacity reporting
- VVols and UNMAP
Let’s talk about the ins and outs of these in detail, then of course finish it up with why VVols makes this so much better.
NOTE: Examples in this are giving from a FlashArray perspective. So mileage may vary depending on the type of array you have. The VMFS and above layer though are the same for all. This is the benefit of VMFS–it abstracts the physical layer. This is also the downside, as I will describe in these posts.
VMware Storage Capacity: Thick Virtual Disks and VMFS
I refer back to part I of this series quite a bit, so make sure to read it first, before moving on.
Eagerzeroedthick (EZT) is the OG of virtual disks. Used to be the default back in the day and is still widely used.
NOTE: I will focus this conversation on EZT, not zeroedthick virtual disks, but for our purposes they are basically the same. The only space difference is eager writes zeroes first instead as needed. On a zero-removing array this difference therefore is irrelevant.
Unlike thin virtual disks, EZT disk are not particularly flexible. But they do have one primary benefit–performance.
Thin virtual disks only allocate space when needed. When a new writes comes in from a VM, the VMDK file is expanded on the VMFS and that block is then zeroed out (using WRITE SAME). Then the write is committed. This happens every time a new block is written to. Once that block has been written to that process does not need to be repeated. Eagerzeroedthick gets that allocation penalty out of the way upon its creation. When you create a EZT disk, the whole potential capacity of the virtual disk is allocated on the VMFS and it is also fully zeroed out before it can be used at all by a guest. This means that new write latency penalty is not a factor for EZT. Though it does mean it takes longer to create.
While this performance difference is small, it is non-zero. So for applications that are super sensitive to latency (I need .3 ms, not .7), EZT is the safe bet.
Anyways, the point of this post is capacity. So let’s look at that.
Creating an EZT virtual disk
Before we create a virtual disk, let’s review the configuration. I have an empty VMFS (save for some VMFS metadata):
![]()
The underlying volume is also empty (except for that metadata):
![]()
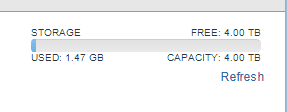
Now let’s create a 40 GB EZT disk.
Once created, it immediately takes up all 40 GB of space on the VMFS:

On the array there is no change:
![]()
This is because even though it writes a bunch of zeroes, that all gets discarded by data reduction.
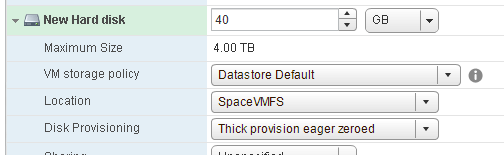
On top of this EZT VMDK, I have an empty NTFS:
So to summarize–we have 0 GB used in the VM, 40 GB used in VMFS and 0 GB used on the FlashArray. This is the natural state of EZT.
Writing to an EZT virtual disk
So let’s add some data. 20 GB of it. I will use VDBench to write out a 40 GB file of non-zero data.
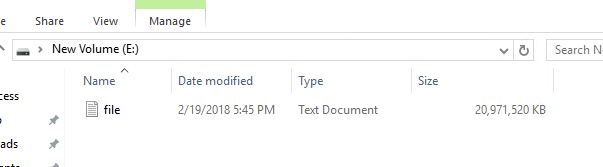
As expected, there is no change in the VMFS reported size of the virtual disk. It will always be 40 GB:
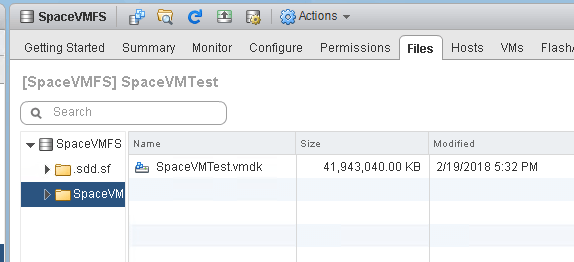
EZT will always report as the size they were created as–regardless to the fact that it is only half-full.
The FlashArray though does report space usage:
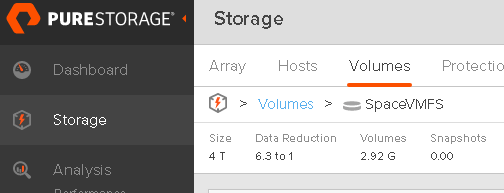 About 3 GB. Even though 20 GB were written, the FlashArray reduced this to 3 GB.
About 3 GB. Even though 20 GB were written, the FlashArray reduced this to 3 GB.
We now have 20 GB used in the VM, 40 GB used on the VMFS and 3 GB used.
With EZT disks, it doesn’t really matter how much you write from a VMFS perspective. The space is always reserved. From a FlashArray perspective it looks no different from a thin virtual disk.
You might not have a FlashArray, or some other array that automatically removes zeroes. You might have an array that simply can’t. Or you might have an array that can remove contiguous zeroes when requested. So on the array side, your mileage may vary. If your array does not remove zeroes, you would be in a 40 GB/40 GB/40 GB situation which makes things a bit harder to figure out when something was written to. Once again, this stresses the importance of understanding how your array stores data.
Deleting data in an EZT virtual disk
What happens when you delete data in the VM on a file system on a EZT virtual disk?
Let’s try.
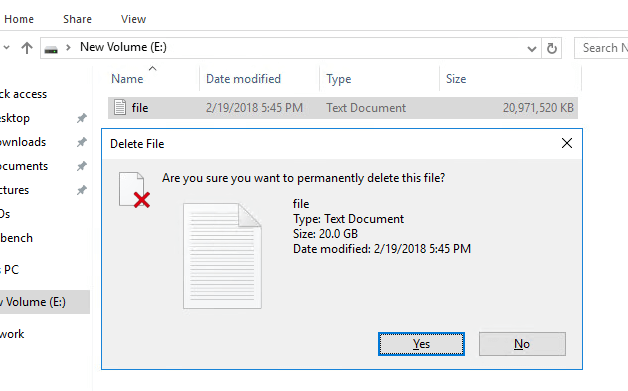
So now the NTFS is empty again:
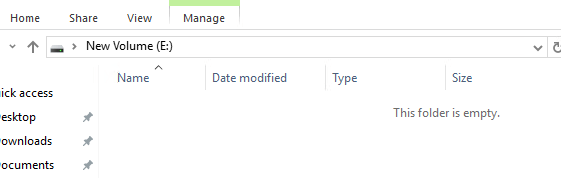
But the VMFS is still showing that the EZT disk is 40 GB:
And the FlashArray is still reporting 3 GB used:
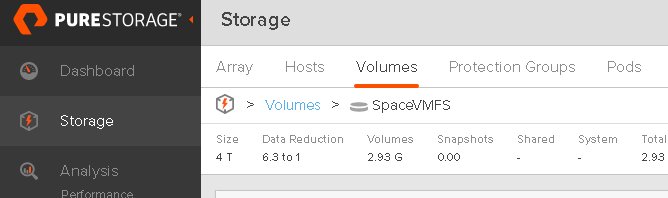
So the NTFS says 0 GB, VMFS says 40 GB and the array says 3 GB.
Let’s think about this for a second:
- The guest OS (in this case Windows) reports how much it currently has written. This case, it is now zero. The file has been deleted.
- VMFS reports how much has been allocated. With EZT, allocated always equals the size of the virtual disk.
- The array reports the physical footprint of what was last written in total. It stays that way until it is overwritten. If something is simply deleted, and there is no overwrite, so the array is unaware. Exactly the size of the footprint is dictated by how/if the array uses data reduction.
These are all different metrics and therefore mean different things.
So how do we get VMware and the array to reflect what is actually in-use by the guest? Well there are a variety of methods, but it usually boils down to two options:
- Writing zeroes
- In-guest UNMAP
How do we reclaim this? Well, unlike thin virtual disks, UNMAP is not an option.
A simple way to prove this out in Windows is to use the Optimize Drives tool.
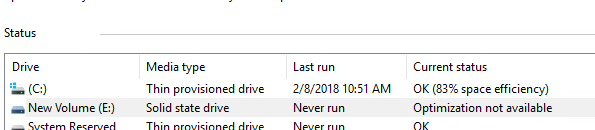
My E: drive which is my EZT disk, is not reported as thinly-provisioned. So Windows will not issue UNMAP to it. For other OSes, or really anything, you can check the VPD page for logical block provisioning. If the UNMAP support is listed as 0, it does not support UNMAP.
So we are left with zeroing.
Reclaiming space by zeroing a EZT virtual disk
To reclaim the space on the array, we need to essentially bypass VMware. If your array is zero-aware, this is the easiest option in the case of EZT disks.
So I just deleted my 20 GB of data from my NTFS, so I need my array under that to reflect it. UNMAP doesn’t work here, so I zero. So in my Windows example, sDelete is my friend.
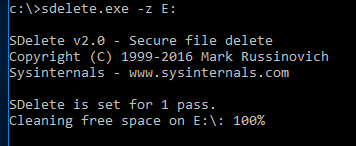
This will zero out all of the free space on the VMDK. There is no “bloat” penalty, unlike thin, because, hey–the virtual disk is already bloated to its full size.
Nothing changes in the VMFS, as expected:
But on the FlashArray everything is reclaimed:
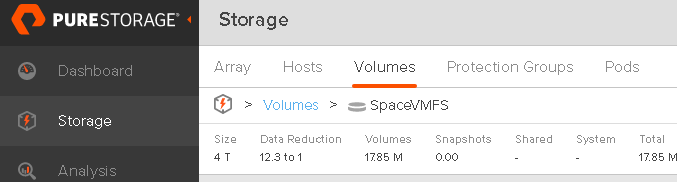
We are back to our original 0 GB on NTFS, 40 GB on VMFS and 0 GB on the FlashArray.
VMware Storage Capacity: Deleting an EZT Virtual Disk
The last thing is deleting an eagerzeroedthick virtual disk. When you delete an EZT disk, it is removed from the VM and also off of the VMFS.
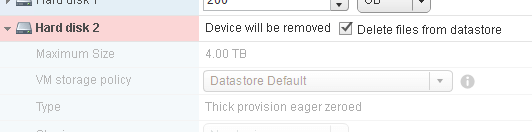
The disk is now gone off of the VMFS: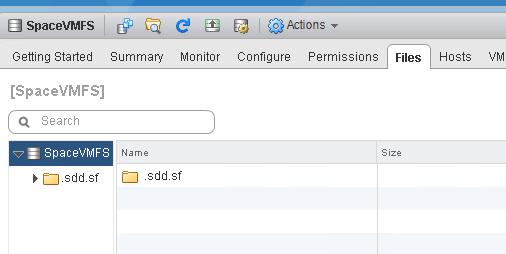
The array still has data:
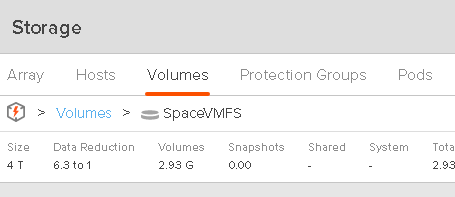
So no disk in the VM, 0 GB used on VMFS and 3 GB used on the array. So 3 GB of dead space.
So this requires VMFS UNMAP to be run. Either esxcli storage vmfs unmap -l SpaceVMFS
How do I reclaim this? Well this is called VMFS UNMAP. When a file is deleted from VMFS, UNMAP needs to be issued to the array to tell it that the space is freed up.
- In VMFS-5 this is manual, using the esxcli storage vmfs UNMAP command as seen in this post VMware Dead Space Reclamation (UNMAP) and Pure Storage
- In VMFS-6 it is automatic, as seen in this post: What’s new in ESXi 6.5 Storage Part I: UNMAP
Once run (whether VMFS-6 did it automatically, or you ran it for VMFS-5 via a script or something) the space on the array is reclaimed.
VMware Storage Capacity Part II Conclusion
So space account is a bit more difficult with eagerzeroedthick or zeroedthick disks, because it is must harder to tell if there is dead space in the guest itself. Since the VMDK size doesn’t report on what it thinks is written, there is nothing to really compare what the guest knows is written to. Especially when there is more than one VMDK on the datastore.
Look for the next post on conclusion thoughts on VMFS and capacity reporting.



