


Pandas is a powerful tool for data exploration and analysis, leveraging Python’s ease of use with the optimized execution of NumPy’s arithmetic libraries. However, there are shortcomings to consider and overcome.
What Are Pandas Shortcomings?
Three common shortcomings of Pandas include:
- slow IO from object storage
- single-threaded execution
- the requirement that datasets fit in memory.
As object storage becomes the primary storage for data science, slow data loading from S3 inhibits iteration and experimentation. Solutions to the three Pandas challenges are surprisingly interrelated: Using performant (not boto3) code for object access with distributed computation frameworks like PySpark can result in up to 20x improvements in CSV load times. Once datasets reach terabyte scale, this is a necessary improvement.
In this article, I investigate how to improve load times for gigabyte-sized CSV data from fast object storage. A summary of my findings is as follows:
- Using a fuse-mount via Goofys is faster than s3fs for basic Pandas reads.
- Parallelization frameworks for Pandas increase S3 reads by 2x.
- Boto3 performance is a bottleneck with parallelized loads.
- Replacing Pandas with scalable frameworks PySpark, Dask, and PyArrow results in up to 20x improvements on data reads of a 5GB CSV file.
- PySpark has the best performance, scalability, and Pandas-compatibility trade-off.
Many other articles have discussed Pandas alternatives, especially Spark, and new startups are even innovating new ways to improve Pandas performance. The unique angle I am taking here is focusing on improving performance reading data from a fast S3 backend.
How to Improve Performance Reading Data from a Fast S3 Backend
The best way to improve performance is to use PySpark which uses the s3a java library and also supports distributed computation and datasets larger than memory. Moving away from boto3 is also essential to solving object storage performance issues. For a quick and minimally disruptive option, a fuse-mount provided by Goofys can speed up Pandas load times.
The space of data science tools is enormous, so I specifically focus on 1) Python-based tools with dataframe APIs, 2) tools that can read data from S3, 3) single-node applications, i.e., no multi-node clusters used, 4) data in CSV format, and 5) read path only. In addition to Pandas, I test Dask, PyArrow, and PySpark (including Pandas-on-Spark), which improve S3 performance as well as adding concurrency and removing memory limitations. Both PyArrow and PySpark are Python wrappers around their respective core projects (Apache Arrow and Apache Spark). Finally, I also test Goofys fuse mounts as a way to use Pandas’ file read paths instead of accessing objects via s3fs.
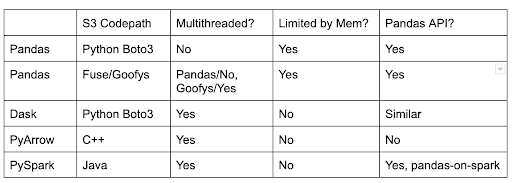
The following table contrasts the frameworks compared in this article, all of which have APIs to interoperate with Pandas.
Dataset and Test Scenario Introduction
The primary dataset for my experiments is a 5GB CSV file with 80M rows and four columns: two string and two integer (original source: Wikipedia page view statistics). The test system is a 16-core VM with 64GB of memory and a 10GbE network interface. The fast object backend, a small eight-blade FlashBlade® system running Purity v3.3.0, can easily saturate the network in either direction.
Example rows from this dataset:
project url count bytes
aa %CE%92%CE%84_%CE%95%CF%80%CE%B9%CF%83%CF… 1 4854
aa %CE%98%CE%B5%CF%8C%CE%B4%CF%89%CF%81%CE… 1 4917
aa %CE%9C%CF%89%CE%AC%CE%BC%CE%B5%CE%B8_%CE… 1 4832
aa %CE%A0%CE%B9%CE%B5%CF%81_%CE%9B%27_%CE%91…1 4828
aa %CE%A3%CE%A4%CE%84_%CE%A3%CF%84%CE%B1%CF… 1 4819
For Pandas to read from s3, the following modules are needed:
pip install boto3 pandas s3fs
The baseline load uses the Pandas read_csv operation which leverages the s3fs and boto3 python libraries to retrieve the data from an object store. Since I use a FlashBlade object store, the only code change I need is to override the “endpoint_url” parameter to point to the data VIP of my FlashBlade (10.62.64.200) instead of the default AWS S3 endpoint.
import pandas as pd
ENDPOINT_URL="https://10.62.64.200"
storage_opts = {'client_kwargs': {'endpoint_url': ENDPOINT_URL}}
df = pd.read_csv("s3://" + BUCKETPATH, storage_options=storage_opts)
A credentials file specifies the S3 access and secret keys for all tests.
As a baseline, it takes Pandas ~100s to load the CSV from FlashBlade S3, which corresponds to 50MB/s. In contrast, Pandas takes only ~70s reading from a local file. Relying on local files introduces challenges for easily sharing datasets across multiple users or teams, but there should not be a performance difference here.
As a sanity check, I can use s5cmd and awk to do lightweight parsing and filtering on my CSV in ~30s, i.e., 3x faster and still only using a single core. Given that my machine has 16 cores, surely we can do better than the default 100s in Pandas?
To understand how to improve performance, I look at three paths:
- Using parallelization frameworks for data loading
- Using frameworks that read from S3 using compiled languages (not Python!)
- Switching to non-Pandas APIs which do not require all data in memory
Step 1: Using Parallelization
Python and Pandas execute with a single thread, so the first step in optimization is obvious: parallelization of the DataFrame creation. I test four load times with standard Pandas (light blue results) and then four different variants using a parallelization framework (dark blue results).
All of the tests yield the same result, an in-memory Pandas dataframe upon which a wide variety of analytics can be done. Specifically, the tests only measure the time it takes to construct the Pandas dataframe in memory, as any following analytics will be the same speed regardless of original data source.
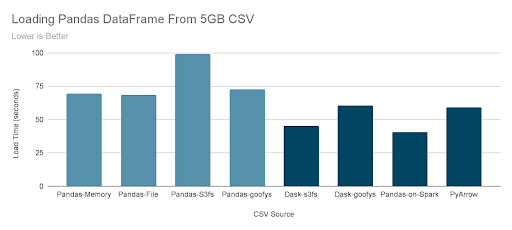
First, the Pandas load times from data already in memory and from local files are the same, indicating the bottleneck is entirely CSV parsing into a DataFrame. Reading through s3fs slows down the load time 43% relative to local files.
For standard Pandas, Goofys provides a significant improvement over s3fs for object store data by letting Pandas use standard filesystem reads and not boto3. Goofys is faster because it is written in Go and uses concurrency better than s3fs. But as the Dask-goofys results show, the benefit goes away with a parallelization framework because the extra concurrency of Dask provides more concurrency to s3fs. Therefore, Goofys is an excellent choice to improve standard Pandas IO performance if there are no other performance and scalability issues.
Quick aside: There are two identically named s3fs libraries. I refer only to the python library and not the fuse mount library.
Dask, Pyspark, and PyArrow parallelize the processing of loading and parsing the CSV and significantly improve download speeds from S3. Performance approximately doubles and is not better because much of the load time is no longer for IO but rather materializes the Pandas dataframe in memory.
As an example, the PyArrow total load time is ~59 seconds, but that breaks down into two phases. First, loading from S3 into Arrow in-memory format takes 43% of the time and converting to Pandas DataFrame (requiring no external IO) takes the remaining 57% of time. Later, I will show results that directly using the native APIs in these frameworks is even more performant.
Details on How to Run Each Test
The syntax for loading CSV from non-AWS S3 storage is slightly different in each framework. This section describes each. In all cases, I manually specify the column names and data types to avoid type inference overhead for these tests but leave that detail out of code snippets for brevity.
Dask installation requires the following packages:
pip install boto3 dask dask[distributed] pandas s3fs
The Dask syntax is almost identical to the original Pandas, with the addition of the compute() call which transforms the Dask-distributed DataFrame to a Pandas (in-memory) DataFrame.
import dask.dataframe as dd
ENDPOINT_URL="https://10.62.64.200"
storage_opts = {'client_kwargs': {'endpoint_url': ENDPOINT_URL}}
ddf = dd.read_csv("s3://"+BUCKETPATH, storage_options=storage_opts)
df = ddf.compute(scheduler='processes')
Goofys can be downloaded as follows:
wget -N https://github.com/kahing/goofys/releases/latest/download/goofys
chmod a+x goofys
And then mount the bucket as a filesystem before using Pandas with standard file paths:
sudo mkdir -p /mnt/fuse_goofys && sudo chown $USER /mnt/fuse_goofys
./goofys --endpoint=https://$FLASHBLADE_IP $BUCKETNAME /mnt/fuse_goofys
PySpark installation requires a java runtime as well as the PySpark and Pandas Python modules:
apt install -y openjdk-11-jdk
pip install pandas pyspark
Because I am using Spark in single-node mode, there is no cluster setup required.
To run PySpark with S3, I need to specify several command line options to the spark-submit invocation to load and configure S3 access, including specifying the endpoint URL.
spark-submit \
--packages org.apache.hadoop:hadoop-aws:3.2.2 \
--conf spark.hadoop.fs.s3a.endpoint=10.62.64.200 \
--conf spark.hadoop.fs.s3a.aws.credentials.provider=org.apache.hadoop.fs.s3a.SimpleAWSCredentialsProvider \
--conf spark.hadoop.fs.s3a.connection.ssl.enabled=false \
Then in Python, the Pandas-on-Spark (formerly Koalas) read_csv() function looks similar, but I also include a call to persist() to ensure that the dataframe is in memory for a fair comparison to Pandas.
import pyspark.pandas as ps
pdf = ps.read_csv("s3a://" + BUCKETPATH)
with pdf.spark.persist(pyspark.StorageLevel.MEMORY_ONLY) as df:
print(df.count())
Note that in PySpark, a “storage_opts” is not required for each invocation of read and instead the spark-submit configuration applies to all s3a paths.
PyArrow is a wrapper around the Arrow libraries, installed as a Python package:
pip install pandas pyarrow
In Python code, create an S3FileSystem object in order to leverage Arrow’s C++ implementation of S3 read logic:
import pyarrow.dataset as ds
ENDPOINT = "10.62.64.200"
fbs3 = pyarrow.fs.S3FileSystem(access_key=ACCESS_KEY, secret_key=SECRET_KEY, endpoint_override=ENDPOINT, scheme='http')
dataset = ds.dataset(BUCKETPATH, filesystem=fbs3)
df = dataset.to_table().to_pandas()
Is Storage the Bottleneck?
Concurrency improved performance, but did it improve enough so that the storage is now the bottleneck? Measuring read throughputs directly from storage shows that the bottleneck is the Python boto3 stack and not the client or storage backend.
The following experiment tests the time taken to load into memory the contents of the 5GB object from FlashBlade. No parsing of the data is done, so this test focuses only on the speed from storage into Python memory.
The results show that even the fastest boto3 call is significantly slower than both a standard Golang object download and reading from a ramdisk. These two points indicate boto3 as the bottleneck in reading data from S3. The Goofys result also illustrates why it improves Pandas load times relative to s3fs.
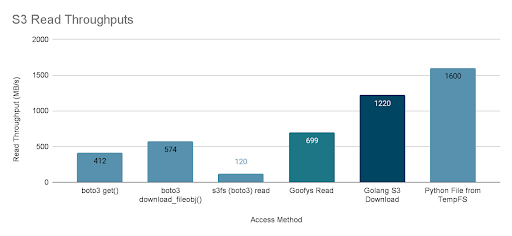
The first two tests are for standard boto3 APIs for retrieving data from S3: get() and download_fileobj(). In both cases, the object’s contents are returned as an in-memory buffer, not downloaded to a local file. The fastest download of 574MB/s is much faster than single-threaded Pandas CSV parser but far slower than what the FlashBlade backend can send.
Reading from s3fs directly, which uses boto3 underneath, is slowest because it does not effectively use concurrency. In frameworks like Dask, this is not a problem because Dask enables the Python concurrency necessary to improve the performance of s3fs.
The fifth result is the read throughput using the basic s3 downloader Golang API, i.e., equivalent to the Python download_fileobj() written in Go instead of Python. The performance reaches the limits of the 10GbE network interface on my client, indicating that the infrastructure and OS can support significantly higher throughputs than Python/boto3 achieves. Previous measurements on a client machine with 100GbE networking show that downloads can reach almost 8GB/s from the FlashBlade.
Finally, the last result shows that reading the file from an in-memory ramdisk filesystem is even faster at 1.6GB/s. This suggests that Python could read data into memory faster, in theory, so it is not Python and the GIL that is the bottleneck but rather boto3.
The previous results have focused on retrieving data from a fast object store; the FlashBlade is purpose-built with all-flash storage. To understand the impact of a more traditional object store, I measured load times against AWS S3 from an EC2 instance, m5.8xlarge, with matching specifications as my client machine.
The default Pandas load time is 2.7x worse when using AWS S3 versus FlashBlade S3, suggesting the poor performance is an even bigger problem on other object store backends. Impressively, the gains from parallelization using Dask almost bring performance back even with that of the FlashBlade, shifting the bottleneck back to the client application. The Pandas-on-Spark API is still 66% slower on AWS than FlashBlade.
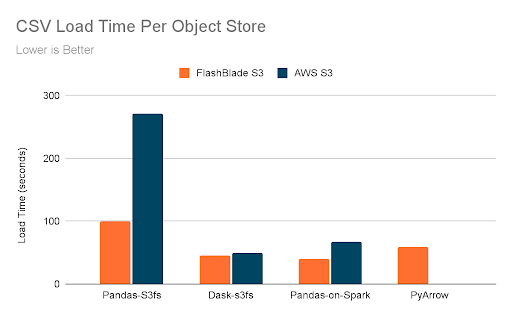
PyArrow was not able to load the 5GB object from AWS S3 due to timeouts:
AWS Error [code 99]: curlCode: 28, Timeout was reached
While I focus my tests on the FlashBlade, adopting parallel frameworks for Pandas is even more important when accessing data on AWS S3. At least for the FlashBlade, the bottleneck is not the storage performance or the client machine, therefore the next section looks at alternatives to Pandas and boto3.
Step 2: Beyond Pandas
Improving overall performance necessitates evaluating Pandas alternatives. The downside is slightly different APIs and functionality, but the upside is scalability and performance. The previous results were constrained to keeping exact Pandas compatibility, but now I relax that requirement in order to scale to larger datasets. Instead of simply loading the CSV, I now test loading and filtering the DataFrame based on a column value.
The graph below shows the time taken to load and filter a CSV dataset, selecting a subset of rows based on a simple condition:
# pyspark
c = df.filter(df["count"] == 1).count()
# pyarrow
tab = dataset.scanner(filter=ds.field("count") == 1).to_table()
# dask
c = len(df[df['count'] == 1].index)
Two different input sizes are tested, the original 5GB and a 7x larger version (35GB) which does not fit in memory on my machine. The expectation is that it should take 7x longer to process the larger file.
First, the relative speeds on the 5GB object show all three alternatives—Dask, PySpark, and PyArrow—to be significantly faster than Pandas. In fact, PySpark is nearly 20x faster than Pandas and seems limited by the 10GbE network interface on my test machine. Even more impressively, PySpark is 3x faster than Dask and 5x faster than PyArrow.
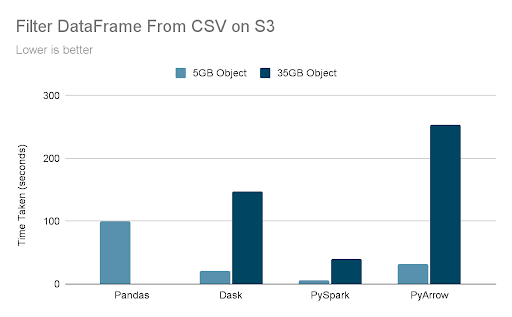
The second set of results is load times for a larger version of the dataset. As expected, all three parallel frameworks scale nearly linearly, i.e., a 7x larger dataset takes 7x longer to parse and filter. There is no result for Pandas with the 35GB input because of memory limitations. These results show the scalability of both the parallel frameworks as well as their ability to read data from FlashBlade S3.
Conclusion
Three key limitations of Pandas are surprisingly interrelated: 1) single-threaded operations, 2) low object storage performance, and 3) the requirements that datasets fit in memory. In focusing on ways to improve time for reading data from S3, the best solutions also address the other two issues. Single-node PySpark best overcomes all three limitations in my test scenarios.
There are two further reasons to prefer PySpark: pandas-on-spark (formerly Koalas) continues to improve Pandas-compatibility and PySpark already natively scales out to multiple nodes in clustered computations.
Object storage performance suffers due to limitations of boto3, the official python library for S3 access, so the solution is to use a more-performant framework written in a compiled language for multi-threaded S3 access. Examples include Goofys fuse mounts (Go), PySpark (JVM), and PyArrow (c++). For a tactical approach to speed up Pandas, Goofys improves performance over s3fs. And for a more strategic way to overcome performance and scalability issues using Pandas with S3, it’s time to check out PySpark as a replacement.

Written By:



