



This article on Apache Spark first appeared on Medium. This blog was republished with the author’s credit and consent.
Quite a lot of big data and most machine learning workloads are compute-bound. While machine learning, especially deep learning, has been leveraging GPU to accelerate the computation for years, GPU acceleration for big data is relatively new. It is good to see active developments of Spark RAPIDS in this area.
Spark RAPIDS is an accelerator for Apache Spark that leverages GPUs to accelerate computation via the RAPIDS libraries. The idea is to build a unified framework that consolidates and accelerates both big data and machine learning workloads. Recently, I have integrated Spark RAPIDS into my lab environment with Kubernetes and FlashBlade® so that I can run a single pipeline, from ingest to data preparation/ETL to model training, in a single environment.
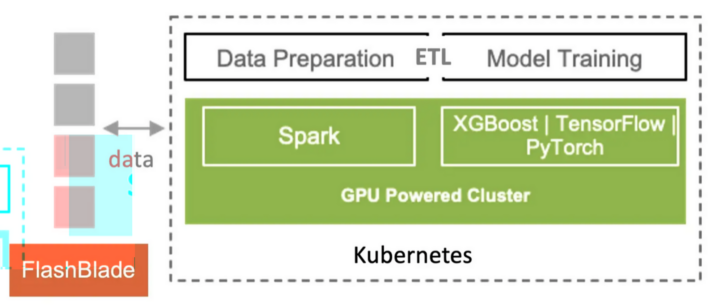
A single pipeline, from ingest to data preparation/ETL to model training.
In my previous blog post, I briefly expressed my idea of consolidating and accelerating big data with Kubernetes, GPU and Spark RAPIDS, and FlashBlade. Today, I will explain how to get started with this setup. I will also share more details about benchmarking Spark RAPIDS on Kubernetes with S3 on FlashBlade.
Getting Started with Spark RAPIDS on Kubernetes
I have written about how to use Apache Spark with Kubernetes in my previous blog post. To add GPU support on top of that, aka adding Spark RAPIDS support, we will need to:
- Build the Spark image using CUDA-enabled base images, such as the NVIDIA/cuda images.
- Retrieve the RAPIDS Spark jar, and put it under Spark/jars directory.
- Copy the GPU discovery script to spark/bin directory.
A bonus tip here is to always set the timezone to UTC in the Spark image. As I will show later, this could make a big performance difference in Spark jobs, because as of Spark RAPIDS version 22.10, for timestamp data, only data with UTC zone can run on GPUs.
Let’s test the image with the Spark Pi example. Add or modify the following GPU-related settings in spark-pi.yaml to enable GPU acceleration.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 |
spec: type: Scala mode: cluster image: “<your-image-repo>/apache-spark:3.3.0-rapids22.10” mainClass: org.apache.spark.examples.SparkPi ... executor: instances: 2 cores: 1 memory: 4G gpu: >name: “nvidia.com/gpu” quantity: 1 sparkConf: “spark.executor.resource.gpu.amount”: “1” “spark.rapids.memory.pinnedPool.size”: “2G” “spark.executor.resource.gpu.discoveryScript”: “/opt/spark/bin/getGpusResources.sh” “spark.executor.resource.gpu.vendor”: “nvidia.com” “spark.plugins”: “com.nvidia.spark.SQLPlugin” “spark.rapids.sql.explain”: “NOT_ON_GPU” |
In this example, I gave one GPU to each of the Spark executors. The job should output logs like this:
|
1 2 3 4 5 6 7 8 9 10 11 |
2023–02–10 07:34:35,932 WARN rapids.RapidsPluginUtils: RAPIDS Accelerator 22.10.0 using cudf 22.10.0. 2023–02–10 07:34:35,965 WARN rapids.RapidsPluginUtils: spark.rapids.sql.multiThreadedRead.numThreads is set to 20. 2023–02–10 07:34:35,970 WARN rapids.RapidsPluginUtils: RAPIDS Accelerator is enabled, to disable GPU support set `spark.rapids.sql.enabled` to false. 2023–02–10 07:34:35,970 WARN rapids.RapidsPluginUtils: spark.rapids.sql.explain is set to `NOT_ON_GPU`. Set it to ‘NONE’ to suppress the diagnostics logging about the query placement on the GPU. ... Pi is roughly 3.1327356636783183 |
Here’s another example to test with Spark SQL and dataframe:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
from pyspark.sql import SQLContext from pyspark import SparkConf from pyspark import SparkContext conf = SparkConf() sc = SparkContext.getOrCreate() sqlContext = SQLContext(sc) df=sqlContext.createDataFrame([1,2,3], “int”).toDF(“value”) df.createOrReplaceTempView(“df”) >sqlContext.sql(“SELECT * FROM df WHERE value<>1”).explain() sqlContext.sql(“SELECT * FROM df WHERE value<>1”).show() sc.stop() |
This time, I set spark.rapids.sql.explain=ALL to log what can or cannot run on GPU, as shown below.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
2022–11–14 17:14:40,858 INFO rapids.GpuOverrides: Plan conversion to the GPU took 20.62 ms 2022–11–14 17:14:40,896 INFO rapids.GpuOverrides: GPU plan transition optimization took 6.38 ms 2022–11–14 17:14:41,112 WARN rapids.GpuOverrides: *Exec <FilterExec> will run on GPU *Expression <And> (isnotnull(value#0) AND NOT (value#0 = 1)) will run on GPU *Expression <IsNotNull> isnotnull(value#0) will run on GPU *Expression <Not> NOT (value#0 = 1) will run on GPU *Expression <EqualTo> (value#0 = 1) will run on GPU ! <RDDScanExec> cannot run on GPU because GPU does not currently support the operator class org.apache.spark.sql.execution.RDDScanExec <span style=“font-weight: 400;”> @Expression <AttributeReference> value#0 could run on GPU</span> 2022–11–14 17:14:41,143 INFO rapids.GpuOverrides: Plan conversion to the GPU took 52.40 ms 2022–11–14 17:14:41,161 INFO rapids.GpuOverrides: GPU plan transition optimization took 14.54 ms == Physical Plan == GpuColumnarToRow false +– GpuFilter (gpuisnotnull(value#0) AND NOT (value#0 = 1)), true +– GpuRowToColumnar targetsize(2147483647) +– *(1) Scan ExistingRDD[value#0] |
Note that there are some incompatibilities with Apache Spark. At the time of this writing, Spark RAPIDS is still under active development. It may not be ready for some people, but it seems to be promising and exciting, as you will see in my benchmark result.
Benchmarking Spark RAPIDS
To compare Spark performance running on and off GPU, I use the NVIDIA NDS benchmark, which is derived from the TPC-DS benchmark.
Here is my test environment:
- Storage: FlashBlade (previous generation) with S3
- Network: Multiple 40Gbps links from FlashBlade to the hosts
- Compute: 6 Spark executor pods on Kubernetes. Each pod has 4 vCPU, 24GB RAM. For the on GPU test only, 1 x NVIDIA A10 GPU is given to each pod.
- Spark RAPIDS 22.10 with Apache Spark 3.3.0.
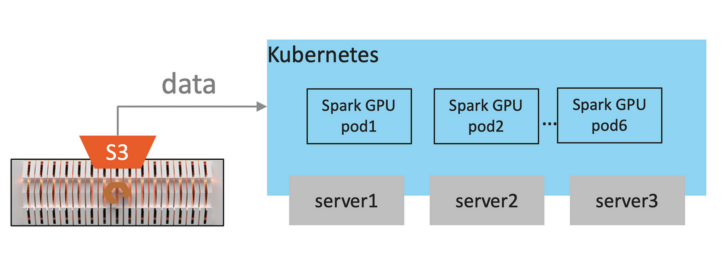
In each of the Spark executor pods, it is set to run two tasks on the same executor sharing a single GPU.
|
1 2 3 4 |
“spark.rapids.sql.concurrentGpuTasks”: “2” # the number of tasks that are actively sharing the GPU “spark.executor.resource.gpu.amount”: “1” “spark.task.resource.gpu.amount”: “0.5” # 2 tasks on the same executor to share a single GPU |
Testing with a 200GB NDS data set in this environment, Spark with GPU is 4x faster, compared to CPU-only runs.
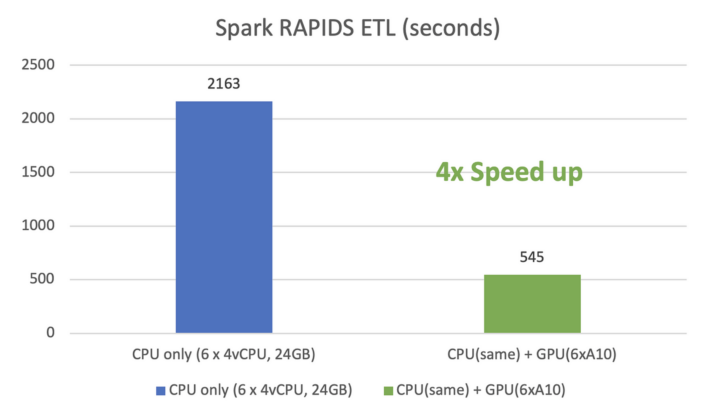
Spark with GPU is 4x faster, compared to CPU only.
During the test, I set spark.rapids.sql.explain=NOT_ON_GPU. This helps figure out what operations were not on the GPU. For example, in my first run, I noticed that the timestamp operation (which is very common) on non-UTC zone data was not on GPU. As mentioned above, I changed the timezone to UTC in the Spark image. A small change, but a big speedup.
I didn’t compare the infrastructure cost, but on the Spark RAPIDS homepage, it claims 50% cost savings with GPU/TPU on public cloud.
Modern Hybrid Cloud Solutions
Accelerate innovation with a modern data platform that unifies hybrid and multicloud ecosystems.

Conclusion
Before the benchmark, I was a little skeptical about Spark on GPU performance because, unlike machine learning workloads, many Spark operations are not necessarily GPU-friendly. Gaining 4x speed up in Spark in such a small configuration is amazing. I am sure with a bigger data set and more powerful GPUs, the speedup will be even higher.
A Spark cluster with tens to hundreds of servers is common in enterprises. Imagine you can run your Spark jobs 4x plus faster, without adding a new server. This could be game-changing because otherwise, you will need 4x servers, rack spaces, cables, and everything associated. It is true you must add some GPU cards, but you need GPU for your AI/machine learning workloads anyway.
It is especially beneficial when accelerating Spark with Spark RAPIDS on a GPU-powered Kubernetes cluster, together with fast object storage like FlashBlade. That’s because Kubernetes makes it very easy and flexible to share CPU and GPU resources and FlashBlade eliminates I/O bottlenecks between the compute and storage.
Keep GPU busy, make Spark faster.
Learn more about:




