
前回のブログでは、「愛犬家のための画像認識 AI」を例に取り、FlashBlade で構築するデータハブによってビッグデータ分析と AI をシンプルにするメリットをご紹介しました。今回は、コードサンプルと UI 画面のスクリーンショットを交え、FlashBlade によっていかに簡単に AI パイプラインを構築できるかをご説明します。
AI パイプラインを構築するための環境設定
このアーキテクチャでは、オープンソースのソフトウェアを活用しています。データの取得とデータフロー管理には Apache Nifi、リアルタイムのインデックス作成とダッシュボード作成には Apache Solr を使用します。Apache Spark は、ビッグデータ処理に最適なツールです。以下に示すように、これらのソフトウェアは全て Apache Ambari によって展開、管理されています。
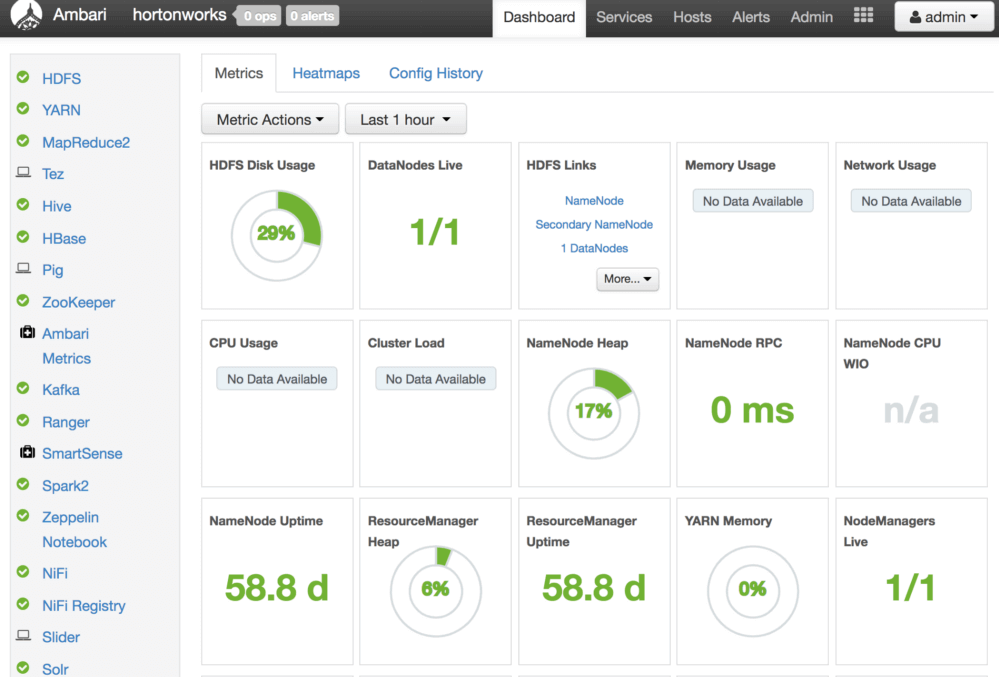
また、AI モデルのトレーニングには TensorFlow を使用し、AI モデルは Python サーバーの REST API として展開します。
私のデモ環境では、全てのソフトウェアが FlashArray 上の仮想マシンにインストールされ、実行されています。これらは、ベアメタルサーバーのクラスタでも実行できます。ツイートのローデータ、インデックスファイル、犬の画像、AI モデルなど、全てのデータが FlashBlade(FlashBlade S3 バケットまたは NFS ボリューム)に格納されています。
リアルタイムなデータ取得とデータ処理
AI と深層学習にはデータが不可欠です。 ビッグデータがなければ、AI はそれほど賢くもなく便利でもありません。
まず、NiFi を使用してリアルタイムにツイートを取得することから始めます。NiFi でのデータフロー管理は、次のようになります。
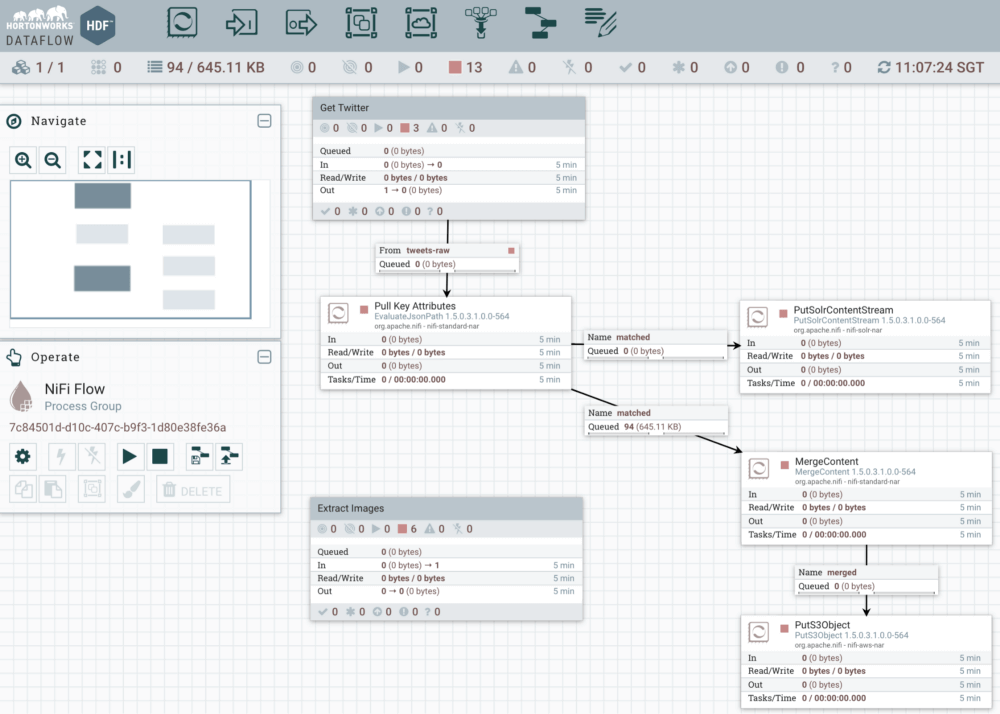
UI の各ボックスはプロセッサと呼ばれています。各プロセッサは、フロー内で簡単なジョブを実行します。NiFi は何百もの内蔵プロセッサを持っており、使いやすく強力です。プロセッサをドラッグアンドドロップで設定して接続するだけで、複雑なデータフローが形成されます。
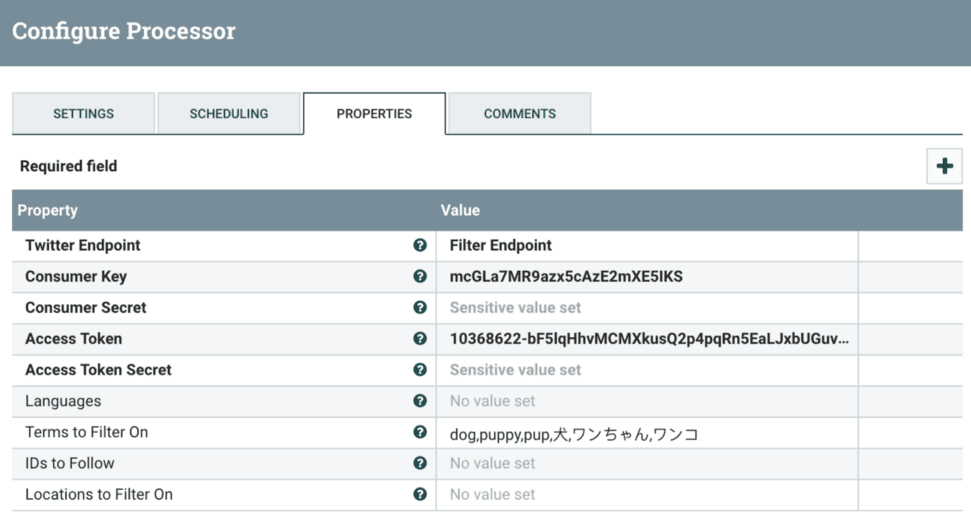
上記フローの上位 3 プロセッサについては、Twitter API を呼び出して犬に関するツイートを収集するように NiFi を設定します。そして、Twitter の応答からリアルタイムダッシュボードに必要なフィールドを抽出し、そのフィールドを Solr に送信してリアルタイムインデックスを作成します。GetTwitter プロセッサ構成の例を以下に示します。
NiFi フローを開始して数秒後には、愛犬家のツイートがリアルタイムに取り込まれ、インデックスが作成されてシステムに保存されます。データは Solr 内でインデックス付けされているため、Solr の Banana UI から、数回のクリックで簡単に以下のようなリアルタイムダッシュボードを作成できます。
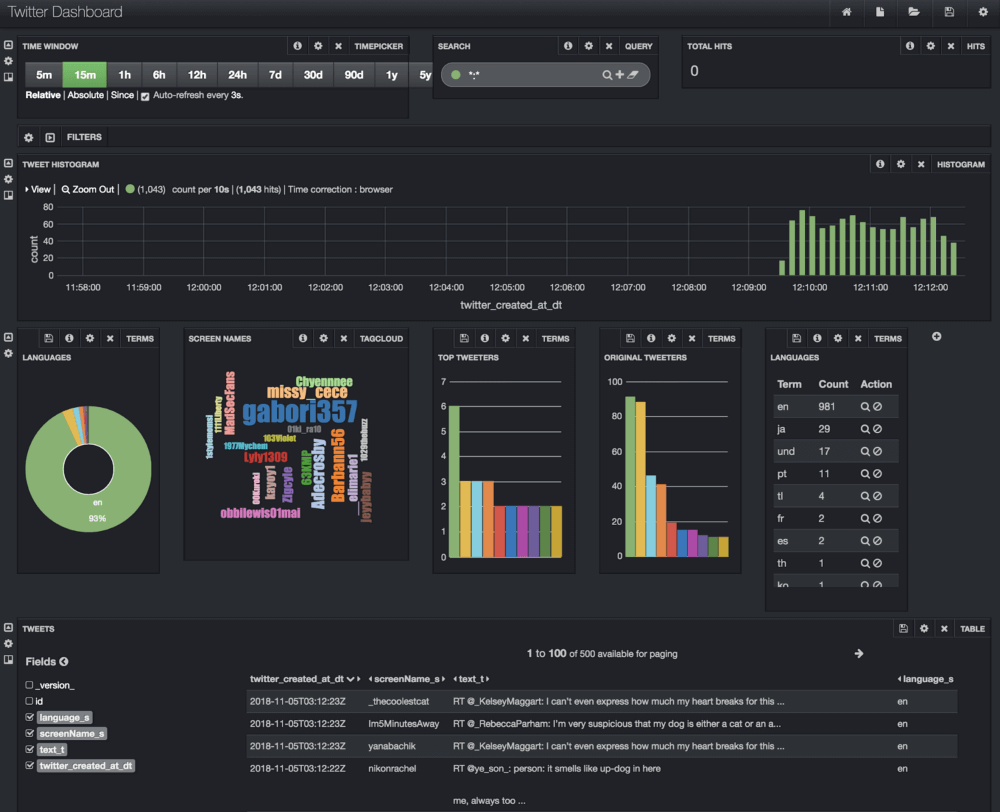
上図の例では、データのヒストグラム、ツイート数の多い人、使用言語、ツイートの内容を表示しています。Nifi と Solr は、どちらも FlashBlade NFS ボリュームをマウントしてデータを保存します。これは、Nifi と Solr の構成を変更することにより可能になります。以下のように、データディレクトリのマウントポイントを FlashBlade NFS に変更します。
nifi.propertiesファイル:
|
1 2 3 4 5 6 |
nifi.content.repository.directory.default=/mnt/nifi/content_repository nifi.database.directory=/mnt/nifi/database_repository nifi.flowfile.repository.directory=/mnt/nifi/flowfile_repository nifi.provenance.repository.directory.default=/mnt/nifi/provenance_repository |
solr.in.shファイル:
|
1 2 3 4 5 6 |
# HDFS start settings SOLR_OPTS=“$SOLR_OPTS -Dsolr.directoryFactory=HdfsDirectoryFactory \ -Dsolr.lock.type=hdfs -Dsolr.hdfs.home=file:///mnt/solr/indexes \ -Dsolr.hdfs.confdir=/usr/hdp/2.6.5.0-292/hadoop/conf” |
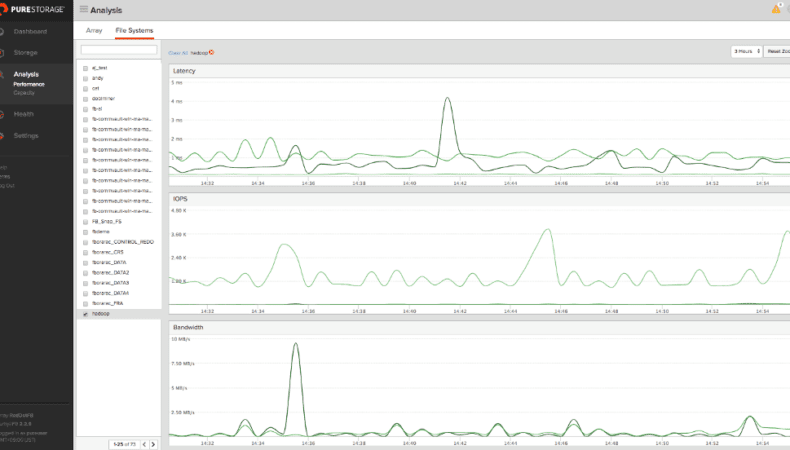
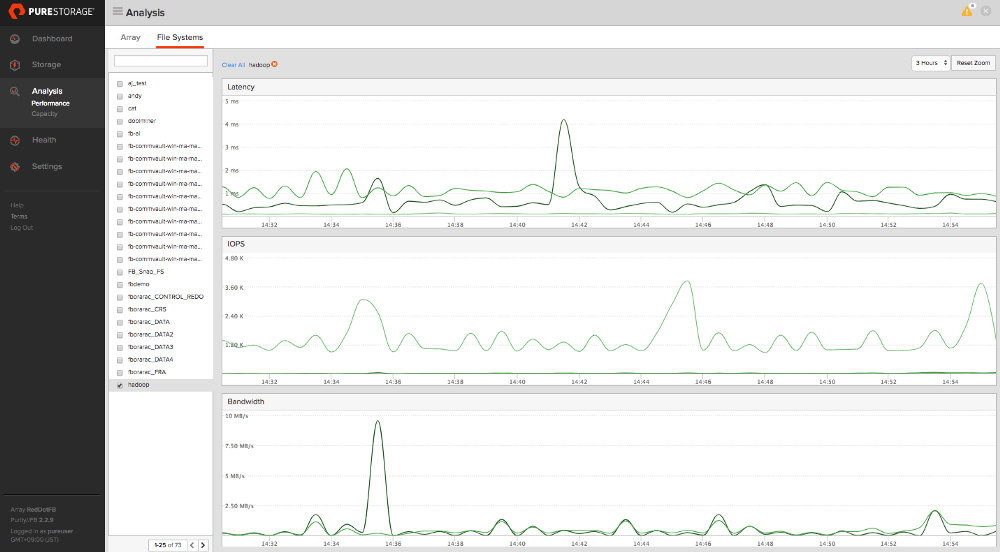
FlashBlade ダッシュボードにアクセスすると、これらのデータによって生成されたトラフィックが表示されます。
次回予告
AI の構築において非常に重要なのが、データの調査とクレンジングを行い、AI モデルのトレーニングと検証に備えることです。
次回は、FlashBlade S3、Spark、Zeppelin を使用したパイプラインのビッグデータ分析について説明します。
注:本ブログは、蒋 逸峰が Medium に投稿した記事「AI for Dog Lovers: An End to End AI Pipeline with FlashBlade — Part 1」の一部を日本語訳、再編したものです。



