


As described in Part 1 of this series, storage performance can play a huge role in the efficiency and throughput of the chip design process. Part 2 describes the impact that Pure Storage® FlashBlade™ is having in the industry and the very significant advantages customers are seeing in quality, productivity, and cost.
Today, FlashBlade is being deployed in numerous top-tier chip development environments.
Tales From the Field
One of our larger customers has an EDA compute grid of over 200,000 cores and has estimated FlashBlade powers an additional 200,000,000 simulations a year!
This has far reaching implications for this customer, some of which include:
- Higher design quality and more in-parallel design work.
- 20% improvement in utilization of compute grid. This is a productivity improvement that is the equivalent of adding 40,000 cores to the grid (~ 2000 servers).
- Greatly increased ROI on the huge investment in EDA licenses. (The EDA license cost can be 5x to 10x the IT infrastructure annual spend.)
- Savings on storage. FlashBlade supports in-line compression and has an average compression ratio of EDA data of 2:1. This customer effectively doubled the ROI on their FlashBlade investment.
As a result of this success, the organization is deploying FlashBlade for all aspects of its chip-design process in all geographies, without segmenting workloads between storage devices.
The reason they can do this is the unique ability of FlashBlade to efficiently handle different types of I/O concurrently, including lots of small files with a large amount of metadata, which is common in logic design and simulation, and huge multi-GB or TB files, which frequently occur in the physical design stages of the chip design process.
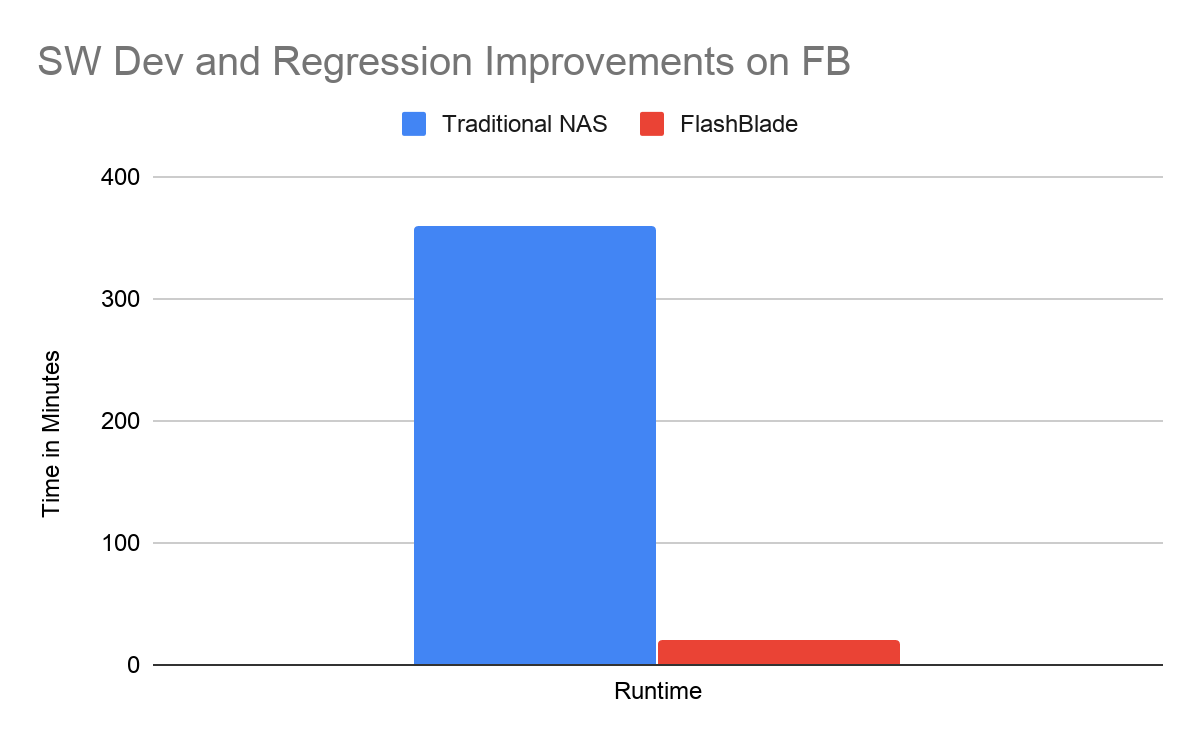
Another FlashBlade EDA customer who creates chip design software reported a greater than 10x run time improvement of their highly concurrent software build and regression workload — with runtimes repeatedly decreasing from 6 hours to 20 minutes. The result has been greatly improved the ability to identify and fix code issues and deliver higher-quality products.
AI Deployments
Many chip-design companies are now designing AI training (also referred to as inferencing systems or blocks), and thus introducing AI workloads into their environments.
The workloads for these applications are very storage intensive and can have a huge impact on run time. Traditionally, AI and machine learning engineers try to copy data to local SSDs to do their training. However, moving data around can be very expensive.
For example, if you tried to copy 10TB of data into a locally attached SSD array over 10 Gb/s network, the ideal transfer time (assuming they are huge files) would be more than 2 hours.
In reality, elapsed times would be much more, especially if your dataset has many files.
It is not uncommon for datasets to be much larger than what can fit onto local storage, and if your pipelines are constantly shuffling data around, a lot of time is lost copying.
We recommend as a best practice that data be used in place on FlashBlade and not copied out.
Some of our customers have multi-PB data sets and have reported that by having their pipelines access FlashBlade directly, they found their compute utilization (GPU/FPGA or custom silicon) greatly increased, and their net training times had improved.
A Deep Learning Example
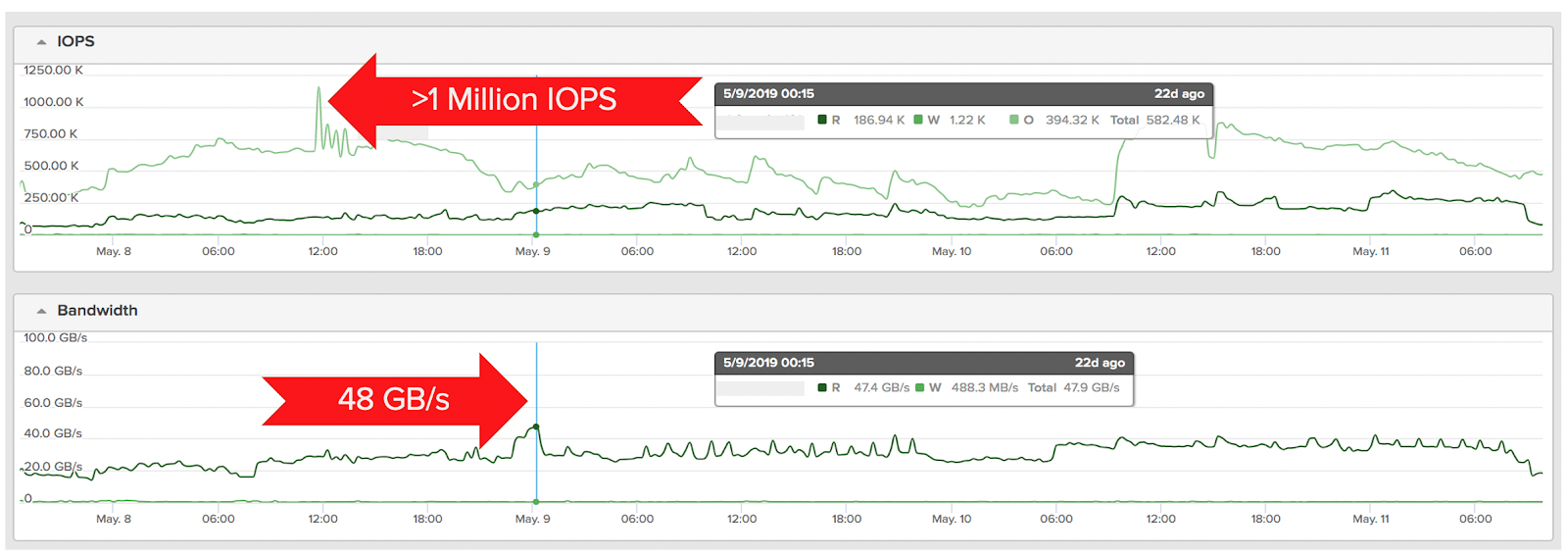
Sometimes the best way to explain something is to give an example. Here is a snapshot of one of our deep learning customer’s FlashBlade array.
As shown in the graph, it is serving reads peaking at 48 GB/s, with an average of 30GB/s — constantly over four days — while simultaneously serving over 1 million NFS metadata IOPs.
The ability of FlashBlade to serve both throughput and metadata at these high rates is unique, and it is enabling greatly improved AI pipeline efficiency.
Massive Acceleration of Standard Linux Operations with RapidFile Toolkit
Another game changing feature that FlashBlade provides for chip development environments is the RapidFile Toolkit (RFT).
The RFT provides multi-threaded versions of many standard linux tools. These are utilities that can simply be downloaded and installed on a standard linux client.
In high-file count environments such as EDA (where it is not unusual to have hundreds of millions of files in a single filesystem), these can provide massive improvements in run time for standard operations such as find and rm.

Additionally, for removal of large trees of data, FlashBlade provides the .fast_remove functionality with which a user can delete whole directory trees of data instantaneously. This is of huge value, especially in scratch space use cases, where data is continually created and deleted. It can provide significant improvements in performance for EDA workloads since traditional storage can severely slow down during this process.
To test the performance of RFT, we ran some of these tools across an Android source tree (575K files, 55GB) and compared them to their standard Linux counterparts. The results are shown in the table below (the RFT version commands have a ‘p’ prefix).
In Conclusion
FlashBlade’s ability to scale I/O efficiently under massive parallelism is making a huge impact on semiconductor designers globally.
It is speeding up all aspects of the design flow — from RTL design to tapeout — and it is helping customers release products faster, with higher quality and lower cost. It’s also enabling improved engineering productivity and the ability to do more designs at the same time.
Is storage affecting efficiency in your environment? Try running some of the above experiments to find out. A simple solution like FlashBlade can have a big impact on your productivity.
Written By:



