



Released earlier this year, VMware vSphere 7 has the ability to run virtual machines (VMs) and multiple Kubernetes clusters in hybrid mode for better manageability. vSphere 7 also provides the building blocks for cloud-native applications and simplifies the administration of security, performance, resiliency, and lifecycle management for different applications. In this post, I’ll focus on how to use VMware Tanzu for distributed machine learning (ML) and high-performance computing (HPC) applications.
ML/HPC applications can be a mix of both interactive or batch workloads. End users run jobs in parallel that start and finish once the test results converge. Many other modern applications are associated in the ML pipeline, which generates heterogeneous workloads with scalable performance requirements. Most of the ML/HPC applications require ease of deployment and simple manageability with on-demand storage provisioning and capacity scaling with predictable performance to complete the jobs that run in parallel.
Most of the ML/HPC applications like JupyterHub/notebook require ReadWriteMany (RWX) access mode for capacity scaling and data sharing in the Tanzu Kubernetes cluster, which allows reading and writing from multiple pods. The native Tanzu Kubernetes Cloud Native Storage (CNS) driver supports ReadWriteOnce (RWO) access mode. In Figure 1, the CNS driver supports vSphere datastores: VMFS/vVOLs and vSAN.
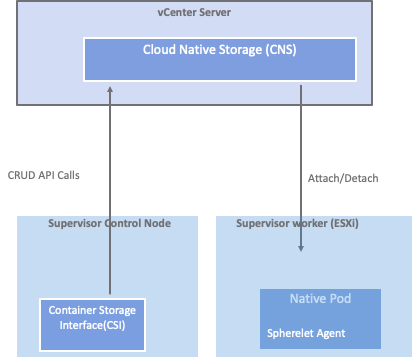
vSAN file services provide the ability to mount file systems over NFSv3 and NFSv4.1 from the Tanzu Kubernetes cluster. The vSAN file services are coupled with CNS drivers, but the setup is complicated and provisioned persistent storage isn’t elastic.
Pure Storage® FlashBlade® provides a standard data platform with Unified Fast File and Object (UFFO) storage that supports various heterogeneous workloads from ML/HPC and modern applications that are part of single or multiple workflow pipelines. While vSAN file services can offer RWX access modes for HPC applications, FlashBlade provides capacity and performance scaling with distributed compute for massively parallel access from HPC applications with RWX access over a network file system (NFSv3).
The VMware Tanzu Kubernetes cluster supports several modern applications for a wide variety of use cases (Figure 2). Most of the applications use file access (network file system NFSv3/v4.1) to provide resiliency to the applications and make data shareable among end users.
Pure Storage Pure Service Orchestrator™ is an abstracted control plane that dynamically provisions persistent storage on-demand using the default or custom storage class used by the stateful applications running on the Tanzu Kubernetes cluster. By default, Pure Service Orchestrator supports storage classes that are pure-block for FlashArray™ and pure-file for FlashBlade. For the purpose of this blog post, the ML/HPC applications require the default or a custom file-based storage class to provision persistent storage on FlashBlade.
In this example, I’m using the Tanzu Kubernetes guest cluster hpc2-dev-cluster5 in the vSphere client that is used for the ML/HPC workload validations on FlashBlade using Pure Service Orchestrator.
The Tanzu Kubernetes cluster consists of three master and four worker VM nodes. I need to update the pod security policy in the Tanzu Kubernetes guest cluster hpc2-dev-cluster5 before installing Pure Service Orchestrator using helm. By default, Tanzu Kubernetes clusters don’t allow privileged pods to run. Run the following psp.yaml to create appropriate bindings.
Next, we’ll look at how to set up JupyterHub/notebook in the Tanzu Kubernetes cluster with the appropriate privileges to create a custom storage class in Pure Service Orchestrator that will provision persistent volumes (PVs) with RWX access modes.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 |
[root@sc2kubm101 ~]# kubectl vsphere login –server 172.30.12.1 –vsphere-username bikash@vslab.local –insecure-skip-tls-verify –tanzu-kubernetes-cluster-name hpc2-dev-cluster5 Password: WARN[0005] Tanzu Kubernetes cluster login: no namespace given, name (hpc2–dev–cluster5) may be ambiguous Logged in successfully. You have access to the following contexts: 172.30.10.1 172.30.11.1 172.30.12.1 demo demo–172.30.10.1 dev–cluster1 general–purpose1 general–purpose1–172.30.10.1 general–purpose2 general–purpose2–172.30.11.1 gp2–dev–cluster4 hpc2 hpc2–dev–cluster5 If the context you wish to use is not in this list, you may need to try logging in again later, or contact your cluster administrator. To change context, use `kubectl config use–context <workload name>` [root@sc2kubm101 ~]# kubectl config use-context hpc2-dev-cluster5 Switched to context “hpc2-dev-cluster5”. [root@sc2kubm101 ~]# kubectl get nodes NAME STATUS ROLES AGE VERSION hpc2–dev–cluster5–control–plane–6mrpz Ready master 119d v1.16.8+vmware.1 hpc2–dev–cluster5–control–plane–lc79b Ready master 119d v1.16.8+vmware.1 hpc2–dev–cluster5–control–plane–mtfq4 Ready master 119d v1.16.8+vmware.1 hpc2–dev–cluster5–workers–wc8sg–656f68bc4c–6tsbp Ready uc–master 119d v1.16.8+vmware.1 hpc2–dev–cluster5–workers–wc8sg–656f68bc4c–b25nr Ready uc–worker 119d v1.16.8+vmware.1 hpc2–dev–cluster5–workers–wc8sg–656f68bc4c–j2qj6 Ready uc–worker 119d v1.16.8+vmware.1 hpc2–dev–cluster5–workers–wc8sg–656f68bc4c–jkzb7 Ready uc–worker 119d v1.16.8+vmware.1 [root@sc2kubm101 ~]# kubectl apply -f psp.yaml [root@sc2kubm101 ~]# cat psp.yaml apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: psp:privileged rules: – apiGroups: [‘policy’] resources: [‘podsecuritypolicies’] verbs: [‘use’] resourceNames: – vmware–system–privileged —– apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: all:psp:privileged roleRef: kind: ClusterRole name: psp:privileged apiGroup: rbac.authorization.k8s.io subjects: – kind: Group name: system:serviceaccounts apiGroup: rbac.authorization.k8s.io |
Version 6.0x of Pure Service Orchestrator is stateful and has a database of its own. The database stores metadata about name, size, NFS endpoints, and NFS export rules for file systems created by Pure Service Orchestrator on FlashBlade. Version 6.0.x allows you to provision PVs with a generic set of NFS export rules in the values.yaml or create a custom storage class with specific export rules that apply to certain ML/HPC applications. The following table has “noatime” added as the export rule in the values.yaml for all the PVs provisioned by Pure Service Orchestrator on FlashBlade.
|
1 2 3 |
flashblade: snapshotDirectoryEnabled: “false” exportRules: “*(rw,no_root_squash,noatime)” |
After successfully installing Pure Service Orchestrator in its namespace “-pure-csi,” all the database pods and the pso-csi driver are running on the cluster nodes.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
[root@sc2kubm101 ~]# kubectl get pods -n pure-csi NAME READY STATUS RESTARTS AGE pso–csi–controller–0 6/6 Running 3 28d pso–csi–node–5f4v2 3/3 Running 2 28d pso–csi–node–9g7r8 3/3 Running 0 7d1h pso–csi–node–bqsm7 3/3 Running 0 6d17h pso–csi–node–pn2wc 3/3 Running 0 6d23h pso–db–0–0 1/1 Running 0 28d pso–db–1–0 1/1 Running 0 28d pso–db–2–0 1/1 Running 0 28d pso–db–3–0 1/1 Running 0 28d pso–db–4–0 1/1 Running 0 28d pso–db–cockroach–operator–74b57ffc49–dctcn 1/1 Running 0 28d pso–db–deployer–d47d666f6–kdlj9 1/1 Running 0 28d tkg–mysql2–7fdb9b5989–6x8z6 1/1 Running 1 28d [root@sc2kubm101 ~]# |
By default, applications using the default storage class pure-file mount the PV over NFSv4.1.
|
1 2 3 4 5 6 7 8 9 10 |
[root@sc2kubm101 ~]# kubectl get sc NAME PROVISIONER AGE performanceflash csi.vsphere.vmware.com 111d pure–block pure–csi 28d pure–file (default) pure–csi 28d [root@sc2kubm101 ~]# kubectl exec -it tkg-mysql2-7fdb9b5989-6x8z6 -n pure-csi — bash root@tkg–mysql2–7fdb9b5989–6x8z6:/# 172.16.31.44:/hpc2_dev_cluster5–pvc–b6371eef–9d3b–4ab6–aa65–a6c9333e18f6 on /var/lib/mysql type nfs4 (rw,relatime,vers=4.1,rsize=524288,wsize=524288,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.246.0.228,local_lock=none,addr=172.16.31.44) root@tkg–mysql2–7fdb9b5989–6x8z6:/# |
However, most of the HPC applications would use NFSv3 to mount the file systems from FlashBlade. A custom storage class “pure-file-v3” is created with the NFS-mount option set to version 3 and the default storage class.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
[root@sc2kubm101 ~]# cat pure-file-v3.yaml kind: StorageClass apiVersion: storage.k8s.io/v1 metadata: name: pure–file–v3 labels: kubernetes.io/cluster–service: “true” provisioner: pure–csi parameters: backend: file mountOptions: – nfsvers=3 – tcp [root@sc2kubm101 ~]# [root@sc2kubm101 ~]# kubectl patch storageclass pure-file-v3 -p ‘{“metadata”: {“annotations”:{“storageclass.kubernetes.io/is-default-class”:”true”}}}’” storageclass.storage.k8s.io/pure–file–v3 patched [root@sc2kubm101 ~]# [root@sc2kubm101 ~]# kubectl get sc NAME PROVISIONER AGE performanceflash csi.vsphere.vmware.com 119d pure–block pure–csi 36d pure–file pure–csi 36d pure–file–v3 (default) pure–csi 36d [root@sc2kubm101 ~]# |
Now the Tanzu Kubernetes cluster is ready to install stateful ML/HPC applications like JupyterHub/notebook to be configured on FlashBlade using Pure Service Orchestrator. You can add other applications for monitoring and alerting, log analytics, and more to the Jupyter-as-a-service pipeline.
The table below shows how Jupyter proxy service can automatically pick up an external IP address. The NSX, which is part of vSphere 7, provides the external IP address. You don’t need an external load balancer like MetalLB for Tanzu Kubernetes cluster.
The persistent volume claims (PVC) for different users starting the Jupyter notebook is set to RWX access mode and uses the default storage class “pure-file-v3” while provisioning persistent storage on the FlashBlade.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
[root@sc2kubm101 ~]# kubectl get svc NAME TYPE CLUSTER–IP EXTERNAL–IP PORT(S) AGE kube–state–metrics ClusterIP 198.49.232.236 <none> 8080/TCP 33d hub ClusterIP 198.53.237.213. <none> 8081/TCP 29d proxy–api ClusterIP 198.56.136.151. <none> 8001/TCP 29d proxy–public LoadBalancer 198.57.110.121 172.30.12.15 80:32366/TCP,443:32173/TCP 29d [root@sc2kubm101 ~]# kubectl get pvc NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE claim–aaron Bound pvc–7a79e396–257e–4701–a86b–83090478bdc0 10Gi RWX pure–file–v3 29d claim–abigail Bound pvc–57621903–d653–11e9–88a1–42e29549f3f7 10Gi RWX pure–file –v3 29d |
End users like data scientists using the Jupyter notebook create their own persistent work area on FlashBlade using Pure Service Orchestrator. Jupyter-as-a-Service on Tanzu Kubernetes on CPUs allows data scientists to qualify the preliminary exploration and validation of the data-intensive ML/HPC pipelines before they move to more specialized hardware like GPUs.
Monitoring, alerting, log analytics, and other HPC applications could be an addition to the ML/HPC pipeline where you can store, reuse, and share data on FlashBlade using Pure Service Orchestrator. In the next part of this blog series, I’ll highlight the use of monitoring and alerting tools like Prometheus and Grafana on the Tanzu Kubernetes cluster and FlashBlade.
For more information on Tanzu Kubernetes for ML/HPC applications and Pure Storage FlashBlade using Pure Service Orchestrator, be sure to check out my VMworld 2020 session: Modernize and Optimize ML/AI/HPC Applications with vSphere Tanzu (HCP1545).
Evergreen Solutions
Check out our new Evergreen Portfolio! It is custom-fit to meet the needs of your business.



