

はじめに
ピュア・ストレージ・ジャパンは、お客様のデジタル変革を支援する取り組みの一環として、技術セミナー「The Orange Ring – Tech」を開催しています。2019 年 10 月 11 日に開催された第 6 回のテーマは「AI(人工知能)」。『AI/ビッグデータをビジネスにどう活かしていくか、そのインフラとは』と題し、注目されている AI 領域で、オールフラッシュ・ストレージがどのように活躍するのかを、わたくし蒋 逸峰(Yifeng Jiang)が解説しました。本稿では、当日講演した内容を抜粋してご紹介します。
AI の能力はデータ量によって決まる
近年、AI は非常に早いスピードで進化をし続けています。チェスや碁、クイズといったゲームの領域や、暗記や算術といった学術の領域では、AI のほうが優れた成績を収めています。また、画像認識や音声認識、翻訳や投資、定理検証などの領域でも、AI は人間に匹敵する、あるいは人間を超えた能力を発揮するようになっています。
例えば、人間が 2 千年以上も続けてきた碁には、“定石” と呼ばれる共通のベスト・プラクティスが存在しています。ところが、Google DeepMind が開発した囲碁プログラム「AlphaGo」は、登場からわずかな時間で、これまでにはなかった新定石(新手)を打ち出して世界中を圧倒しました。碁という限られた世界とはいえ、AI は大きな成果を生み出すようになったのです。

米マッキンゼー・アンド・カンパニーは、AI の生み出す価値が 2030 年には 13 兆ドル(約 1, 400 兆円)に達すると予測しています。あらゆる企業がその価値の恩恵を受ける可能性があると、容易に想像することができます。
こうした価値を受け取るために、上司から「どうやって AI をプログラミングするの?」と質問されるかもしれません。しかし、AI とは広い概念を表す言葉であって、AI をプログラミングすることはできません。
AI に関連する用語は、機械学習といった AI の中心をなす技術から、さまざまに細分化された仕組みや手法まで多岐にわたります。例として、以下にいくつかの用語を階層にして表してみます。
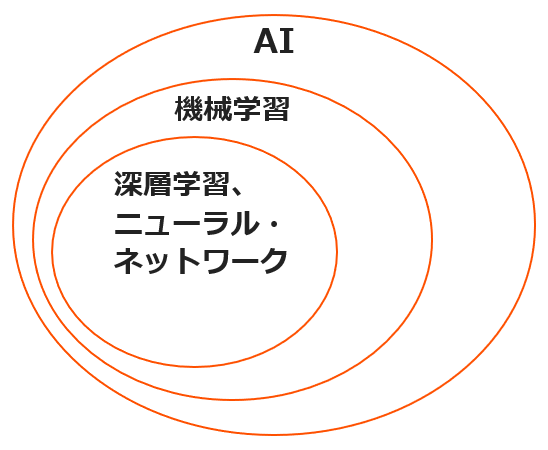
上記の「どうやって AI をプログラミングするの?」という質問のケースでは、「機械学習モデルはどのようにトレーニングするの?」というように聞くのがよいでしょう。
では、機械学習を実践する例として、家を貸し出すときの賃料を決める “手法” を導きだす方法をご紹介します。
- 従来(人間)の手法
- 部屋の広さやバスルームの数などによって賃料のルールを決める
- それに従って数式(プログラム)書く
- 機械学習
- 賃料と条件のサンプルデータ(教師データ)を基に学習させる
- 賃料を算出する数式(モデル)を作る
このように、機械学習では従来の手法とはまったく異なるアプローチを採っていることがわかります。
機械学習とは、言うなればインプットとアウトプットをマッピングする手法です。顔認証では顔と ID を、スマート・スピーカーでは声と命令をマッピングします。音声のテキスト変換や、自動運転も同様です。
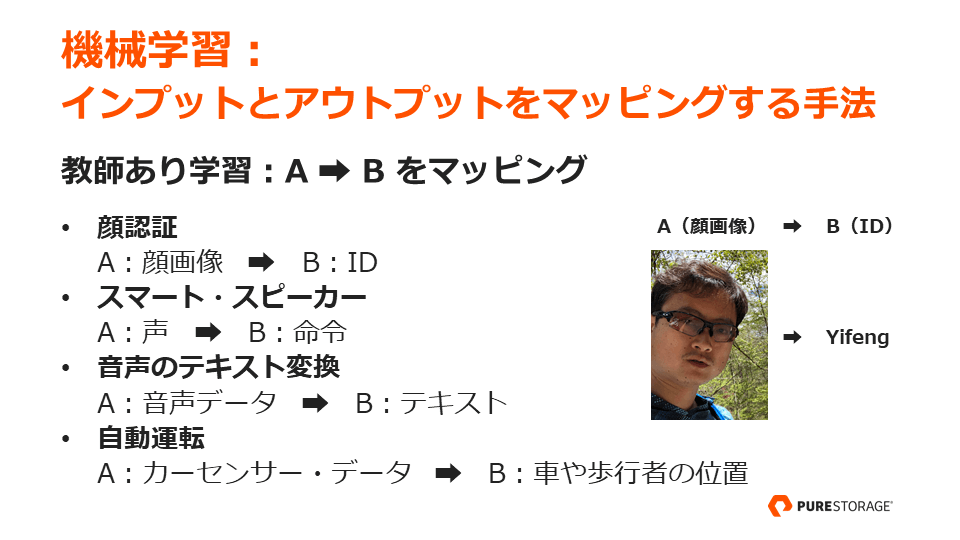
機械学習技術の中でも深層学習は、その方法を人間に真似た技術です。小さなニューロンをたくさん集めて複雑な処理を行う脳のように、細かなレイヤーを重ねてマッピングを行っています。データ量が多く計算能力が高ければ AI の精度が上がり、一定以上になれば人間の能力を超えるというわけです。
しかし一方で、比較的シンプルな少数レイヤーの深層学習であっても、膨大な数の教師データが必要になることがわかっています。膨大なデータを集めてラベル付けを行うことで、初めてトレーニングが可能になります。精度の高いモデルができあがったら、ようやくデプロイできるのです。もちろん環境などの条件が変われば精度が劣化するため、再学習したり再構築したりする必要があります。
AI プロジェクトを加速するデータハブ ─ FlashBlade
「AI をやろう」と思って AI に取り組む企業はありません。組織が抱える課題を解決したり、目標を達成するために AI を実践するのです。まずは、“ビジネス上の課題” を明らかにし、その解決のためにはどのようなデータが必要かという点を考えます。その後、トレーニングしてモデルを開発、デプロイし、ソリューション化します。そうして “データ/AI 駆動型ビジネス” が実現したのちも、精度を維持するためにモデルの開発サイクルを繰り返すのです。
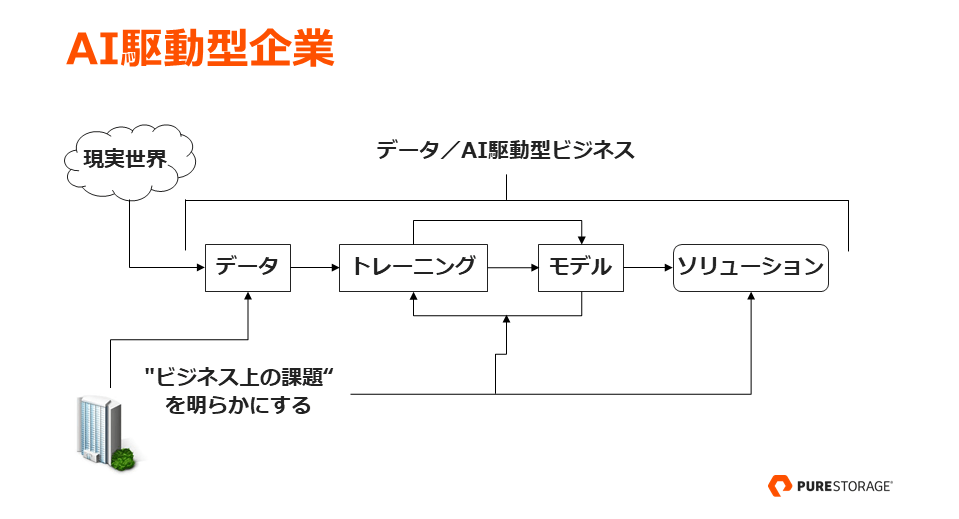
“AI 企業” になるには、インターネットの 20 年の歴史から学ぶことができます。インターネットで成功した企業は、インターネットのメリットや考え方をビジネス、プロセスに取り込んで活用してきました。AI も同様です。具体的には、データ収集戦略や共通のデータハブを持つことが重要です。
インターネット時代
ショッピングモール + ウェブサイト ≠ インターネット企業
- A/B テストの実施
- アジャイル/高速反復処理
- エンジニアおよび専門家主導の意思決定
AI 時代
企業 + 深層学習 ≠ AI 企業
- 戦略的なデータ収集
- 1 つに統合されたデータハブの活用
- 自動化の普及
- 役職(MLE – Machine Learning Engineer、 CAIO – Chief AI Officer)と部署を新設
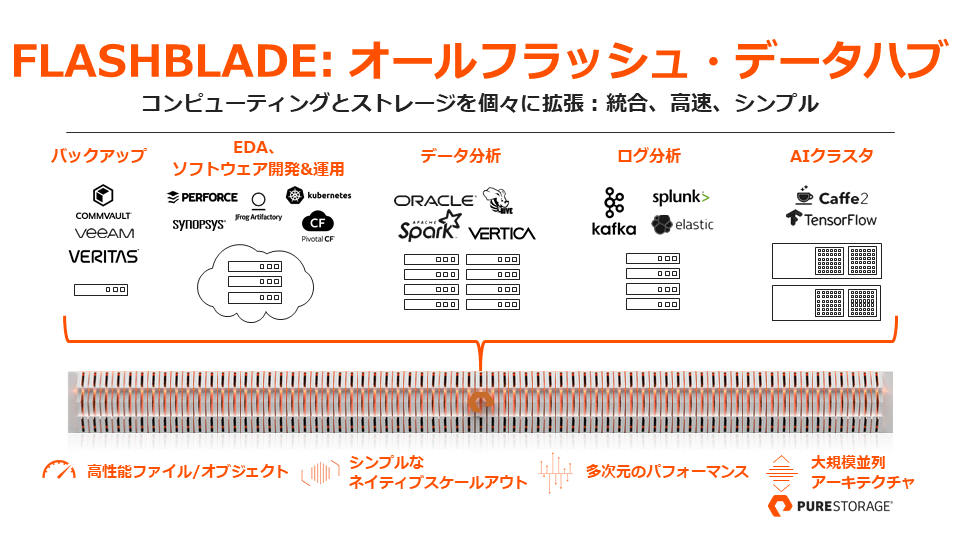
データソースがサイロ化されて、あちこちに散在するような状況では、データを活用するのは難しいことです。それがもし、ただ 1 つの共通基盤/ストレージにデータが統合され、それらを活用するパイプラインが存在するとしたら。もし、さまざまなアプリケーションから簡単にデータを利用できて管理にも手間がかからないとしたら。その結果は、データソースから AI モデルを開発するまでの流れが非常にスムーズになることでしょう。
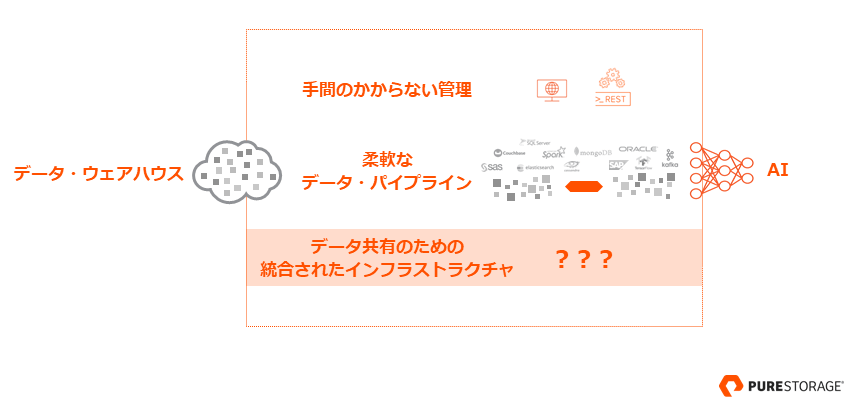
従来は、さまざまなワークロードがさまざまな要件を持っていたために、ストレージを統合することは困難でした。全ての要件を満たすには、高いスループットとスケーラビリティ、ランダムでもシーケンシャルでも高い性能を示し、大量の同時アクセスも並列でさばけなければなりません。そうしたストレージが、Oracle でも Spark でも、ElasticSearch でも TensorFlow でも共通して利用できるデータハブとなりうるのです。これこそが、ピュア・ストレージの「FlashBlade」 が目指す方向です。
“数十ものデータ・ウェアハウス” を 1 つに、“数十もの管理チーム” を 1 つに、膨大な数のサーバーやハードディスク、IP アドレスやケーブルを 1 つの FlashBlade とコンピューティング・プールにまとめることが可能です。すでにさまざまなユーザー様に、FlashBlade をデータハブとして活用いただいています。
AI トランスフォーメーション・プロジェクトは、大きく 5 つのステップで進行します。
- パイロット・プロジェクトを実行して弾みを付ける
- 内製の AI チームを形成する
- 幅広い AI トレーニングを提供する
- AI 戦略を策定する
- 内外のコミュニケーションを開発する
ほとんどの組織は、上記のステップ 1 または 2 の段階にあり、今からスタートしても十分に間に合います。
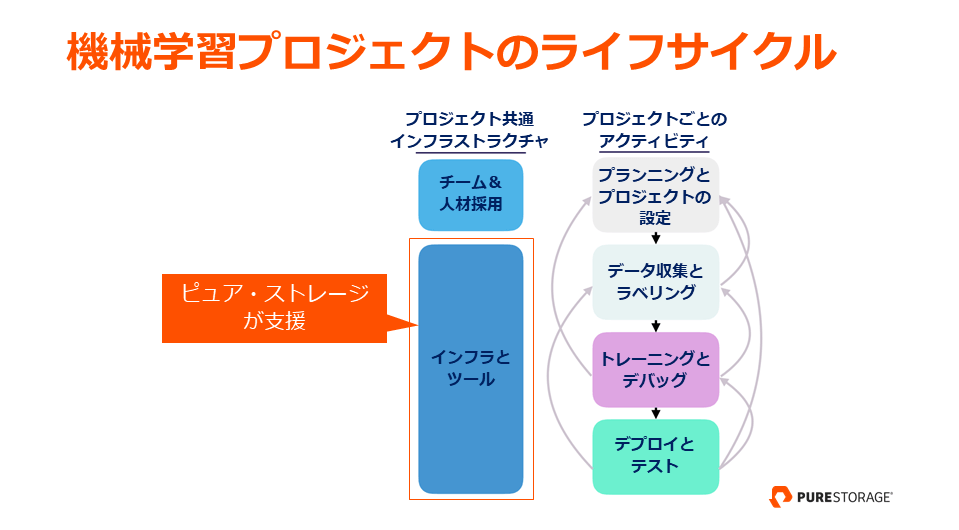
まず大切なことは、最初のパイロット・プロジェクトで何らかの成功事例を作り、社内の動きを活発化することです。大きなインパクトを得られるプロジェクトを狙わなければなりませんが、それが実行可能かどうかを見極めることも重要です。また、プロジェクトのコストは、第一にデータの入手難易度、第二に目標とする精度によって左右されます。
実施するプロジェクトが決まれば、下図の右側にある “プロジェクトごとのアクティビティ” のサイクルを繰り返します。このサイクルを効率的に回すには、プロジェクト共通のインフラとツールが必要となります。ピュア・ストレージが支援しているのは、この部分です。
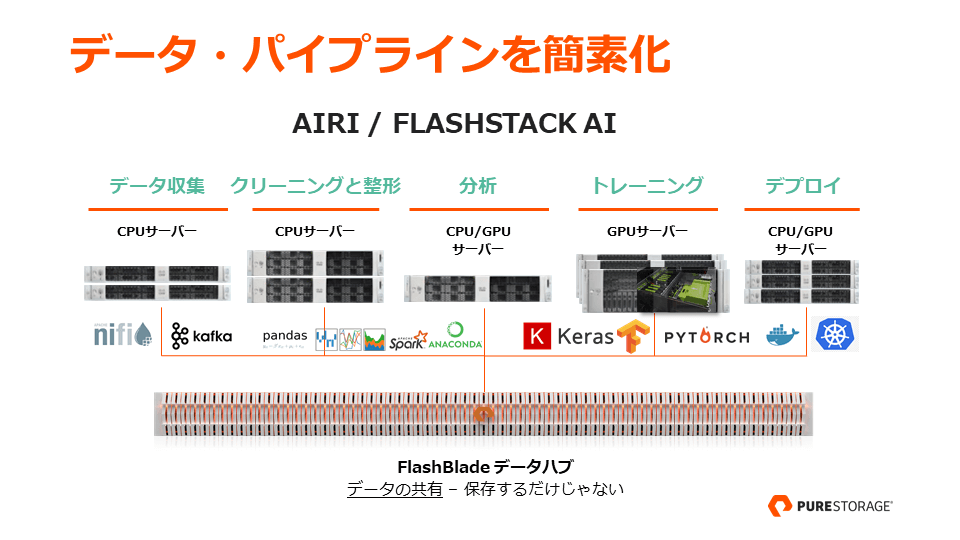
AI に取り組む多くの組織では、いまだにモデル開発の段階ごとに、データのコピーと移動を実施しています。これを解決するのが、ピュア・ストレージの FlashBlade データハブです。データ収集、クリーニングと整形、分析、学習(トレーニング)、デプロイに至るまで、1 台の FlashBlade に統合できるのです。ユーザーが AI や分析に集中できるように、使いやすくて信頼性が高く、そこにあるのを忘れられるデータハブとなることが目標です。
大規模な AI プロジェクトも AIRI が強力に支援
AI モデルを作るには、強力な計算能力が必要です。貧弱なインフラで 1 年以上かけて作ったモデルが、使い物になるかどうかは試してみないとわからないというのでは問題外です。できるだけ早くモデルを開発し、試してみることが重要なのです。
そこでピュア・ストレージは、NVIDIA 社と共同で、AI 完全対応インフラストラクチャ「AIRI」を開発しました。FlashBlade と NVIDIA DGX-1/DGX-2 サーバーを組み合わせて、あらゆる企業の大規模な AI 活用をサポートする強力なプラットフォームです。両社の検証済みであるため、安心して迅速に利用を開始できます。

AI インフラストラクチャに FlashBlade を採用することで、データコピーを排除でき、高速な GPU メモリのボトルネックになることもありません。複数の GPU サーバーから分散トレーニングを行うことも可能です。非常に高い可用性を維持し、高密度で低消費電力、シンプルな構成と管理ツールでの運用も容易です。「Evergreen Storage」でダウンタイムなしにアップデートでき、データの移行作業やオフライン・アップグレードも不要になります。
さらに、FlashBlade の能力を最大化する「RapidFile ツールキット」も提供しています。膨大なデータの探索を高速化し、データ・パイプライン全体で最高のパフォーマンスを発揮するためのツールです。また、AI モデルのデプロイ先のコンテナ環境で、STaaS(Storage as a Service)を実現する「Pure Service Orchestrator」も有用です。FlashBlade という 1 つの共通インフラストラクチャで、簡単かつ高速に AI を実践できるようになるのです。
おわりに
The Orange Ring – Tech の今後の開催スケジュールはただいま調整中です。決定しだい、本ブログ、ピュア・ストレージの Web サイトおよび Facebook でご案内いたします。
The Orange Ring – Tech ブログシリーズ
第 1 回 新しいストレージのカタチ ─ 高速堅牢なオールフラッシュをクラウドライクに利用する
第 2 回 イマドキのストレージ設計 ─ 容量・性能はどう決める?
第 3 回 データ保護の最後の砦 ー バックアップの考え方
第 4 回 目標は簡素、実効は複雑なストレージマイグレーション
第 5 回 NVMe を最大限に活かすストレージ・ネットワーキングとは
Pure Storage、Pure Storage のロゴ、およびその他全ての Pure Storage のマーク、製品名、サービス名は、米国およびその他の国における Pure Storage, Inc. の商標または登録商標です。その他記載の会社名、製品名は、各社の商標または登録商標です。



