

This introduction to the components of Kubernetes cluster networking is the fifth post of a multi-part series by Bikash Choudhury and Emily Watkins, where we discuss how to configure a Kubernetes-based AI Data Hub for data scientists. See the previous posts in the series, Visualizing Prometheus Data with Grafana Dashboards for FlashBlade™, Providing Data Science Environments with Kubernetes and FlashBlade, Storing a Private Docker Registry on FlashBlade S3, and Scraping FlashBlade Metrics Using a Prometheus Exporter.
Networking is a critical component in any Kubernetes cluster setup. A typical Kubernetes cluster consists of pods with one or more containers running on a single or multiple virtual machines (VMs) or bare metal nodes. Containers communicate amongst themselves inside a pod, between pods on the same host, and across hosts to services.
By default, in a private datacenter deployment, Kubernetes provides a flat network without NAT (Network Address Translation). CNI plugins like Calico and Flannel provide secured network policies and network connectivity options for unified networking solutions. Without network-based policies provided by these plugins, multi-user environments–like those in AI/ML workloads–are not scalable due to the limited number of network connections available by default.
Container Network Interfaces (CNI) is a standard that is created to interface between container runtime and the rest of the network implementation on the host to communicate between pods and across hosts in the Kubernetes cluster. CNI plugins allow attaching and detaching containers to the network without restarting the network.
There are many CNI plugins supported by Docker–like Flannel, Calico, Weave, and Canal. Canal is a popular choice in a Kubernetes cluster for on-prem workloads.
Canal is a combination of Calico and Flannel. Both of those parent plugins use an overlay network across all the nodes in the Kubernetes cluster. Flannel provides a simple overlay Layer 2 (L2) network that encapsulates data and tunnels over Layer 3 (L3) as shown in the above diagram. This reduces network complexities without much additional configuration. Calico enforces network rule evaluations on top of the networking layer using IP tables, routing tables etc. for more security and control.
In this deep-dive blog post, we walk through the components of an example configuration. The goal of this post is to orient readers to the key components they will configure as they create their own customized cluster network.
This post uses some real examples to illustrate the network flow in three different sections:
- Network communication path for single container
- Pod communication with a CNI plugin
- Network configuration of a Kubernetes Service
Because network requirements are highly variable, organizations are likely to have varied implementations and there are many networking solutions available. This post attempts to decode the network stack of a Kubernetes cluster using Docker containers on a flat network using a CNI plugin called Canal.
Example Network Communication Path for Single Container
Note: in preparation for Kubernetes installation, some basic networking rules should be followed to minimize cluster complexity.
- Utilize a flat, public IP range to configure all the nodes in the cluster. Avoid any network hops between the cluster nodes.
- Utilize a flat, private IP range for internal communication for the Kubernetes pods.
- Reserve an IP range for Docker containers and the Docker bridge.
a. Manually set up a gateway IP for the docker0 bridge.
In our /etc/docker/daemon.json file on each node, we have set up an IP network to the default Docker bridge (docker0) that works as a gateway for the containers.
|
1 2 3 4 5 6 |
[root@sn1–r720–g09–13 ~]# cat /etc/docker/daemon.json { “bip”: “172.17.0.5/16”, “fixed-cidr”: “172.17.0.5/17” ] } |
The following diagram illustrates a single docker container network flow. The eth0 inside the container is paired with a virtual ethernet (veth) that talks to the default Docker bridge, docker 0. Then docker0 uses the –net=host setting to forward the packets to the external world.
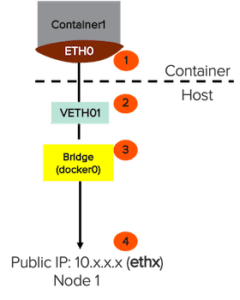
Let us now analyze the network flow for a docker container named “busybox” as an example.
The container is a process running on a host (VM or bare metal) and has its own Process ID (PID).
|
1 2 3 |
[root@sn1–r720–g09–13 ~]# docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 52496a722339 busybox–image “sh” 2 months ago Up 2 months busybox |
The following commands check the internal IP address assigned to the busybox container and then use it to examine the routing table, which describes how the container communicates with the bridge docker0.
|
1 2 |
[root@sn1–r720–g09–13 ~]# docker inspect -f ‘{{range .NetworkSettings.Networks}}{{.IPAddress}}{{end}}’ busybox 172.17.0.6 |
|
1 2 3 4 5 |
[root@sn1–r720–g09–13 ~]# docker exec -it busybox route -n Kernel IP routing table Destination Gateway Genmask Flags Metric Ref Use Iface 0.0.0.0 172.17.0.5 0.0.0.0 UG 0 0 0 eth0 172.17.0.0 0.0.0.0 255.255.0.0 U 0 0 0 eth0 |
With the network configured with the recommendations listed above, the veth can establish a connection with docker0.
|
1 2 3 |
[root@sn1–r720–g09–13 ~]# brctl show bridge name bridge id STP enabled interfaces docker0 8000.02422d46c5ed no veth3f80d9c6c5ed no veth3f80d9c |
Use “docker inspect” to identify the PID for the busybox container. (Note: using “ps” to find the PID will only show the external PID for the parent docker process.)
The following steps show how the busybox container uses the veth3f80d9c to reach the bridge docker0.
|
1 2 |
[root@sn1–r720–g09–13 ~]# docker inspect –format ‘{{ .State.Pid }}’ busybox 435 |
The following sequence of commands identifies how the busybox PID is mapped to the veth3f80d9c and connects to docker0.
|
1 2 3 4 5 |
[root@sn1–r720–g09–13 ~]# nsenter -t 435 -n ip addr 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever |
|
1 2 3 4 |
219574: eth0@if219575: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default link/ether 02:42:ac:11:00:01 brd ff:ff:ff:ff:ff:ff link–netnsid 0 inet 172.17.0.6/16 brd 172.17.255.255 scope global eth0 valid_lft forever preferred_lft forever |
|
1 2 3 4 5 |
[root@sn1–r720–g09–13 ~]# ip a 219575: veth3f80d9c@if219574: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master docker0 state UP group default link/ether 8a:d4:cb:dd:0d:c3 brd ff:ff:ff:ff:ff:ff link–netnsid 4 inet6 fe80::88d4:cbff:fedd:dc3/64 scope link valid_lft forever preferred_lft forever |
We can also trace the broadcast path. From within the busybox container, packet broadcast is ending at the “02:42:2d:46:c5:ed” MAC address.
|
1 2 |
[root@sn1–r720–g09–13 ~]# docker exec -it busybox arp -n ? (172.17.0.5) at 02:42:2d:46:c5:ed [ether] on eth0 |
And we can see that the MAC address corresponds to the Docker bridge, docker0.
|
1 2 3 4 5 6 7 8 9 |
[root@sn1–r720–g09–13 ~]# ifconfig docker0 docker0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 172.17.0.5 netmask 255.255.0.0 broadcast 172.17.255.255 inet6 fe80::42:2dff:fe46:c5ed prefixlen 64 scopeid 0x20<link> ether 02:42:2d:46:c5:ed txqueuelen 0 (Ethernet) RX packets 28 bytes 1960 (1.9 KiB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 10 bytes 684 (684.0 B) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 |
Once the busybox container is able to reach the bridge docker0, the –net=host setting allows the container to communicate to the external world using its host’s interface. In the following example; the Flashblade™ IP address 10.21.236.201 is pingable from within a busybox container.
|
1 2 3 4 5 |
[root@sn1–r720–g09–13 ~]# docker run –net=host -it busybox-image sh / # ping 10.21.236.201 |- Pure Storage Flashblade IP address PING 10.21.236.201 (10.21.236.201): 56 data bytes 64 bytes from 10.21.236.201: seq=0 ttl=63 time=0.200 ms 64 bytes from 10.21.236.201: seq=1 ttl=63 time=0.164 ms |
The initial docker container busybox setup on a single node is a quick test to check if the core network is functioning properly.
Pod Communication with a CNI Plugin
Now that we’ve illustrated the network communication path for single container, we’ll walk through the network communication path between pods. Pods are the basic Kubernetes objects that can be created, managed, and destroyed during the lifetime of an application.
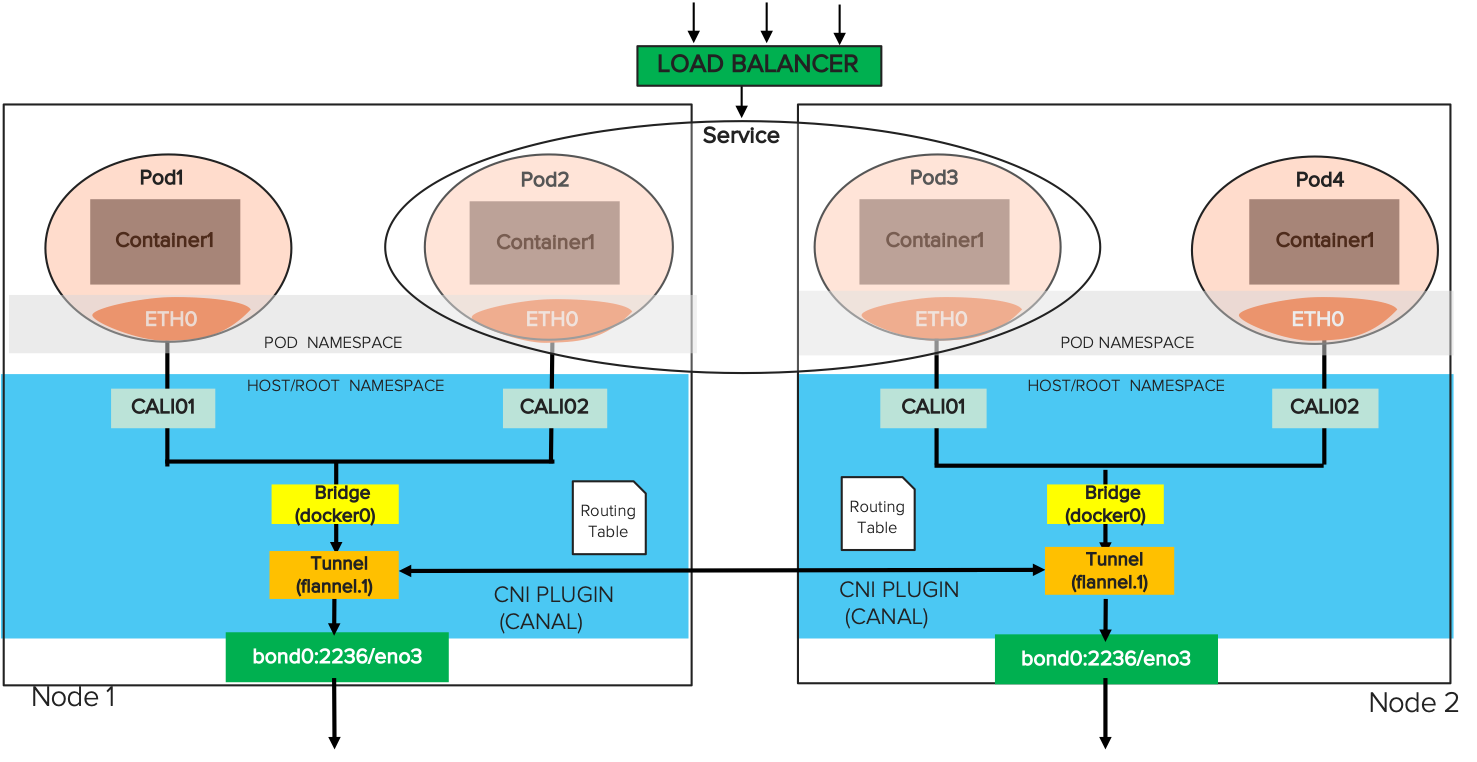
There are two parts to the namespace in Kubernetes networking – pod namespace (podns) and host or root namespace (rootns). The pod eth0 is part of the podns. The veth, the bridge docker0, routing tables, and the host port are part of rootns as shown in the diagram below. The nsenter command (short for “namespace enter”) is used to map the container PID to the veth in the podns and the rootns.

Example CNI usage:
An example pod, called “pure-exporter”, is used to scrape metrics from FlashBlade to Prometheus. (For more information on how the custom Pure exporter scrapes Flashblade metrics for Grafana dashboards, see this blog post.)
The pure-exporter pod’s veth is named cali65bb5da2c3b.
We can locate the pod’s internal pod IP address via:
|
1 2 3 |
$ kubectl describe pod pure–exporter–6c9dd7cc4d–cgxfg |grep IP |awk ‘{print $2}’ 10.42.6.25/32 10.42.6.25 |
As expected, the routing table shows the following:
- For the example pod, the veth cali65bb5da2c3b is paired with its IP address 10.42.6.25.
- The bridge docker0 that we configured earlier is paired with its gateway address 172.17.0.5.
We can also see additional routing components:
- The Flannel component of the Canal CNI uses flannel.1 as the overlay (tunnel) to communicate to the six other pods in the network.
- The eno3 physical interface is part of the bond0.2236 VLAN and is responsible for physical packet transfer over the network.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
[root@sn1–r720–g09–13 ~]# route -n Kernel IP routing table Destination Gateway Genmask Flags Metric Ref Use Iface 0.0.0.0 10.21.236.1 0.0.0.0 UG 102 0 0 eno3 0.0.0.0 10.21.236.1 0.0.0.0 UG 401 0 0 bond0.2236 10.21.236.0 0.0.0.0 255.255.255.0 U 102 0 0 eno3 10.21.236.0 0.0.0.0 255.255.255.0 U 401 0 0 bond0.2236 10.42.0.0 10.42.0.0 255.255.255.0 UG 0 0 0 flannel.1 10.42.1.0 10.42.1.0 255.255.255.0 UG 0 0 0 flannel.1 10.42.2.0 10.42.2.0 255.255.255.0 UG 0 0 0 flannel.1 10.42.3.0 10.42.3.0 255.255.255.0 UG 0 0 0 flannel.1 10.42.4.0 10.42.4.0 255.255.255.0 UG 0 0 0 flannel.1 10.42.5.0 10.42.5.0 255.255.255.0 UG 0 0 0 flannel.1 10.42.6.25 0.0.0.0 255.255.255.255 UH 0 0 0 cali65bb5da2c3b 172.17.0.5 0.0.0.0 255.255.0.0 U 0 0 0 docker0 192.16.0.0 0.0.0.0 255.255.255.0 U 400 0 0 bond0.1116 [root@sn1–r720–g09–13 ~]# |
Network configuration of Services
The Pure exporter is one of the services we have running in our cluster:
|
1 2 3 4 5 |
$ kubectl get svc NAME TYPE CLUSTER–IP EXTERNAL–IP PORT(S) AGE kubernetes ClusterIP 10.43.0.1 <none> 443/TCP 121d pure–exporter ClusterIP 10.43.175.87 <none> 9491/TCP 6d6h pure–exporter–nodeport NodePort 10.43.127.127 <none> 9491:31175/TCP 6d6h |
The pure-exporter service uses a Nodeport service to map internal port 9491 to the host port 31175 to communicate for external communication.
A container in a pod is ephemeral when the pod is destroyed. However, applications are able to be persistent by using an abstraction called a “service” that logically groups a set of pods that are accessible over a network. While pods are the back end that spin up and down, services are the front-end process that is always alive and provides persistence during the life of the application.
Load Balancer
In addition to the Nodeport, a load balancer provides an external IP address to every service in the Kubernetes cluster for clients and end-users outside the cluster to access the application using HTTP (or HTTPS) as shown in the diagram below.
Metallb is one of the most popular load balancers used in on-premise Kubernetes clusters. Applications in Machine Learning pipelines with multi-user access benefit from using a load balancer to distribute the workload across nodes. In this example, we’ll use Metallb to balance traffic for our Jupyterhub-as-a-Service.
The Metallb configmap should include a predefined IP address pool that automatically assigns public IPs to the services and advertises them in the network.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
$ cat metallb–config.yaml apiVersion: v1 kind: ConfigMap metadata: namespace: metallb–system name: metallb–config data: config: | address–pools: – name: default protocol: layer2 addresses: – 10.61.169.60–10.61.169.79 |
The proxy-public service picks a public IP address with Service type “LoadBalancer” after Jupyterhub after installed in the Kubernetes cluster.
|
1 2 3 4 5 6 7 8 |
$ kubectl get svc NAME TYPE CLUSTER–IP EXTERNAL–IP PORT(S) AGE hub ClusterIP 10.43.131.43 <none> 8081/TCP 10d kubernetes ClusterIP 10.43.0.1 <none> 443/TCP 170d proxy–api ClusterIP 10.43.141.245 <none> 8001/TCP 10d proxy–public LoadBalancer 10.43.64.136 10.61.169.60 80:31164/TCP,443:30138/TCP 10d pure–exporter ClusterIP 10.43.255.64 <none> 9491/TCP 156d pure–exporter–nodeport NodePort 10.43.95.229 <none> 9491:31252/TCP 156d |
Networking for our hosted Jupyter-as-a-Service is complete. For further steps on deploying the service, stay tuned for our upcoming Jupyterhub blog post.
Conclusion
Networking is core to any Kuberentes cluster and there are many different ways of building the network stack for applications running in a Kubernetes pod. It is recommended to get the basics right by using a flat network without introducing any layer of complexity. Load-distributing layers for TCP and HTTP requests respectively on Kubernetes can be possible with a strong and stable network layout.



