


Great news: Pure Storage® has partnered with Confluent to offer the first-ever on-premises tiered storage solution for streaming data. Confluent Tiered Storage is a new architecture providing infinite retention and disaggregated compute and storage for Apache Kafka. Adding Pure FlashBlade®, an industry-leading S3-compatible flash-based fast file and object store to the Confluent architecture allows you to offer game-changing new capabilities, scale, and performance to your analytics users.
Your Data Pipelines Start with Apache Kafka
Data teams are pushing the limits on their data pipelines with real-time and predictive analytics. In a majority of these pipelines, the data starts its journey with Apache Kafka—the de facto standard for real-time event streaming and the second-most active Apache project in 2019. The developers who built Apache Kafka founded Confluent.
How Do You Keep Up with this Tsunami of Data?
Everyone knows that data, especially real-time and unstructured data, is growing exponentially. By 2025, IDC predicts that roughly 30% of the 175 zettabytes of data generated globally will be real-time. This massive growth in data requires a fundamental rethinking of data architectures due to the following issues:
More data means more servers. With today’s Kafka architecture, the data is distributed across direct-attached storage (DAS) on individual broker servers. As data grows, you add more brokers to keep up. More brokers mean longer upgrade times, more rebalancing, errors, and component failures over time.
Rebalancing is painful. When the data volume goes up or down, Kafka brokers need to be added or removed. Every time this is done the data needs to be rebalanced across all servers which may take several hours or even days affecting performance.
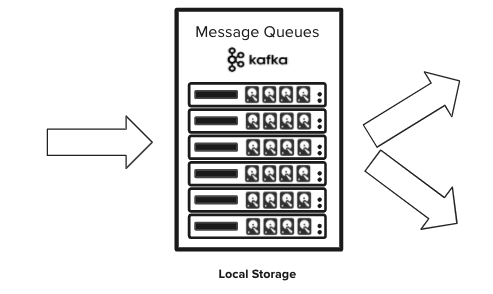
Figure 1: Direct-attached storage architecture for Apache Kafka
Redundant data stores. With the massive growth in data, you cannot afford to store the same data in multiple systems. Data enters the pipeline through Apache Kafka and it makes sense to perform expensive tasks only once right at the entry point and send a smaller set downstream. It’s efficient to retain the bulk of the data in Kafka and then use it to power up real-time as well as historic analytics using ksqlDB. Further, the data in Kafka is immutable, which makes it ideal to comply with regulatory requirements.
To scale with today’s data needs and address these issues, Confluent made infinite storage architecture generally available as part of Confluent 6.0. When combined with the high-performance scale-out fast object storage capabilities of FlashBlade, the whole solution delivers a simpler, more reliable, and high-performance platform.
Read more about Confluent 6.0 in Ganesh Srinivasan’s blog post.
You can learn more about Tiered Storage in Confluent Platform in a post by Jun Rao, a cofounder of Confluent.
How Does the Pure and Confluent Tiered Storage Help?
As messages come into the Kafka brokers, the broker servers process and retain them for a short period of time. Once enough data accumulates, the brokers offload the data to tiered storage—Pure FlashBlade—freeing up space on the brokers. Replicas aren’t copied to the object store; instead, Kafka relies on the tiered storage backend for data protection. FlashBlade for example uses RAID-like parity encoding to reliably store data with low overheads. This means you can replace a dozen racks of spinning disks with half a rack of all-flash storage.
For a detailed walkthrough of the configuration steps, see Joshua Robinson’s technical blog.

Figure 2: Confluent Tiered Storage with Pure FlashBlade Unified Fast File and Object Store
Combining Pure FlashBlade with Confluent Tiered Storage offers three key benefits:
Superior Performance at Massive Scale
The Confluent Tiered Storage architecture, when combined with Pure FlashBlade, delivers the throughput and performance you need for massive-scale data pipelines. With an all-flash object store, you can get fast responses to your historical queries using ksqlDB. When the data needs to be read back into the brokers, superior IO throughput enables responses that are many magnitudes faster when compared to spinning disks. In our tests, we found that Pure FlashBlade provided 3x the throughput of the leading public cloud object-store.
For more details on the performance check out “Cloud-like flexibility and infinite storage with Confluent Tiered Storage and Pure Storage FlashBlade” from Marc Selwan.
Little to No Time Scaling Infrastructure
With Pure FlashBlade and Confluent Tiered Storage, you can greatly reduce the infrastructure complexity associated with your data pipelines. You’ll get:
- Simpler, scalable infrastructure: With the new architecture, the brokers don’t have to retain a large quantity of data or be sized based on storage. With FlashBlade’s high throughput and low-latency writes, data that needs to be retained can be quickly flushed out of the brokers and/or deleted. To expand the storage on FlashBlade, simply add a blade with no downtime or hassle. This frees up infrastructure to perform other compute-intensive tasks.
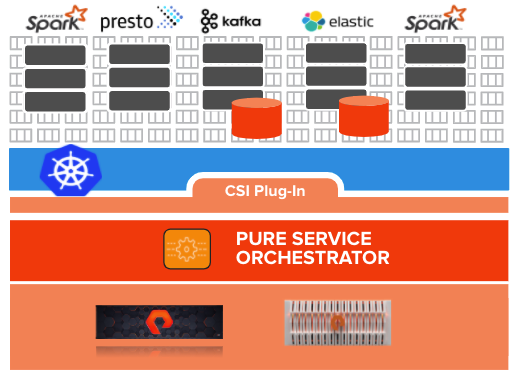
- Consolidated storage for your entire data pipeline: With a scale-out fast file and object store such as Pure FlashBlade, you can consolidate multiple Kafka clusters (production/dev-test) as well as data processed by multiple downstream applications, such as Splunk, Elasticsearch, Apache Spark, Vertica, and others on a single store.
Responsiveness to Business Needs
Generating business value from your data and analytics requires streamlined data pipelines on elastic, efficient, and agile infrastructure. With FlashBlade and Confluent, you:
- Get better elasticity. With Confluent self-balancing clusters, Pure Service Orchestrator™, and virtualization/containerization, you can scale up or down on-demand automatically and use resources an order of magnitude more efficiently.
- Pay only for what you use. With Pure as-a-Service™, you have the choice to use a 100% OPEX model to consume storage with a cloud-like model. With Pure’s Evergreen seamless, rapid upgrades and expansion, you don’t have to have everything planned out ahead of time.
- Leverage better TCO without compromising on performance. With efficient broker utilization, better data compression, and simplified management, you can reduce the overall total cost of ownership (TCO) without compromising on performance. You can also help save the planet by reducing power consumption with all-flash storage.
Keeping up with your growing data needs while shifting focus to delivering value to the business cannot be done with incremental improvements. The Confluent tiered architecture when combined with Pure’s FlashBlade resets your expectation on what real-time data pipelines can deliver. With all-flash performance, massive-scale real-time data processing, and a performant ksqlDB, you can keep complexity and costs in check.
Want to learn more about Pure Storage and Confluent? Don’t miss the webinar on Nov. 4, 2020 at 10AM PST. Register Now.
With Confluent and Pure FlashBlade, users can infinitely retain and elastically scale their Apache Kafka data simply, without compromising performance. Read the Solution Brief.



