

The fourth industrial revolution is upon us, powered by the rapid rise of artificial intelligence (AI) and machine learning. In the prior three revolutions, societies were transformed from rural to industrial to digital. The fourth revolution, powered by intelligent machines and services, is expected to transform our society yet again, giving rise to new industries while making many existing ones obsolete.

Blue River’s Lettucebot brings AI to farming, reducing use of pesticides while maximizing yield
The big bang of AI has been fueled by a perfect storm of three key technologies:
- Deep learning (DL): Deep learning is a new computing model using massively parallel neural networks inspired by the human brain. Instead of experts handcrafting software, a deep learning model writes its own software by learning from lots of examples.
- Graphics Processing Unit (GPU) processors: A GPU is a modern processor with thousands of cores, well-suited to run algorithms that loosely represent the parallel nature of the human brain. Both are major breakthroughs that have completely upended traditional approaches. As shown below, within just two years, the amount of compute required by leading deep learning algorithms jumped 15x while the compute delivered by GPUs jumped by 10x.
- Big data: The volume of unstructured data is exploding, legacy storage housing that data largely ceased innovating decades ago. Even though deep learning and GPUs are massively parallel, legacy storage technologies are not. They were designed in the past era of serial processing. And the performance gap between compute and storage continues to widen.

Compute required for deep learning training comparing Microsoft Resnet in 2015 to Google NMT in 2017. Compute delivered comparing Tesla M40 peak flops vs Tesla V100 peak flops.
If data is the new currency for the fourth industrial revolution, it is disconcerting to think that a system which is responsible for delivering the data would be based on decades-old building blocks. Slow storage means slow machine learning training performance, like compute jobs parched but trying to drink massive amounts of data through a thin straw, ultimately keeping insights locked in the data.
There is a great need for innovation, a new data platform that is reimagined from the ground-up for the modern era of intelligent analytics. Enter FlashBlade™.
FlashBlade Reflects the Soul of AI
FlashBlade is a revolutionary scale-out data platform, designed by Pure’s world-class engineers with a mission to build a new kind of storage system purpose-built for the massively parallel needs of AI. They challenged every legacy approach in order to build scale-out storage that is not only multi-PB big, but also super fast and simple to deploy and use. In the end, what we’ve engineered reflects the soul of deep learning.
A deep neural network is a massively parallel model, with millions to billions of neurons loosely connected together to solve a single problem. A GPU is a massively parallel processor built with thousands of loosely coupled compute cores to deliver 10x to 100x increase in performance over a CPU. FlashBlade, powered by Purity software, is also a massively parallel platform capable of delivering high performance access to billions of objects and files for 10s of thousands of clients in parallel.

Any AI platform must be massively parallel at the core of its design
In a 4U of rack-space of a 15-blade FlashBlade, 120 Xeon-D CPU cores and 45 FPGAs are interconnected with a state-of-the-art Elastic Fabric Module capable of 17 GB/s read throughput, 1.5M IOPS, all at low sub-3ms latency. But FlashBlade goes a lot bigger than 15 blades – it can be expanded all the way to 75 blades, delivering linear-scaling performance up to 75GB/sec read throughput, 25GB/sec write throughput, 7.5M IOPS at 8PB capacity (assuming 3:1 compression), all within half rack.
The 75 blade wide illustration is a great logical representation of how FlashBlade scales (and how your apps will perceive it), but that’s not how it gets deployed physically in your data center. They are actually deployed via five chassis of 15 blades each within standard rack mount as shown here.

The engine underneath the hood is the Purity for FlashBlade software. Designed as a massively distributed system, it is built on a scale-out key-value pair architecture that’s able to scale efficiently. The modern key-value store architecture is what enables thousands of parallel agents, each owning a piece of the global namespace and each self-optimizing to handle a wide range of file and object sizes (including very small files which are pervasive in AI use-cases), to deliver linear-scale performance.

Purity for FlashBlade is built on a modern key-value pair architecture for true scale-out performance
The Soul of FlashBlade is Parallel
The importance of an architecture that is parallel at its core cannot be understated. Deploying GPFS, Lustre, and other traditional HPC storage is like deploying hundreds of commodity CPU-based servers to run deep learning training. It can be done, and perhaps deliver the performance of a single NVIDIA® DGX-1, but why would anyone want to do that? Data scientists do not want to deal with data center infrastructure complexities, where hundreds of moving parts and cables will inevitably lead to failure somewhere in the system.
Like DGX-1, FlashBlade delivers unprecedented performance and efficiency, offering the IOPS performance of five thousand HDDs, or roughly 10 full racks of storage nodes. Pure did not invent scale-out storage; other vendors build retrofits with lots of commodity SSDs and HDDs. With FlashBlade, however, Pure made scale-out significantly more efficient and far less complex. At the core of FlashBlade is a sea of raw NAND flash, orchestrated by our DirectFlash technology, all working together in a unique, massively parallel architecture from hardware and software. And it’s this revolutionary architecture that accelerates modern analytics workloads.
The Tesla® Model S is purpose-built to use electricity. The Ferrari® 812 is purpose-built to be super-fast. When a system is purpose-built for a specific use case, it can yield jaw-dropping results. FlashBlade is purpose-built for modern data analytics workloads, like deep learning and Hadoop. The world’s leading information services and market intelligence company used to run its workloads on 20 racks of spinning disk. Today, all those racks have been replaced with a single 4U FlashBlade, saving significant money and time in power, cooling, rack space, uptime, and management. And unlike a Ferrari, FlashBlade enables companies of all sizes to affordably tackle analytics and begin leveraging AI in their business.
 Pure customer replaced 20 racks of mechanical disks with a single 4U FlashBlade
Pure customer replaced 20 racks of mechanical disks with a single 4U FlashBlade
Why Modern External Storage Is Required
Users often start their AI journey with a single, powerful computer, like the NVIDIA DGX-1. All the data is stored locally on direct attached storage (DAS) with SSDs. This setup is appropriate for practitioners experimenting with deep learning, testing various frameworks and networks. However, full potential of deep learning is realized with more and more data, when training datasets are not bounded to the limited capacity in a single computer. Professor Andrew Ng from Stanford University, a luminary in the field of AI, observed that DL sets itself apart from other learning algorithms in that model accuracy and performance continues to grow with larger training dataset.

Power of deep learning is unlocked with more data. Courtesy of Andrew Ng.
A model trained with 100TB dataset is more accurate than a model with 1TB dataset. A new generation of storage is required to deliver massive ingest bandwidth to the GPU systems for random access patterns of small to large files. Distributed DAS simply does not work for massive datasets.
Powering One of World’s Most Powerful AI Supercomputers
Interest in FlashBlade among AI customers has been tremendous. One of those customers is a leading global, web-scale company. They have built a large supercomputer, powerful enough to be among the world’s fastest systems, with racks of NVIDIA DGX-1 and Pure FlashBlade systems. This impressive system was carefully designed to accelerate deep learning training, optimally balancing system-wide performance with massive data ingest from FlashBlade to training computation with GPUs.
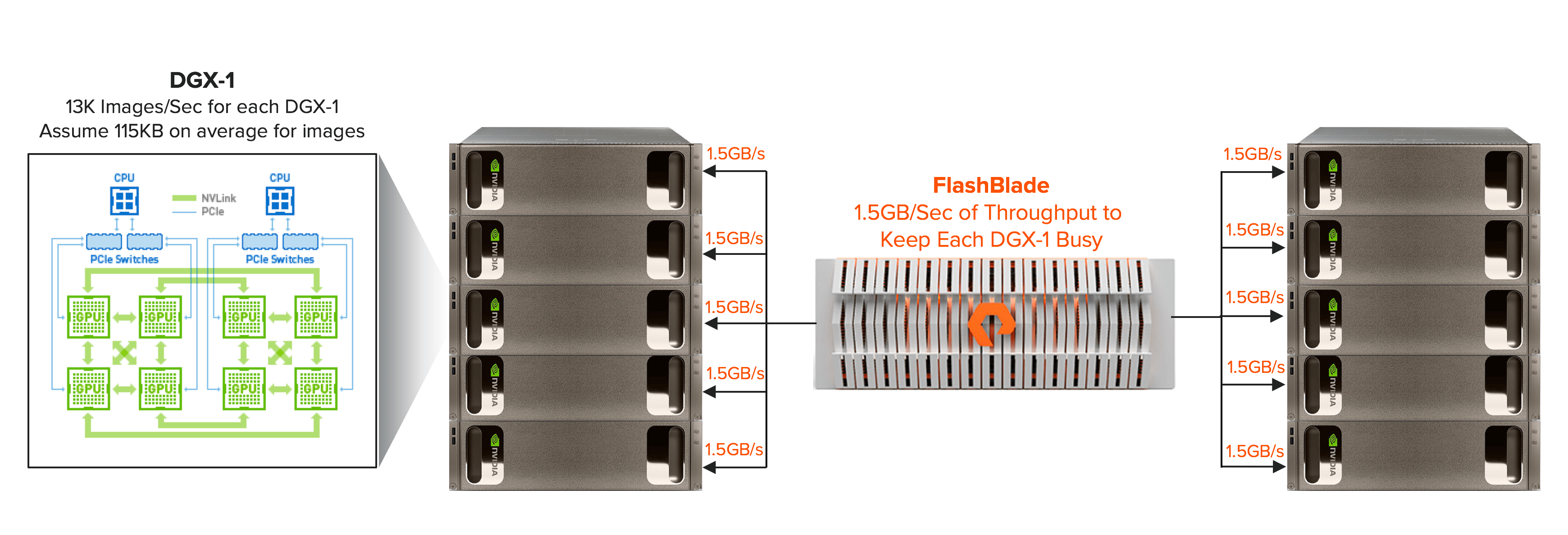
How FlashBlade feeds data into GPU systems like DGX-1 to keep deep learning training busy
When deploying a deep learning training cluster, system-level perspective is needed for a well-balanced solution. Let’s take an example (shown above) of DGX-1 systems running Microsoft® Cognitive Toolkit (formerly known as CNTK) framework using AlexNet. NVIDIA published results showing a DGX-1 can train at a throughput of 13K images per second. If images have an average size of 115KB, 10 DGX-1 has an ingest throughput requirement of 15 GB per second to keep the training job busy. Small-file read performance and IOPS are critical at this point, and can be the limiter in time to solution. For examples, if a storage system delivers half the throughput, data scientists will have to wait twice as long for the job to complete. The difference means the job could now be outside the bounds of what data scientists will now consider tackling, meaning potentially ground-breaking innovation and insights remain on the table.
Get Started with FlashBlade Today
FlashBlade is the ideal data platform for your deep learning workload. Like modern deep neural networks and GPU-accelerated systems, FlashBlade is massively parallel, scale-out, lightning fast, and dead simple to use. With its highly modular design, it grows with your training dataset as you ingest and curate more data, delivering linear performance and scale.
To learn more, please visit us here or contact us with any questions. We’d love for you to see how FlashBlade will enable new possibilities for your organization as you explore AI’s capabilities.
Stay tuned for part 2 of this blog series in which we will dig deeper into design principles of scale-out storage for AI workloads.
Written By:



