

Summary
Generative AI (GenAI) is one of the fastest-adopted technologies in history. Pure Storage is working with NVIDIA to bolster the power of GenAI for enterprise AI applications using retrieval-augmented generation (RAG).


Generative AI (GenAI) is one of the fastest-adopted technologies in history. But for boardrooms and business leaders to give it serious consideration, it has to prove its worth for enterprise use cases. How will it increase business, innovation, and operational velocity?
Pure Storage is working with NVIDIA to bolster the power of GenAI for enterprise AI applications using retrieval-augmented generation (RAG), with a demo this week live at NVIDIA GTC. Here’s a deep dive into how RAG can be used for large-scale, high-performance large language model (LLM) use cases.
The Value of Retrieval-augmented Generation
RAG enables enterprises to improve and customize general LLMs with external, more specific, and proprietary data sources. Right off the bat, this addresses key concerns with GenAI, making LLMs more accurate, timely, and relevant by referencing knowledge bases outside of those it was trained on.
One key concern is hallucination, a problem LLMs may suffer from, resulting in the generation of plausible but false responses. The consequences of an incorrect inference can result in poor economic analysis, trading, or investment recommendations. This can make it difficult to use the technology in a real-world setting where accuracy is business-critical. Introducing RAG can reduce the risk of hallucinations and provide analysts with better insights to act on.
Another concern is an LLM’s inability to incorporate new data that becomes available after a model’s initial and even subsequent training. RAG can readily incorporate the company’s latest data and knowledge into queries and answers, eliminating the need for constant retraining of LLMs.
Consider the highly regulated financial services sector where credibility, accuracy, and timeliness are crucial. Bolstering general financial LLMs with specific, customer, and proprietary vector databases can enhance the ability of financial institutions to train their own LLMs. External data from company financial statements, broker reports, compliance filings, and customer databases can provide more specific and meaningful analysis so that banks, trading, and investment firms can better serve their customers, enabling AI systems to generate timely investment insights, enhance compliance by verifying data sources, and mitigate risk.
Then, there’s the cost to build and train a proprietary LLM. RAG can help to spare enterprises the significant cost and resources required, making GenAI more applicable to businesses, especially from a return on investment standpoint.
Example: Building an AI-powered Knowledge Base
Here’s another industry use case: manufacturers that want to build an AI-powered knowledge system that uses product documentation, tech support knowledge bases, YouTube videos, and press releases to generate helpful, accurate answers for employees. AI-generated answers limited to nine-month-old public data are too limited to be valuable and cannot reference the company’s own product documents and videos.
Applying RAG allows the knowledge system to deliver customers and employees access to the most up-to-date information for reference and training, offering a multitude of opportunities for AI to improve operational, sales, and support processes.
Pure Storage Works with NVIDIA to Bring Retrieval-augmented Generation to the Enterprise
To simplify and speed up the RAG process, Pure Storage is working with NVIDIA to demonstrate a retrieval-augmented generation (RAG) pipeline for AI inference, simulating an enterprise use case. This complements new NVIDIA NeMo Retriever microservices, announced today at NVIDIA GTC, which will be available for production-grade AI with the NVIDIA AI Enterprise software suite.
Here’s how it works: NVIDIA GPUs are used for compute and Pure Storage® FlashBlade//S™ provides all-flash enterprise storage for a large vector database and its associated raw data. In this case, the raw data consists of a large collection of public documents, typical of a public or private document repository used for RAG.
RAG improves the accuracy and relevance of LLM inference by providing the model with a vector search lookup of the query against cleaned and vectorized data as inputs (the new and/or proprietary documents). This provides better guidance to the parameters going into the LLM and fine-tunes the output to the user.
The result is increased accuracy, currency, and relevance of LLM inference queries for the organization, making it more useful to the end customer in question-answering and document summarization use cases.
Why RAG with Pure Storage?
Pure Storage FlashBlade//S excels in providing multi-dimensional performance required for demanding RAG workloads, making it an efficient, high-performance shared storage platform to store vector databases, analytics, raw documents for embedding, the AI model, and log data.
Why this matters:
- Cost. In GenAI RAG deployments, as the vector database grows in size beyond tens of millions of vectors, it becomes prohibitively expensive to fit into GPU memory. The alternative is storing the vector database on the server’s local storage; however, enterprises will be limited in performance, efficiency, and scale.
- Performance. When there are multiple document stores and hundreds or thousands of AI users, the RAG-enhanced LLM will run across multiple GPU servers, which need to share scalable storage for both training/embedding and inference/retrieval purposes. A large enterprise GenAI RAG solution will have some servers embedding and indexing new documents and other servers retrieving documents and performing LLM queries simultaneously, which means the storage requires multimodal performance capability to support a constant mix of reads and writes from many servers.
- Scale. Further scaling as data grows is simplified through easy, non-disruptive performance and capacity additions. Naturally, using an enterprise networked storage solution such as Pure Storage FlashBlade//S also provides stronger data protection, better data sharing, easier management, and more flexible provisioning than using local storage within each AI server. It can also provide faster performance when embedding and indexing large document stores.
How Fast Is Fast?
Pure Storage ran scalability tests for GenAI RAG embedding and indexing. Testing across two NVIDIA GPU servers (embedding servers) and two X86 servers (index nodes) compared using local flash storage with the default object storage interface with using one fully populated Pure Storage FlashBlade//S.
We tested three different stages of the document embedding and indexing process:
- Uploading the vector files to the object store
- Bulk insert of vectors into the vector database
- Creation and writing of the index file
Results demonstrated that running the RAG process on two nodes (two servers and two index nodes) was significantly faster than using just one node, highlighting the ability to scale RAG across multiple nodes.
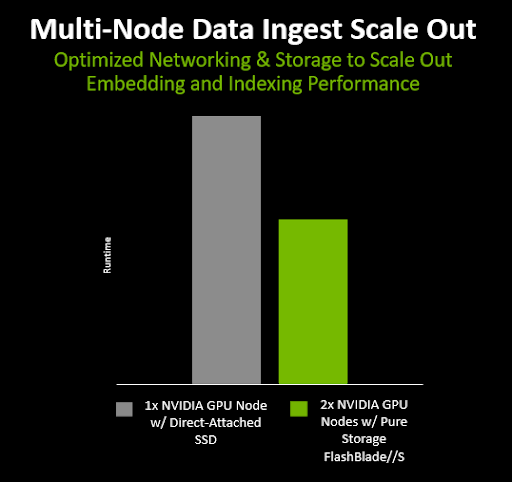
Figure 1: Results from multi-node scale-out testing.
Document embedding and indexing were also completed 36% more quickly when using the Pure Storage FlashBlade//S with a native S3 interface than when using local SSDs that were inside each server, demonstrating that fast networked all-flash storage can help accelerate RAG document embedding.
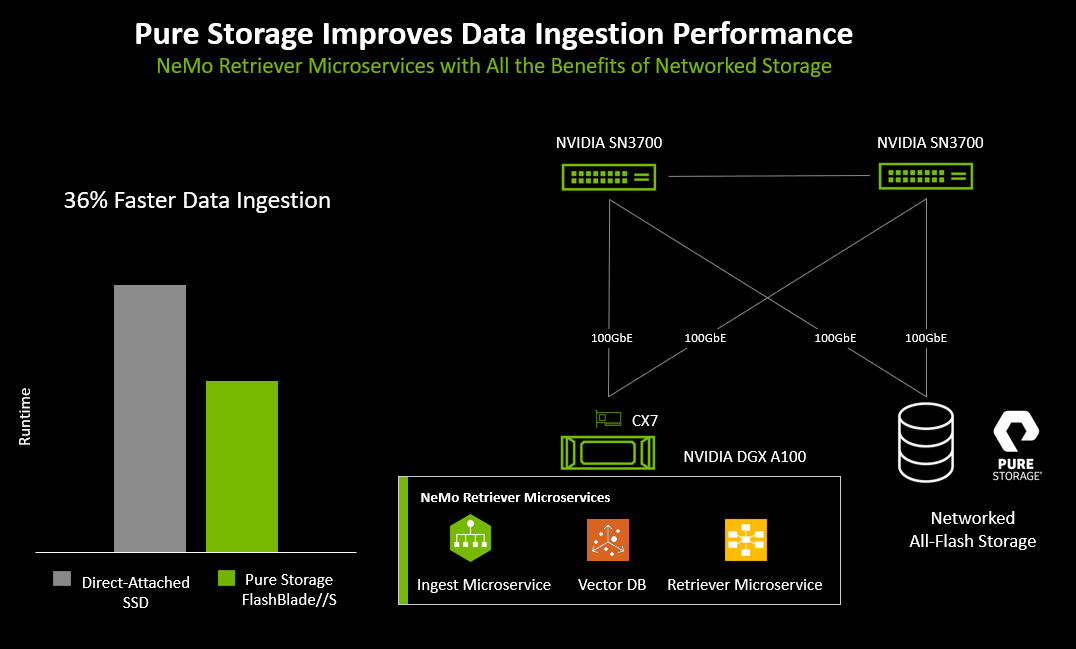
Figure 2: Results from RAG process testing.
Benefits for the Customer
This RAG pipeline demonstrated that the entire document repository can be crunched into a vector database and queried in a matter of seconds with the help of LLM and the RAG pipeline with NVIDIA GPUs, NVIDIA networking, NVIDIA microservices, and Pure Storage FlashBlade//S. This is powerful since the results it returns are based on enriched information inside of the vector database and the generation capabilities of the LLMs.
Pure Storage FlashBlade//S serves as fast and efficient enterprise storage across logging, the vector database, analytics, and raw data with multi-dimensional performance. The ability to add blades of DirectFlash® Modules non-disruptively for increased performance or capacity provides the agility to meet fast-growing requirements of multimodal and real-time streaming data. This makes it the ideal solution for enterprises adding LLM and RAG to their production business processes.
To learn more about how Pure Storage accelerates AI adoption, go to our AI Solution page and reach out to our sales team.

ANALYST REPORT,
Top Storage Recommendations
to Support Generative AI

Written By:



