

Summary
Storage is the backbone of AI, but as model complexity and data intensity increase, traditional storage systems can’t keep pace. Agile, high-performance storage platforms are critical to support AI’s unique and evolving demands.


In the race toward artificial general intelligence (AGI), storage technology is setting the pace. While algorithms and compute take the spotlight, storage powers AI breakthroughs. During the flash revolution, 15K disks stagnated as computational performance doubled every two years, but flash enabled virtualization and, today, GPU-driven workloads are driving further storage innovation alongside demands for efficiency, sustainability, and reliability.
Early AI efforts were limited by algorithmic complexity and data scarcity, but as algorithms advanced, memory and storage bottlenecks emerged. High-performance storage unlocked breakthroughs like ImageNet, which fueled vision models, and GPT-3, which required petabytes of storage. With 400 million terabytes of data generated daily, storage must manage exabyte-scale workloads with sub-millisecond latency to power AGI and quantum machine learning. As AI progressed, each wave of innovation placed new demands on storage, driving advancements in capacity, speed, and scalability to accommodate increasingly complex models and larger data sets.
- Classical machine learning (1980s-2015): Speech recognition and supervised learning models drove data set growth from megabytes to gigabytes, making data retrieval and organization increasingly critical.
- Deep learning revolution (2012-2017): Models like AlexNet and ResNet pushed storage demands, while Word2Vec and GloVe advanced natural language processing, shifting to high-speed NVMe storage for terabyte-scale data sets.
- Foundation models (2018-present): BERT introduced petabyte-scale data sets, with GPT-3 and Llama 3 requiring scalable, low-latency systems like Meta’s Tectonic to handle trillions of tokens and sustain 7TB/s throughput.
- Chinchilla scaling laws (2022): Chinchilla emphasized growing data sets over LLM model size, requiring parallel-access storage to optimize performance.
Storage isn’t just supporting AI—it’s leading the way, shaping the future of innovation by managing the world’s ever-growing data efficiently and at scale. For example, AI applications in autonomous driving rely on storage platforms capable of processing petabytes of sensor data in real time, while genomics research requires rapid access to massive data sets to accelerate discoveries. As AI continues to push the boundaries of data management, traditional storage systems face mounting challenges in keeping pace with these evolving demands, highlighting the need for purpose-built solutions.
How AI Workloads Strain Traditional Storage Systems
Data Consolidation and Volume Management
AI applications manage data sets ranging from terabytes to hundreds of petabytes, far exceeding the capabilities of traditional storage systems like NAS, SAN, and legacy direct-attached storage. These systems, designed for precise, transactional workloads like generating reports or retrieving specific records, struggle with the aggregation-heavy demands of data science and the sweeping, high-speed access patterns of AI/ML workloads. Model training, which requires massive, batched data retrieval across entire data sets, highlights this misalignment. Traditional infrastructure’s rigid architectures, capacity constraints, and insufficient throughput make it ill-suited for AI’s scale and speed, underscoring the need for purpose-built storage platforms.
Performance Bottlenecks for High-speed Data Access
Real-time analytics and decision-making are essential for AI workloads, but traditional storage architectures often create bottlenecks with insufficient IOPS, as they were built for moderate transactional tasks rather than AI’s intensive, parallel read/write demands. Additionally, high latency from spinning disks or outdated caching mechanisms delays data access, increasing time to insight and reducing the efficiency of AI processes.
Handling Diverse Data Types and Workloads
AI systems handle both structured and unstructured data—including text, images, audio, and video—but traditional storage solutions struggle with this diversity. They’re often optimized for structured data, resulting in slow retrieval and inefficient processing of unstructured formats. Additionally, poor indexing and metadata management make it difficult to organize and search diverse data sets effectively. Traditional systems also face performance issues with small files, common in training language models, as high metadata overhead leads to delays and longer processing times.
Legacy Architecture Limitations
The cumulative effect of these challenges is that traditional storage architectures cannot keep pace with the demands of modern AI workloads. They lack the agility, performance, and scalability required to support AI’s diverse and high-volume data requirements. These limitations highlight the need for advanced storage solutions that are designed to handle the unique challenges of AI applications, such as rapid scalability, high throughput, low latency, and diverse data handling.
Key Storage Challenges in AI
AI workloads impose unique demands on storage systems, and addressing these challenges requires advanced capabilities in the following areas:
- Unified data consolidation: Data silos fragment valuable information, requiring consolidation into a unified platform that supports diverse AI workloads for seamless processing and training.
- Scalable performance and capacity: A robust storage platform must manage diverse I/O profiles and scale from terabytes to exabytes, ensuring low-latency, high-throughput access. By enabling non-disruptive scaling, the platform allows AI workloads to expand seamlessly as data demands grow, maintaining smooth, uninterrupted operations.
- Scale-up and scale-out flexibility: Handling low-latency transactional access for vector databases and high-concurrency workloads for training and inference requires a platform that delivers both capabilities.
- Reliability and continuous uptime: As AI becomes critical to enterprises, 99.9999% uptime is essential. A storage platform must support non-disruptive upgrades and hardware refreshes, ensuring continuous operations with no downtime visible to end users.
Optimizing Storage across the AI Pipeline
Effective storage solutions are essential across each stage of the AI pipeline, from data curation to training and inference, as they enable AI workloads to operate efficiently and at scale. AI pipelines require storage that can seamlessly handle latency-sensitive tasks, scale to meet high-concurrency demands, support diverse data types, and maintain performance in distributed environments.
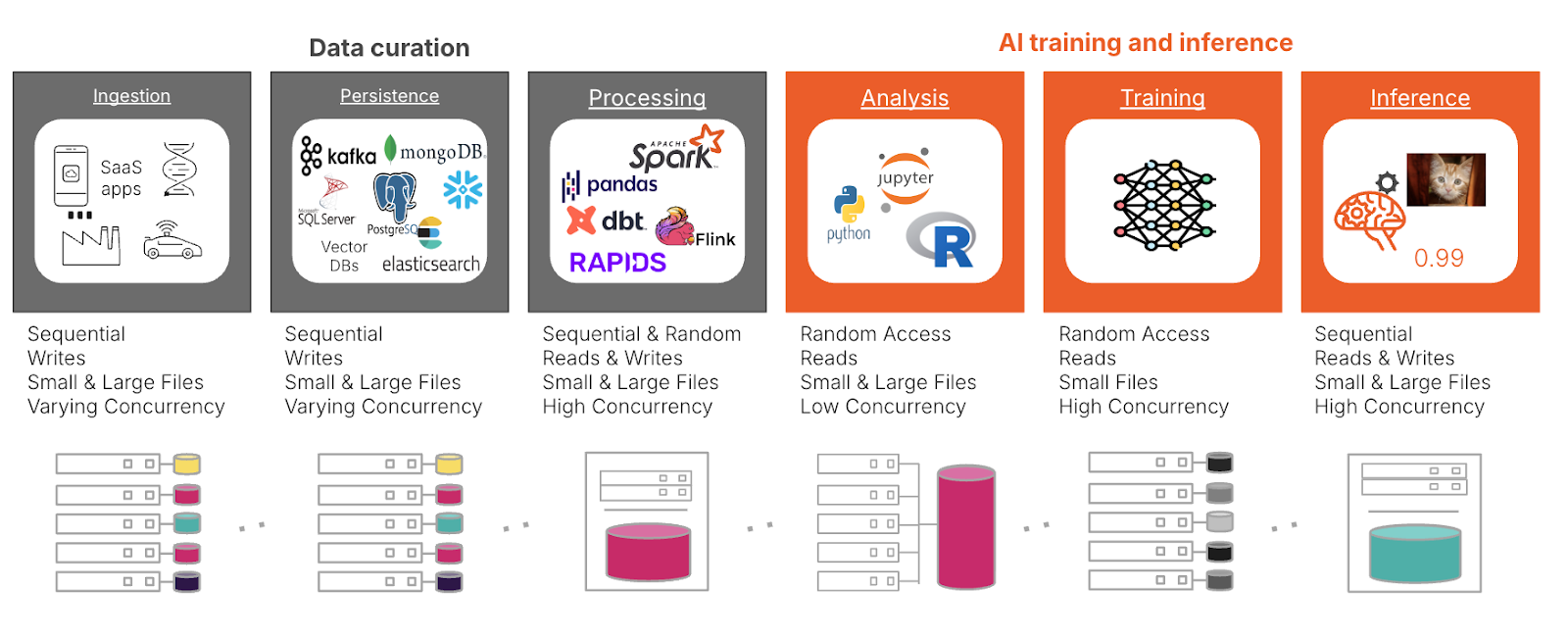
Figure 1: Storage patterns for AI are varied and require a platform built for multi-dimensional performance.
In the data curation stage, managing petabyte-to exabyte-scale data sets begins with ingestion, where storage must scale seamlessly to handle massive data volumes while ensuring high throughput. Real-time applications, such as autonomous driving, require low-latency storage capable of processing incoming data instantly. DirectFlash® Modules (DFMs) excel in these scenarios by bypassing traditional SSD architectures to access NAND flash directly, delivering faster, more consistent performance with significantly reduced latency. Compared to legacy SSDs and SCM, DFMs also offer greater energy efficiency, enabling organizations to meet the demands of large-scale AI workloads while optimizing power consumption and maintaining predictable performance under high concurrency.
During persistence, data storage solutions must support long-term retention and rapid accessibility for frequently accessed data. The processing step is key for preparing data for training, where storage must manage a range of data types and sizes efficiently, handling structured and unstructured data in formats like NFS, SMB, and object.
In the AI training and inference phase, model training generates intensive read/write demands, requiring scale-out architectures to ensure performance across multiple nodes. Efficient checkpointing and version control systems are critical in this stage to avoid data loss. In addition to checkpointing, emerging architectures like retrieval-augmented generation (RAG) present unique challenges for storage systems. RAG relies on efficient retrieval of external knowledge bases during inference, demanding low-latency, high-throughput storage capable of handling concurrent, parallel queries. This places added pressure on metadata management and scalable indexing, requiring advanced storage architectures to optimize performance without bottlenecks.
By aligning storage solutions with the specific needs of each pipeline stage, organizations can optimize AI performance and maintain the flexibility needed to support evolving AI demands.
Conclusion
Storage is the backbone of AI, with increasing model complexity and data intensity driving exponential demands on infrastructure. Traditional storage architectures cannot meet these needs, making the adoption of agile, high-performance storage solutions essential.
The symbiotic relationship between AI and storage platforms means advancements in storage not only support but also accelerate AI progress. For companies just beginning to explore AI, flexibility is crucial: They need storage that can scale as their data and compute needs grow, support multiple formats (e.g., file, object), and integrate easily with existing tools.
Organizations that invest in modern storage platforms position themselves at the forefront of innovation. This requires:
- Assessing infrastructure: Identify current limitations and areas for immediate improvement.
- Adopting scalable solutions: Implement platforms that offer flexibility, high performance, and seamless growth.
- Planning for future needs: Stay ahead of emerging trends to ensure the platform evolves with AI developments.
By prioritizing storage platforms as a core component of AI strategy, organizations can unlock new opportunities, drive continuous innovation, and maintain a competitive edge in the data-driven future.
Want to learn more?
Visit the AI solutions page
Watch the webinar replay: “Considerations for an Accelerated Strategic Enterprise AI Infrastructure“
Download the white paper: “The Pure Storage Platform for AI”

ANALYST REPORT,
Top Storage Recommendations
to Support Generative AI

A Game-changer for AI
Accelerate your AI initiatives with the Pure Storage platform.



