A recent HBR Analytics Services research report shows that more than 51% of enterprises plan to leverage multicloud. If you dig into the numbers, you’ll find that block-based workloads for databases, Microsoft Exchange, RAID, and virtual machines account for the bulk of cloud use. These workloads are also increasing on AWS, Azure, and GCP, with disaster recovery (DR) workloads making up the largest part of that growth. Read on to learn more about cloud block storage for disaster recovery.
Recent research shows that the replacement of DR sites is the primary driver of public cloud storage usage. Most companies have compliance requirements (either internal or contractual), and the KPIs are recovery point objectives (RPO), recovery time objectives (RTO), and data integrity. Many service-oriented companies have client service-level agreements (SLAs) for an RTO of 24 hours, and a few have requirements of one hour. They also face government regulations such as General Data Protection Regulation recovery(GDPR), under which companies could incur fines if they fail to protect certain types of sensitive data, including the personal data of customers.
Disaster recovery is just one part of a business-continuity and lifecycle data-management strategy that also includes data protection, real-time replication, and failover. In a survey conducted by Gartner¹, 76% of companies reported an incident during the past two years that required an IT DR plan, while more than half reported at least two incidents.
For mission-critical IT services, storage-based replication remains the most common data-protection mechanism. Asynchronous replication is a forward-looking approach to data backup and data protection, primarily because you can use it for cloud backups. Compared to synchronous replication, asynchronous replication offers two main advantages:
- A lower bandwidth and host IO latency requirement
- The ability to work over very long distances. Since the replication process doesn’t have to occur in real time, asynchronous replication can tolerate some degradation in connectivity.
You have many choices when it comes to data protection, traditional on‑premises infrastructure (i.e., backup/recovery with tape or backup appliances), or cloud‑based services (i.e., backup-as-a-service, archive as-a-service, and disaster-recovery-as-a-service). IDC estimates that more than 80% of companies use cloud services for some portion of their data-protection strategy, and with good reason.
There are four key reasons why the cloud is an ideal DR option for block-based workloads:
- Availability: Cloud providers have multiple regional availability zones (AZ) on different tectonic plates and flood zones. Internal or client compliance requirements often require multiple AZs to comply with government regulations.
- Agility: It’s easy to update data clones and correspondingly scale storage on demand.
- Total Cost of Ownership (TCO): Many organizations realize TCO savings from cloud resources through CAPEX avoidance and scalability.
- Automation: By leveraging cloud resources, organizations can realize highly automated offsite recovery capabilities.
Business continuity is a category closely related to DR; in fact, some analysts believe the categories have merged. Unplanned downtime affects your business, as well as your customers. IDC estimates that on average, businesses could realize up to $571,000 in revenue by avoiding business interruptions. DR and business continuity both require multiple AZs and tight RTO/RPO thresholds to reduce the risk of downtime and data loss, while ensuring a fast recovery.
Pure Cloud Block Store™, part of the FlashArray™ product family, addresses these requirements. Pure Cloud Block Store provides an abstraction layer with consistent APIs that enables applications to be agnostic to the on-premises or cloud environment on which they run. Currently the solution is available on AWS and is in beta on Azure.
During a DR-failover event, you can use a replicated-snapshot volume on Pure Cloud Block Store to instantaneously clone data and attach to the respective application hosts in the public cloud. The asynchronous-replication technology results in an efficient cloud footprint with data that is deduplicated, thin-provisioned, and compressed. For protection against a single AZ or regional failure, Pure Cloud Block Store can replicate its own source volumes to other Pure Cloud Block Store instances.
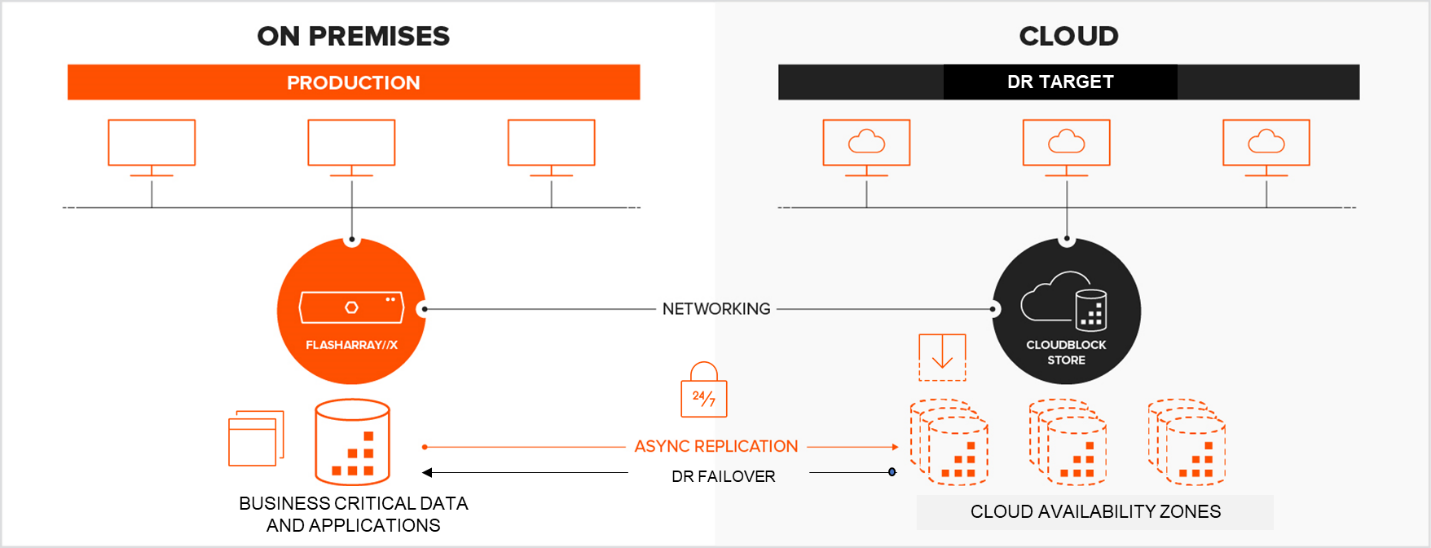
Pure Cloud Block Store enables you to keep clones in sync with production data, and its always-on encryption, combined with cloud-native cybersecurity, and provides a compliant solution preserving data integrity. Cost efficiency is an important consideration in any DR discussion, and our industry-leading data-storage efficiencies, thin provisioning, deduplication, and compression techniques mean your data consumes significantly less cloud-storage infrastructure than in native-cloud storage options.
The solution also offers space-efficient and performant snapshots, which don’t consume additional storage. You can create multiple copies of your data in a cost-effective and performant way and take thousands of snapshots without incurring additional costs.
Whether you’re investing in a disaster insurance policy or looking for revenue upside, you’ll likely find that replication to the cloud results in a positive business outcome.
Learn more about the benefits of Pure Cloud Block Store.
- Gartner Survey Analysis: IT Disaster Recovery Trends and Benchmarks